6. Описание технических решений
6.1. Задачи реализованных технических решений
Технические решения, реализованные в рамках работ по разработке и модернизации программы, решают следующие задачи:
Описание логической модели данных.
Загрузка и хранение данных.
Извлечение данных из внешних систем.
Поддержка языка SQL.
Поддержка протокола коммуникации агента ПОДД.
Подключение к СМЭВ3 как информационной системы участника взаимодействия.
Обработка запросов с использованием стандарта JDBC.
Публикация конечных точек API для обработки запросов с использованием спецификации OpenAPI версии 3.
Восстановление данных в непротиворечивое состояние после сбоев.
Журналирование событий функциональных блоков.
Мониторинг информации о работоспособности экземпляра Программы.
Работа с BLOB-полями.
Формирование, подписание и передачи через ПОДД формирования докуметов.
Предоставление оценки объема запрашиваемых ПОДД данных.
Управление взаимодействием со СМЭВ3.
Запись событий в журнал и конфигурирование количества соединений к ProStore для СМЭВ3.
Использование табличных параметров в запросах через ПОДД и выделение функций в отдельные модули.
Пакетная загрузка больших объемов данных при первичном наполнении витрины;
Совместимость Типового ПО «Витрина данных» на серверах с предустановленной операционной системой Astra Linux, РЕД ОС, АЛЬТ Сервер 8 СП.
6.2. Описание технических решений
6.2.1. Описание логической модели данных
6.2.1.1. Задача «Создание логической модели данных «ЕИП НСУД – Поставщик данных»
Задача представляет собой возможность создания логической модели данных в ЕИП НСУД и ее последующую выгрузку в Витрину поставщика данных.
Результатом решения данной задачи, представлен процесс выполнения следующих действий см. Рисунок - 6.44:

Рисунок - 6.44 Создание логической модели данных «ЕИП НСУД – Поставщик данных»
В ЕИП НСУД создается логическая модель данных для Витрины поставщика данных.
ЕИП НСУД отправляет модель через ПОДД в Агент ПОДД.
Агент ПОДД, через ПОДД-адаптер передает модель в Витрину данных, в которой создается логическая модель данных.
6.2.1.2. Задача «Создание логической модели данных «Внешняя ИС – Поставщик данных»
Задача представляет собой возможность создания логической модели данных в Витрине данных поставщика средствами Внешней ИС. В качестве Внешней ИС может выступать любое ПО, способное:
Использовать JDBC-драйвер для подключения к Витрине данных.
Через JDBC-драйвер выполнять SQL-запросы к Витрине данных для создания логической модели данных.
Внешняя ИС напрямую подключается к Витрине данных Поставщика данных.
В этом случае процесс выглядит следующим образом см. Рисунок - 6.45
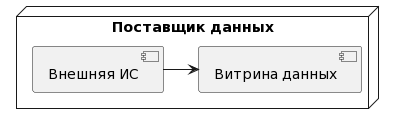
Рисунок - 6.45 Создание логической модели данных «Внешняя ИС – Поставщик данных»
6.2.1.3. Задача «Создание логической модели данных «ЕИП НСУД – Потребитель данных»
Задача представляет собой возможность создания логической модели в Витрине потребителя данных в случае подписания его в ЕИП НСУД на репликацию данных (предоставляемых Поставщиком данных). В этом случае процесс в части, касающейся создания логической модели данных, выглядит следующим образом см. Рисунок - 6.46
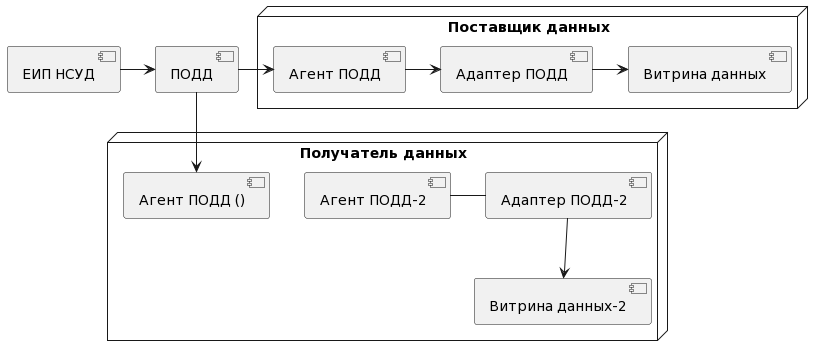
Рисунок - 6.46 Создание логической модели данных «ЕИП НСУД – Потребитель данных»
В ЕИП НСУД регистрируется подписка на репликацию.
ЕИП НСУД через ПОДД и Агент ПОДД отправляет подписку на репликацию в Витрину Поставщика данных и в ответ от Витрины получает структуру данных.
ЕИП НСУД через ПОДД и Агент ПОДД отправляет в Витрину Потребителя данных структуру таблиц.
Витрина Потребителя данных создает у себя таблицы для хранения реплицируемых данных.
6.2.1.4. Задача и методы решения
Задача включает возможность описания логической модели данных.
Для решения задачи формирования логической модели данных применяются метод обработки данных в виде реляционной модели. С возможностью поддержки следующих аспектов модели:
схема;
таблица;
столбцы;
уникальные ключи (первичные и альтернативные);
внешние ключи;
индексы;
типы данных.
При реализации указанного метода программа поддерживает возможность обработки SQL-запросов:
SQL+ DDL. Поддерживаются инструкцииCREATE/DROP DATABASE,CREATE/DROP TABLE,CREATE/DROP VIEW.SQL+ EDDL. Поддерживаются инструкцииCREATE/DROP DOWNLOAD EXTERNAL TABLE,CREATE/DROP UPLOAD EXTERNAL TABLE.Формирование логической модели с использованием типов:
BOOLEAN,INT,BIGINT,FLOAT,DOUBLE,VARCHAR,UUID,DATE,TIME,TIMESTAMP.
6.2.2. Загрузка и хранение данных
Задача включает возможность загрузки и хранения данных подготовленных в соответствии с предварительно сформированной логической моделью данных.
Загрузка данных, представляет собой часть процесса:
ETL (см. раздел Извлечение данных из внешних систем);
ПОДД (при создании реплики и получении дельты см. раздел Поддержка протокола коммуникаций Агента ПОДД).
Для решения задачи применяются метод обработки данных в соответствии с форматом данных, используемый для загрузки (основанным на открытом формате с типизацией атрибутов).
При реализации этого метода обработки данных программа предоставляет возможность:
Загрузки и хранения данных.
Версионирование загружаемых данных на уровне записей.
Создание первичных ключей записей, которые уже были загружены ранее
Создание новой версии записи.
Возможность загрузки и хранения логической модели данных описано в разделе Описание логической модели данных.
6.2.3. Извлечение данных из внешних систем
6.2.3.1. Задача «Извлечение и преобразование данных из внешних ИС»
Задача представляет собой возможность извлечения и преобразования данных из Внешних ИС (внешних по отношению к Витрине данных НСУД) и загрузку обработанных данных в Витрину данных.
Извлечение данных из внешних информационных систем состоит из трех этапов см. Рисунок - 6.47:
Извлечение данных.
Преобразование данных.
Загрузка данных в «Витрину данных НСУД» (см. раздел 3.2.2).
Процесс обработки данных реализован с помощью массивно-параллельной архитектуры, при которой данные разделяются на фрагменты и обрабатываются независимыми центральными процессами. При этом в ETL сохраняются версии полученных данных см. Рисунок - 6.47
Рисунок - 6.47 Извлечение и преобразование данных из внешних ИС
Общая схема процесса извлечения, преобразования и загрузки данных в витрину выглядит следующим образом см. Рисунок - 6.48
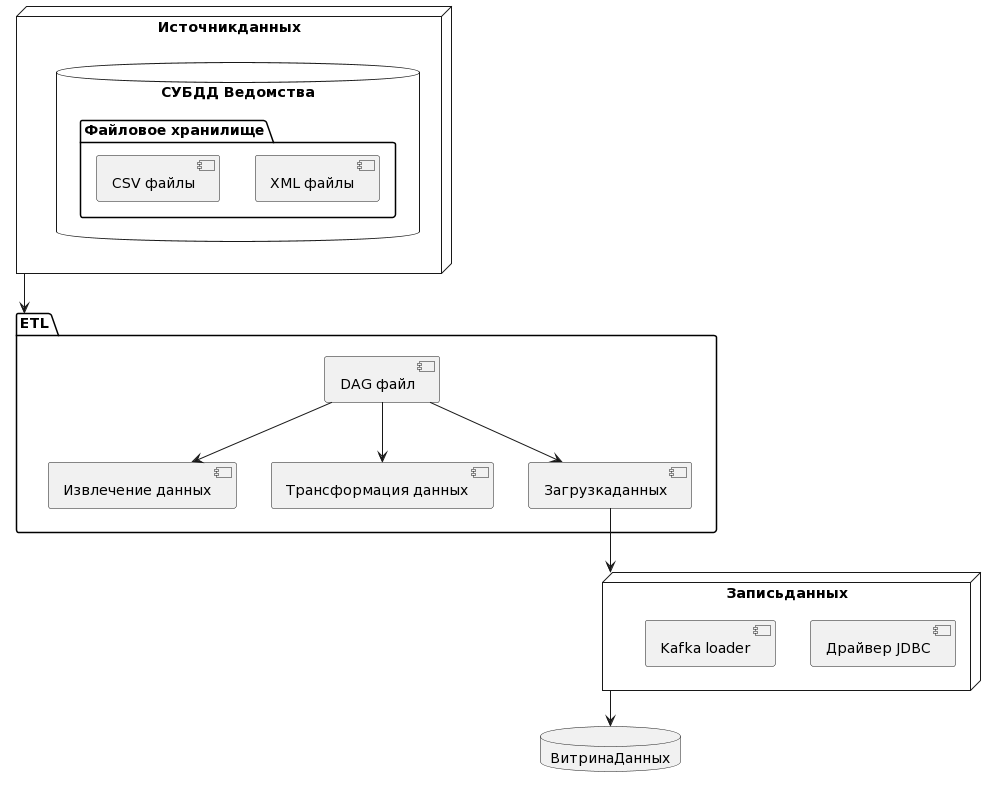
Рисунок - 6.48 Схема обработки данных из внешних систем
В результате решения данной задачи создан следующий процесс обработки данных:
ETL извлекает информацию из:
Загружает файлы выложенные в файловом хранилище ведомства (формат
xmlиcsv).
Полученные данные обрабатываются в ETL (см. Рисунок - 6.48), в соответствии с настроенными правилами обработки данных (последовательность и правила обработки данных настраиваются в DAG-файле).
Обработанные данные загружаются в Kafka-loader.
Через JDBC-драйвер происходит загрузка данных в Витрину данных. Например, передается SQL-запрос на создание в Витрине данных таблиц и наполнением их данными из выбранных топиков Kafka-loader.
6.2.3.2. Задача и методы решения
Задача включает следующие действия:
Чтение данных из внешних (по отношению к «Витрине данных НСУД») источников с использованием стандарта JDBC и языка SQL.
Чтение данных из файлов формата:
csv;xml.Трансформация данных, согласно заложенной логической модели данных и сохранение трансформированных данных в Программы. -при реализации указанного метода программа выполняет следующие основные операции:
предоставление программного интерфейса для получения данных из внешних источников;
трансформация и сохранение данных;
получение от программиста управляющих воздействий для:
обработки и трансформации данных;
сохранение информации о выданных управляющих воздействиях в лог-файле;
выдача программным средствам управляющих воздействий для возможности чтения данных из файла
xml,csv;выдача программным средствам управляющих действий для трансформации данных и сохранения трансформированных данных, в соответствии с описанной логической моделью данных.
6.2.4. Поддержка языка SQL
6.2.4.1. Задача «SQL-запрос через ПОДД»
Задача представляет собой возможность отправки SQL-запросов на получение данных от Внешней ИС через ПОДД в Витрину Поставщика данных.
В результате решения данной задачи создан процесс обработки данных, который выглядит следующим образом см. Рисунок - 6.49
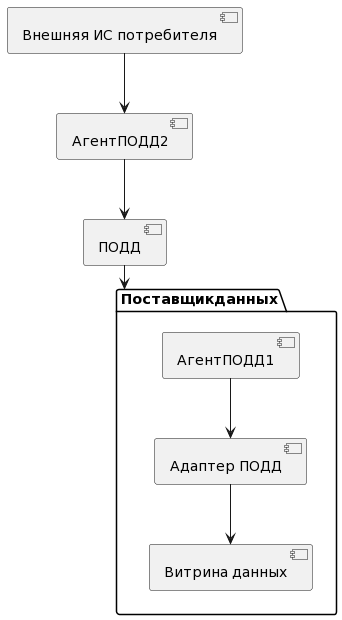
Рисунок - 6.49 SQL-запрос через ПОДД
Внешняя ИС формирует SQL-запрос и отправляет его через Агент ПОДД.
SQL-запрос доставляется из ПОДД в Агент ПОДД Поставщика данных.
Агент ПОДД на стороне Поставщика данных принимает запрос и отправляет его в Витрину данных через ПОДД-адаптер.
В Витрине данных формируется ответ на SQL-запрос (он отправляется по описанной цепочке в обратном направлении).
6.2.4.2. Задача «SQL-запрос через СМЭВ 3»
Задача представляет собой возможность отправки SQL-запросов на получение данных от Внешней ИС через СМЭВ3 в Витрину Поставщика данных
В результате решения данной задачи создан процесс обработки данных, который выглядит следующим образом см. Рисунок - 6.50

Рисунок - 6.50 SQL-запрос через СМЭВ 3
Внешняя ИС формирует SQL-запрос и отправляет его через CМЭВ3-адаптер в СМЭВ 3.
SQL-запрос доставляется из СМЭВ 3 в CМЭВ3-адаптер Поставщика данных.
CМЭВ3-адаптер на стороне Поставщика данных принимает запрос и отправляет его в Витрину данных.
В Витрине данных формируется ответ на SQL-запрос (он отправляется по описанной цепочке в обратном направлении).
6.2.4.3. Задача «Прямой SQL-запрос от Внешней ИС»
Задача представляет собой возможность выполнения SQL-запроса непосредственно от Внешней ИС к Витрине данных.
В результате решения данной задачи создан процесс обработки данных, который выглядит следующим образом см. Рисунок - 6.51

Рисунок - 6.51 Прямой SQL-запрос из Внешней ИС
Внешняя ИС формирует SQL-запрос.
Внешняя ИС отправляет запрос непосредственно в Витрину данных.
6.2.4.4. Задача и методы решения
Задача включает следующие действия:
поддержка языка SQL.
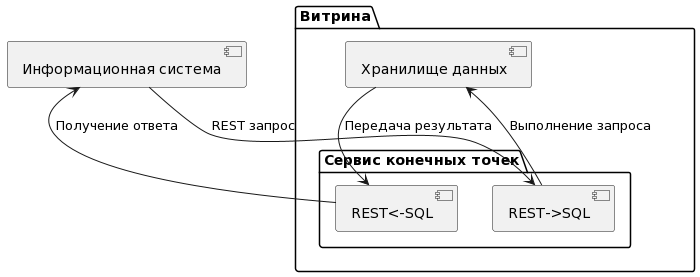
Рисунок - 6.52 Выполнение SQL-запросов в программеВыполнение SQL-запросов в программе
Для решения задачи применяются методы:
метод обработки данных.
При реализации указанного метода программа выполняет следующие основные операции при обработке данных:
Использование
SQL``+ ``DMLкак базовый способ доступа к данным в экземпляр Программы. Поддерживаются инструкцииSELECTиUSE.Запрос к архивным состояниям, идентифицируемым номером или датой загруженного пакета, с использованием SQL-инструкции
FOR SYSTEM\_TIME AS OF.Использование
SQL``+ ``EDMLкак способ доступа к данным в экземпляре Программы. Поддерживаются инструкцииUPLOADиDOWNLOAD.
Получение данных для Внешних ИС возможно выполнить с помощью:
SQL-запрос через ПОДД.
SQL-запрос через СМЭВ.
Прямой SQL-запрос к Поставщику данных.
6.2.5. Поддержка протокола коммуникаций Агента ПОДД
6.2.5.1. Задача «Поддержка протокола коммуникации ПОДД»
Задача представляет собой возможность поддержки Витриной данных протокола коммуникации Агент ПОДД.
Для решения задачи был разработан ПОДД-адаптер, в котором была реализована возможность обмена сообщениями с Агент ПОДД через заранее согласованные топики (службы обмена сообщениями Apache Kafka) .
В результате решения задачи Витрина данных имеет возможность взаимодействовать через Агент ПОДД и решать следующие задачи:
настраивать логическую модель хранимых данных;
регистрировать подписку на репликацию данных;
принимать и сохранять реплицируемые из других Витрин данные;
предоставлять хранимые данные по запросам Потребителей данных.
Результатом решения задачи, стал следующий процесс:
Получатель данных отправляет через ПОДД запрос к Витрине данных.
Запрос поступает в Агент ПОДД.
ПОДД-адаптер (через заранее согласованные топики обмена сообщениями) получает запрос от Агента ПОДД на предоставление данных.
ПОДД-адаптер обрабатывает запрос и отправляет его в Витрину данных.
Витрина данных обрабатывает запрос и формирует на него ответ в ПОДД-адаптер.
ПОДД-адаптер обрабатывает ответ, записывает результат в заранее согласованные топик обмена сообщениями и предоставляет ответ Агенту ПОДД.
Агент ПОДД отправляет полученный ответ через ПОДД Получателю данных.
6.2.5.2. Задача и методы решения
Задача включает следующие действия:
обработка поступающих запросов от ПОДД.
Для решения задачи применяются методы:
метод обработки данных;
метод межведомственного взаимодействия.
При реализации указанного метода программа выполняет следующие основные операции при обработке данных:
Поддержка протокола коммуникации агента ПОДД, устроенного в виде обмена сообщениями через заранее согласованные топики службы обмена сообщениями Apache Kafka.
Регистрация реплицируемого набора данных на стороне поставщика данных.
Создание и хранение актуальных копий данных витрин поставщиков на стороне потребителя данных (создание и сохранение копий происходит путем взаимодействия с Агентом ПОДД через протокол коммуникаций).
Формирование по запросу инкремента реплицируемого набора данных на стороне Поставщика данных.
Чтение данных из реплик с использованием SQL на стороне потребителя данных.
Вычисление по запросу от ПОДД контрольных сумм данных, представляющих собой результат запроса.
Инкрементальная загрузка данных реплики от Агента СМЭВ на стороне потребителя.
6.2.6. Подключение к СМЭВ3 как информационной системе участника взаимодействия
6.2.6.1. Задача «Подключение к СМЭВ 3»
Задача представляет собой возможность взаимодействия с «Витринной данных НСУД» через СМЭВ3.
Внешняя ИС выполняет запрос к СМЭВ 3 на получение данных от Поставщика данных.
Запрос через CМЭВ3-адаптер отправляется в СМЭВ 3.
CМЭВ3-адаптер на стороне Поставщика данных принимает запрос из СМЭВ 3 и отправляет его в Витрину данных поставщика.
В Витрине данных Поставщика формируется ответ на поступивший запрос.
6.2.6.2. Задача и методы решения
Задача включает возможность информационного взаимодействия через систему межведомственного электронного взаимодействия (СМЭВ), в соответствии с Методическими рекомендациями по работе с системой межведомственного электронного взаимодействия версии 3.ХХ.
Задача включает следующие действия:
подключение к СМЭВ;
обмен данными.
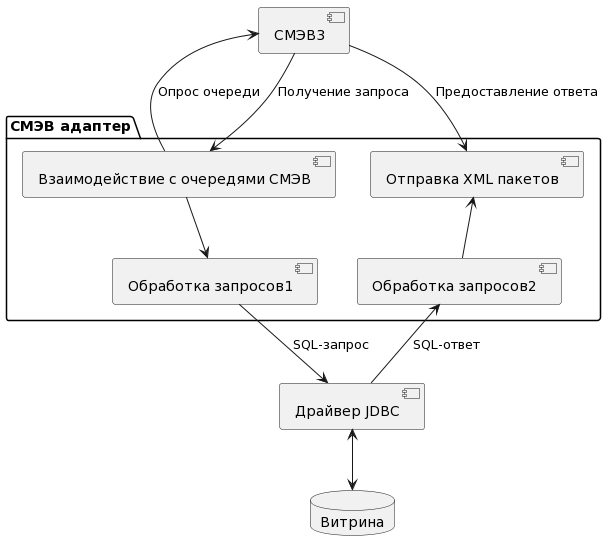
Рисунок - 6.53 Схема подключения к СМЭВ3
Для решения задачи применяются методы:
метод обработки данных;
метод межведомственного взаимодействия.
При реализации указанного метода программа выполняет следующие основные операции по обработке данных:
загрузка запросов из очереди ИС УВ (Информационная система Участника Взаимодействия) в СМЭВ 3;
формирование и отправку ответов в СМЭВ 3;
инициативное формирование уведомлений об изменении данных в экземпляре Программы и отправку уведомлений в СМЭВ 3 в соответствии с описанием вида сведений, разработанным для формирования таких уведомлений;
поддержка конфигурирования, которое предоставляет возможность использовать атрибуты запросов СМЭВ 3 для того, чтобы:
формировать и выполнять SQL-запросы к программе;
формировать и отправлять ответы на SQL-запросы в очередь ответов СМЭВ.
6.2.7. Обработка запросов с использованием стандарта JDBC
6.2.7.1. Задача «Обработка запросов с использованием стандарта JDBC»
Задача представляет собой возможность подключения к БД «Витрины данных НСУД» с использованием стандарта JDBC.
Подключение происходит через JDBC-драйвер, который используется как для создания соединения с БД, так и последующего взаимодействия между Поставщиком и Получателем данных.
Подключение через JDBC-драйвер к БД «Витрины данных НСУД» используется в следующих компонентах программы:
CМЭВ3-адаптер.
ETL.
В результате подключения к Витрине данных, Получатель данных имеет возможность отправлять прямые SQL-запросы к БД «Витрины данных НСУД и получать на них ответы.
Результатом решения задачи, стал следующий процесс:
Получатель данных загружает и устанавливает JDBC-драйвер.
JDBC-драйвер устанавливает соединение с БД Поставщика данных.
Получатель данных создает SQL-запрос на получение данных.
JDBC-драйвер отправляет запрос в БД Витрины данных.
Витрина данных обрабатывает запрос и формирует на него ответ.
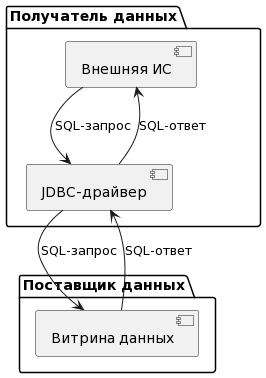
Рисунок - 6.54 Обработка запросов с использованием стандарта JDBC
6.2.7.2. Задача и методы решения
Задача включает следующие действия:
обработка запросов с использованием стандарта JDBC.
Для решения задачи применяются методы:
метод обработки данных;
При реализации указанного метода программа выполняет следующие основные операции для обработки данных:
Отправка запросов к Программе в соответствии со стандартом JDBC.
JDBC-драйвер поддерживает следующие SQL-запросы:
CREATE/DROP DATABASE
CREATE/DROP/ALTER TABLE
CREATE/DROP/ALTER VIEW
BEGIN/COMMIT/ROLLBACK DELTA
SELECT
USE
CREATE/DROP DOWNLOAD EXTERNAL TABLE
CREATE/DROP UPLOAD EXTERNAL TABLE
UPLOAD
DOWNLOAD
6.2.8. Публикация конечных точек API для обработки запросов с использованием спецификации OpenAPI версии 3
6.2.8.1. Задача «Подключение Внешней ИС через Сервер конечных точек (REST-адаптер)»
Задача представляет собой возможность подключения Внешней ИС к Витрине данных через REST-адаптер.
Внешняя ИС формирует REST-запрос и отправляет его в REST-адаптер.
На основании своих настроек преобразует полученный REST-запрос в SQL-запрос.
Отправляет сформированный SQL-запрос в Витрину данных.
Преобразует полученный от Витрины данных ответ на SQL-запрос в REST-ответ.
Отправляет сформированный REST-ответ Внешней ИС.
6.2.8.2. Задача и методы решения
Задача включает следующие действия:
публикация конечных точек API для обработки запросов с использованием спецификации OpenAPI версии 3.
Для решения задачи применяются методы:
метод обработки данных;
метод публикации данных в формате API (спецификация OpenAPI версии 3).
При реализации указанного метода программа выполняет следующие основные операции по обработке данных:
предоставляет программный интерфейс к конечным точкам API по протоколу HTTP.
конечная точка доступа поддерживает конфигурирование, которое позволяет:
с использованием атрибутов HTTP-запроса построить и выполнить SQL-запросы из Внешней ИС к программе;
с использованием атрибутов HTTP-запроса и результатов SQL-запросов построить и отправить ответ на HTTP-запрос из программы к Внешней ИС;
документировать сконфигурированный API с использованием спецификации OpenAPI версии 3.
6.2.9. Восстановление данных в непротиворечивое состояние после сбоев
Задача представляет собой возможность восстановления и контроля целостности данных после сбоев.
В рамках решения задачи установлены возможные точки нарушения целостности данных:
При загрузке данных в Витрину данных.
При загрузке данных в ETL.
При репликации через ПОДД (репликации данных между ведомствами).
В рамках решения задачи разработаны два метода контроля за консистентными данными, которые дополняют друг друга:
Метод контроля дельты, в этом случае непротиворечивость данных контролируется тем, что все транзакции (дельты), которые были завершены в процессе выполнения репликации или загрузке данных в Витрину данных, применяются, а все транзакции, которые не были завершены, например, при сбое оборудования, считаются не консистентными и подвергаются откату (восстановлению) до актуальной синхронизированной дельты.
Контроль дельты, вычисляется хэш-функцией использующей алгоритм MD5 для всей дельты. При передаче данных через Kafka дельта может делиться на несколько пакетов. В последнем пакете при передаче от Поставщика данных к Получателю передается контрольная хэш-сумма дельты. После получения последнего пакета происходит сравнение хэш-суммы переданных пакетов и контрольной хеш-суммы всей дельты. Если суммы не совпадают, то передача дельты полностью отменяется.
Метод контроля передачи пакетов Kafka, в этом случае поврежденный пакет не сможет десериализоваться т.к. в каждом пакете передается схема данных по которой проверяются данные.
Актуальное состояние дельты контролируется хэш-суммой состояния данных.
При реализации указанных методов программа выполняет следующие основные операции:
поддержка топологии кластеров БД, включающей в себя в том числе определение правил репликации и степени избыточности.
контроль состава и целостность загружаемой дельты перед началом ее загрузки.
загрузка дельт происходит строго последовательно – новая дельта строго после подтверждения загрузки предыдущей.
перенос данных из вспомогательных таблиц в таблицы данных и перенос старых записей в таблицу истории происходит в рамках одной транзакции.
6.2.10. Журналирование событий функциональных блоков
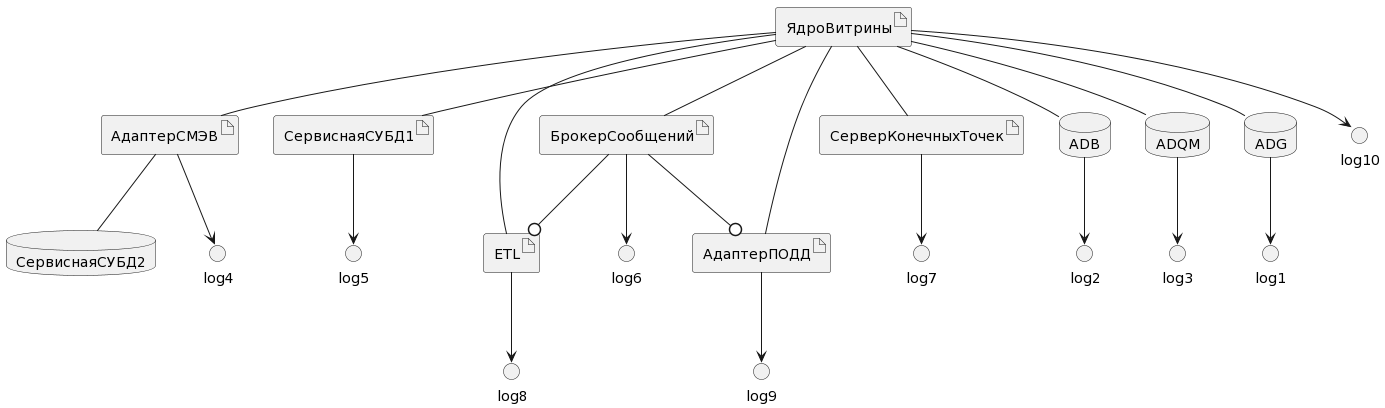
Рисунок - 6.55 Мониторинг и журналирование событий в системе
Задача включает следующие действия:
журналирование событий функциональных блоков:
Ядро витрины (Prostore);
Брокер сообщений;
Сервисная СУБД;
ADCM;
CМЭВ3-адаптер (включает собственную сервисную БД); :
ETL;
Для решения задачи применяются методы:
метод обработки данных;
метод журналирования событий.
При реализации указанного метода программа выполняет следующие основные операции по обработке данных:
запись системных событий (отдельно по каждому функциональному блоку) осуществляется в лог-файлы ( см. Рисунок - 6.55 ).
предоставление возможности просмотра журнала событий (лог-файла).
Инструкция о порядке просмотра лог-файлов описана в «Руководстве оператора».
Настройку детализации лог-файлов осуществляет системный программист.
6.2.11. Мониторинг информации о работоспособности экземпляра Программы
Задача включает следующие действия:
Мониторинг информации о работоспособности экземпляра Программы.
Для решения задачи применяются методы:
метод обработки данных;
метод журналирования событий.
метод комплексного сбора данных о занятости вычислительных ресурсов по каждому серверу и их последующему анализу.
При реализации указанного метода программа выполняет следующие основные операции:
Предоставляет возможность контроля за рекомендуемыми метриками.
Рекомендуемые для отслеживания метрики контроля работоспособности программы приведены ниже:
Сеть
Переданные пакеты/байты
Ошибочные/отброшенные пакеты
Коллизии
CPU
Load average (усредненная загрузка)
Простой/использование CPU
Данные утилизации CPU по отдельным процессам
Память
Свободная/использованная память
Утилизация swap/файла подкачки
Диск
Свободное/занятое дисковое пространство
I/O чтения и записи
Служба
Состояние процесса
Использование памяти процессом
Состояние службы (ssh, ntp, ldap, smtp, ftp, http, pop, nntp, imap)
Разрешение DNS
Работоспособность TCP
Время ответа TCP
Файл
Размер/время файла
Существование файла
Контрольная сумма
MD5 хеш
Поиск по регулярному выражению
Журнал
Текстовый журнал
Другое
Время работы системы
Системное время
Подключенные пользователи
Мониторинг осуществляется методом просмотра лог-файлов следующих компонентов «Витрины данных НСУД» ( см. Рисунок - 6.55 )
Ядро витрины (Prostore);
Брокер сообщений (ADS);
Сервисная СУБД;
ADCM;
ETL;
CМЭВ3-адаптер (включает собственную сервисную БД);
Расположение и относительные пути к лог-файлам описаны в документе «Руководство системного программиста», раздел 7.2 «Логирование».
Периодичность обновления значений метрик и их пороговые значения определяются при внедрении и корректируется в процессе последующей эксплуатации программы, в соответствии с пороговыми значениями нагрузки.
6.2.12. Работа с BLOB-объектами
Для работы с BLOB-объектами в ProStore был добавлен новый тип данных –
LINK. Он позволяет сохранять в БД ссылки на файлы, хранимые во внешнем
(по отношению к Программе) Хранилище BLOB-объектов, содержащие бинарные данные
BLOB-объектами.
Реализация нового процесса по работе с BLOB-объектами, предоставляющего возможность передачи файлов большого объема из Программы в ИС-потребители через ПОДД приведена на рисунке ниже.
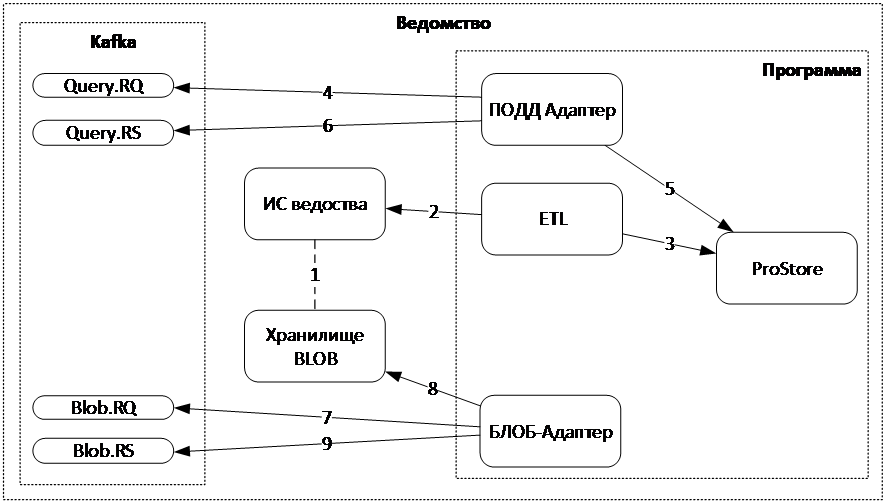
Рисунок - 6.56 Работа с BLOB-объектами через ПОДД
ИС ведомства, предоставляющая публикуемые данные Программе, должна иметь в том числе связь публикуемых данных с файлами своего Хранилища BLOB-бъектов, которые должны представляться в БД ProStore в виде объектов.
ETL-процесс, выстраиваемый на этапе внедрения Программы на стороне ведомства-источника данных, при загрузке публикуемых данных из ИС ведомства должен получать собственно публикуемые данные и ссылки на файлы Хранилища BLOB-объектов.
ETL-процесс записывает в ProStore публикуемые данные и ссылки на файлы Хранилища BLOB-объектов.
Модуль «ПОДД-адаптер» считывает запросы на предоставление публикуемых данных из топика Kafaka (query.rq).
Модуль «ПОДД-адаптер» отправляет полученный запрос данных на исполнение в ProStore.
Модуль «ПОДД-адаптер» записывает в топик Kafka (query.rs) запрошенные данные (в том числе и ссылки на файлы Хранилища BLOB-объектов, записанные в поля типа
LINK).Если потребитель данных, получивший запрошенные данные, желает получить бинарное содержимое BLOB-объектов, то он самостоятельно направляет запрос на предоставление содержимого BLOB-объекта, передавая в нем полученное содержимое поля типа
LINK. Такие запросы в Программу на стороне поставщика данных доставляются в специальный топик Kafka (blob.rq).Модуль «BLOB-адаптер» считывает запрос из топика Kafka (blob.rq).
Модуль «BLOB-адаптер» преобразует полученную ссылку из поля
LINKв запрос на считывание файла к Хранилищу BLOB-объектов.Модуль «ПОДД-адаптер» отправляет содержимое считанного файла в топик Kafka (blob.rq).
Реализация нового процесса по работе с BLOB-объектами, предоставляющего возможность передачи файлов большого объема из Программы в ИС-потребители через СМЭВ3 приведена на рисунке ниже.
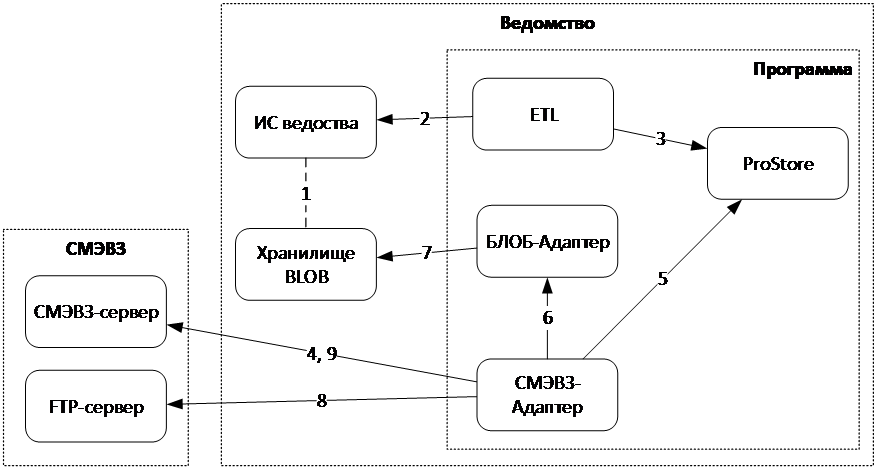
Рисунок - 6.57 Работа с BLOB-объектами через СМЭВ3
ИС ведомства, предоставляющая публикуемые данные Программе, должна иметь в том числе связь публикуемых данных с файлами своего Хранилища BLOB-объектов, которые должны представляться в БД ProStore в виде BLOB-полей.
ETL-процесс, выстраиваемый на этапе внедрения Программы на стороне ведомства-источника данных, при загрузке публикуемых данных из ИС ведомства должен получать собственно публикуемые данные и ссылки на файлы Хранилища BLOB-объектов.
ETL-процесс записывает в ProStore публикуемые данные и ссылки на файлы Хранилища BLOB-объектов.
Модуль «СМЭВ3-адаптер» получает от СМЭВ3 запрос Вида сведения, который предполагает предоставление содержимого BLOB-объекта.
Модуль «СМЭВ3-адаптер» отправляет запрос публикуемых данных на исполнение в ProStore.
Модуль «СМЭВ3-адаптер» запрашивает у модуля «BLOB-адаптер» содержимое BLOB-объекта по ссылке, полученной в поле с типом
LINK.Модуль «BLOB-адаптер» преобразует ссылку из поля
LINKв запрос на считывание файла к Хранилищу BLOB-объектов и возвращает модуль «СМЭВ3-адаптер» полученное от Хранилища BLOB-объектов содержимое файла.Модуль «СМЭВ3-адаптер» отправляет содержимое считанного файла в FTP-сервер СМЭВ3.
Модуль «СМЭВ3-адаптер» формирует ответ Вида сведения, передавая в нем идентификатор файла с содержимым BLOB-объекта, под которым он был сохранен на FTB-сервер.
Данная техника передачи больших файлов с бинарными данными между участниками взаимодействия (через FTP-сервер СМЭВ3) выполнена в соответствии с методическими рекомендациями СМЭВ3.
Для считывания из Хранилища BLOB-объектов содержимого файла модуль «BLOB-адаптер»
выступает в роли синхронного клиента, используя стандартный запрос GET
протокола HTTP.
Для запроса содержимого файла в модуле «BLOB-адаптер» реализован синхронный
HTTP-сервер, а в модуле «СМЭВ3-адаптер» синхронный клиент. Используется метод
POST.
Для мониторинга работы в модуле «BLOB-адаптер» реализованы метрики и HealthCheck, перечисленные в Таблица 6.4.
№ |
Название |
Описание |
Request |
Среднее количество запросов в секунду |
|
Request error |
Среднее количество ошибок в секунду при обработке запросов |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
6.2.13. Формирование, подписание и передачи через ПОДД сформированных документов
Реализация нового процесса по генерации и подписанию сформированного документа , предоставляющего возможность передачи подписанных файлов из Программы в ИС-потребители через ПОДД приведена на рисунке ниже.
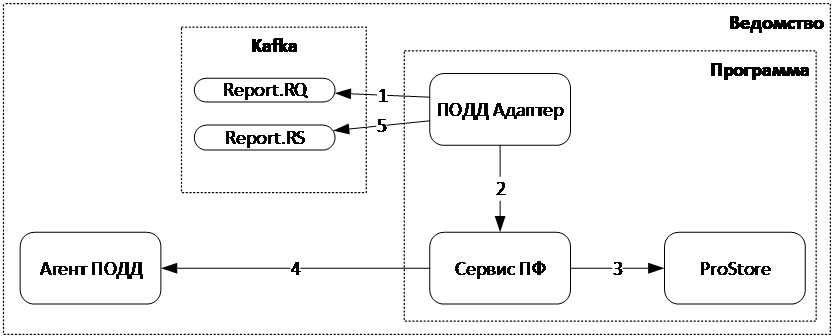
Рисунок - 6.58 Работа с ФД в ПОДД
Модуль «ПОДД-адаптер» считывает запрос на генерацию ПФ из топика Kafka (report.rq).
Модуль «ПОДД-адаптер» делегирует генерацию ПФ Сервису ПФ, передавая все параметры запроса.
Сервис формирования документов собирает необходимые публикуемые данные из ProStore и на их основании генерирует запрошенные ПФ.
Сервис формирования документов запрашивает подписание электронной подписью сгенерированных ПФ, обращаясь к сервису «Подписание файлов» Агента ПОДД.
Модуль «ПОДД-адаптер» отправляет сгенерированные и подписанные ПФ в топик Kafka (report.rs)
Для делегирования задания генерации ПФ модуль «ПОДД-адаптер» выступает синхронным клиентом, а Сервис формирования документов реализует серверную часть синхронного REST API.
Для подписания электронной подписью Агент ПОДД реализует сервер REST API и вся работа с криптографическими средствами, в том числе и хранение ключей, реализована в Агенте ПОДД. Сервис формирования документов выступает в роли синхронного клиента REST API.
Сервис формирования документов поддерживает формирование документов в форматах:
XML (электронная подпись – XML Signature);
PDF (с отделяемой электронной подписью (.p7s) или без нее).
Сервис формирования документов позволяет настраивать одновременно несколько видов генерируемых ПФ и для каждого из них формат генерируемых ПФ настраивается с помощью отдельного pebble-шаблона.
Для мониторинга работы в Сервис формирования документов реализованы метрики и HealthCheck, перечисленные в Таблица 6.5.
№ |
Название |
Описание |
Request |
Среднее количество запросов в секунду |
|
Request error |
Среднее количество ошибок в секунду при обработке запросов |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
6.2.14. Предоставление оценки объема запрашиваемых ПОДД данных
Оценка объема запрашиваемых данных позволяет получить для переданного запроса:
общее прогнозируемое количество строк результата запроса;
общее количество байт по всем строкам результата запроса.
Для получения оценки запроса доработаны:
ProStore (добавлен специальный флаг запроса, обозначающий необходимость оценить объем данных без возвращения самих строк результата запроса);
Модуль «ПОДД-адаптер» (добавлена логика обработки параметра
isForEstimationв запросе, в том числе работа с дополнительным топиком Kafka (query.estimation.rs).
6.2.15. Управление взаимодействием со СМЭВ3
В целях возможности управления взаимодействием со СМЭВ3 в ситуации, когда СМЭВ3 не отвечает на запрос, в СМЭВ3-адаптер добавлены настройки:
время (таймаут) ожидания ответа СМЭВ3-сервера на SOAP-запрос СМЭВ3-адаптера;
время (таймаут) между повторной отправкой SOAP-запроса в случае отсутствия ответа на предыдущую посылку запроса.
Поддержка работы со схемами СМЭВ3 версии 1.2 и 1.3 включены в единую реализацию программного модуля СМЭВ3-адаптера.
Для модуля «СМЭВ3-адаптер» механизм сервисной БД изменен с PostgeSQL на Apache Zookeeper, используемый во всех модулях Программы.
Для мониторинга работы в модуля «СМЭВ3-адаптер» реализованы метрики и HealthCheck, перечисленные в Таблица 6.6.
№ |
Название |
Описание |
Request |
Среднее количество запросов в секунду |
|
Request error |
Среднее количество ошибок в секунду при обработке запросов |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
6.2.16. Запись событий в журнал и конфигурирование количества соединений к ProStore для СМЭВ3
Модифицированный механизм логирования модуля «СМЭВ3-адаптер» записывает в локальный журнал:
начало каждого этапа обработки запроса, фиксируя для каждого из них, в том числе, уникальный идентификатора запроса СМЭВ3;
коды ошибок СМЭВ3.
В настройки добавлен параметр, указывающий одновременное количество соединений с ProStore.
6.2.17. Использование табличных параметров в запросах через ПОДД и выделение функций в отдельные модули
С целью обеспечения возможность использования ТП при взаимодействии через ПОДД и выделения ресурсоемких функций в отдельные программные модули для горизонтального масштабирования и перехода на микросервисную архитектуру функции существовавшего ПОДД-адаптера были разделены на несколько программных модулей, а так же добавлены новые функции (отдельные программные модули). Последовательность обработки запроса с использованием ТП приведена на рисунке ниже.
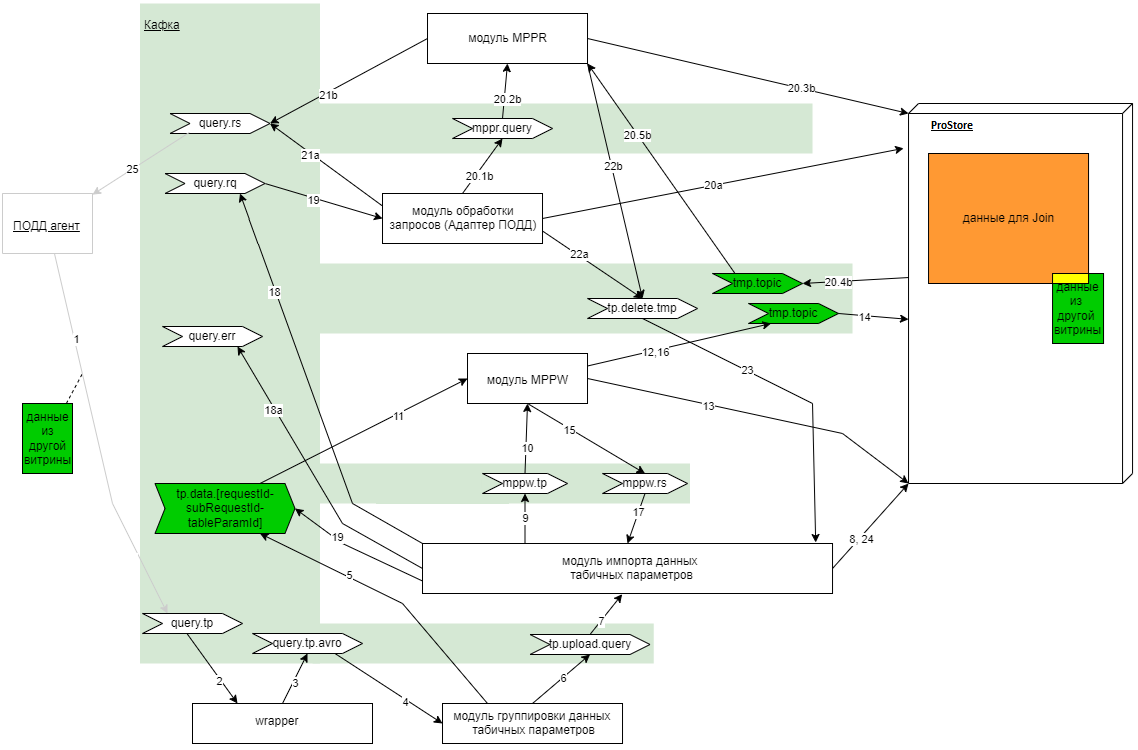
Рисунок - 6.59 Последовательность обработки запроса с использованием ТП
Агент ПОДД передает комплексный запрос данных, содержащий в себе блок описания табличных параметров и сами таблицы с данными, сформированными другим экземпляром Программы, в топик Kafka (query.tp).
Модуль «ПОДД-адаптер - Wrapper» считывает и преобразует поступающие пакеты в формат, пригодный для параллельной их обработки.
Модуль «ПОДД-адаптер - Wrapper» записывает преобразованные пакеты в топик Kafka (query.tp.avro).
Модуль «ПОДД-адаптер - Модуль группировки данных ТП» считывает подготовленные модулем «ПОДД-адаптер - Wrapper» пакеты.
Модуль «ПОДД-адаптер - Модуль группировки данных ТП» раскладывает пакеты отдельных ТП разных запросов по отдельным топикам Kafka (tp.data.[requestId-subRequestId-tableParamId].
Модуль «ПОДД-адаптер - Модуль группировки данных ТП» для каждого отдельного запроса отправляет задание в топик Kafka (tp.upload.query).
Модуль «ПОДД-адаптер - Модуль импорта табличных параметров» считывает задание из топика Kafka (tp.upload.query).
«ПОДД-адаптер - Модуль импорта табличных параметров» создает в ProStore временную таблицу для каждого табличного параметра запроса.
«ПОДД-адаптер - Модуль импорта табличных параметров» отправляет задание на массово-параллельную загрузку данных ТП в модуль «ПОДД-адаптер - Модуль MPPW», в топик Kafka (mppw.tp).
Модуль «ПОДД-адаптер - Модуль импорта табличных параметров» считывает задание из топика Kafka (mppw.tp).
Модуль «ПОДД-адаптер - Модуль импорта табличных параметров» считывает данные ТП из топика Kafka (tp.data.[requestId-subRequestId-tableParamId]).
Модуль «ПОДД-адаптер - Модуль MPPW» записывает данные ТП в формате массово-параллельной загрузки данных ProStore во временный топик Kafka (tmp.topic).
Модуль «ПОДД-адаптер - Модуль MPPW» запускает в ProStore процесс массово-параллельной загрузки данных всех ТП одного запроса.
ProStore выполняет процесс массово-параллельной загрузки данных из временного топик Kafka (tmp.topic).
Модуль «ПОДД-адаптер - Модуль MPPW» после загрузки данных всех ТП запроса в ProStore записывает сообщение об окончании загрузки в топик Kafka (mppw.rs).
Модуль «ПОДД-адаптер - Модуль MPPW» удаляет временные топики Kafka (tmp.topic).
Модуль «ПОДД-адаптер - Модуль импорта табличных параметров» считывает сообщение о загрузке данных ТП из топика Kafka (mppw.rs).
Если возникли ошибки, то «ПОДД-адаптер - Модуль импорта табличных параметров» посылает сообщение об ошибке обработки запроса в топик Kafka (query.err) и обработка этого запроса прекращается. Если ошибок не возникло, то помещает запрос с ТП в единую очередь запросов – в топик Kafka (query.rq).
«ПОДД-адаптер - Модуль исполнения запросов» считывает запрос с ТП из топика Kafka (query.rq).
Если запрос не требует массово-параллельного считывания результатов, то «ПОДД-адаптер - Модуль исполнения запросов» самостоятельно отправляет его в ProStore (20a). Иначе (требуется mppr) «ПОДД-адаптер - Модуль исполнения запросов» делегирует исполнение запроса «ПОДД-адаптер - Модуль MPPW»:
20.1b: «ПОДД-адаптер - Модуль исполнения запросов» направляет в топик Kafka (mppr.query) запрос;
20.2b: Модуль «ПОДД-адаптер - Модуль MPPR» считывает запрос из топика Kafka;
20.3b: Модуль «ПОДД-адаптер - Модуль MPPR» отправляет запрос в ProStore;
20.4b: ProStore выгружает в массово-параллельном режиме результат запроса в топик Kafka (tmp.topic);
20.5b: «ПОДД-адаптер - Модуль MPPW» обрабатывает результат запроса из топика Kafka (tmp.topic).
Модуль, который отправил запрос в ProStore
21а – «ПОДД-адаптер - Модуль исполнения запросов»,
21b – Модуль «ПОДД-адаптер - Модуль MPPR», направляет результат запроса с ТП в топик Kafka (query.rs).
Модуль, который отправил запрос в ProStore
22а – «ПОДД-адаптер - Модуль исполнения запросов»,
22b – «ПОДД-адаптер - Модуль MPPR»), направляет сигнал об обработке запроса с ТП в топик Kafka (tp.delete.tmp).
Модуль «ПОДД-адаптер - Модуль импорта табличных параметров» считывает сообщение об обработке запроса с ТП из топика Kafka (tp.delete.tmp).
Модуль «ПОДД-адаптер - Модуль импорта табличных параметров» удаляет временные таблицы из ProStore.
Агент ПОДД получает результат запроса с ТП из топика Kafka (query.rs).
Итоговая компонентная структура Программы в части обработки запросов приведена на рисунке ниже.
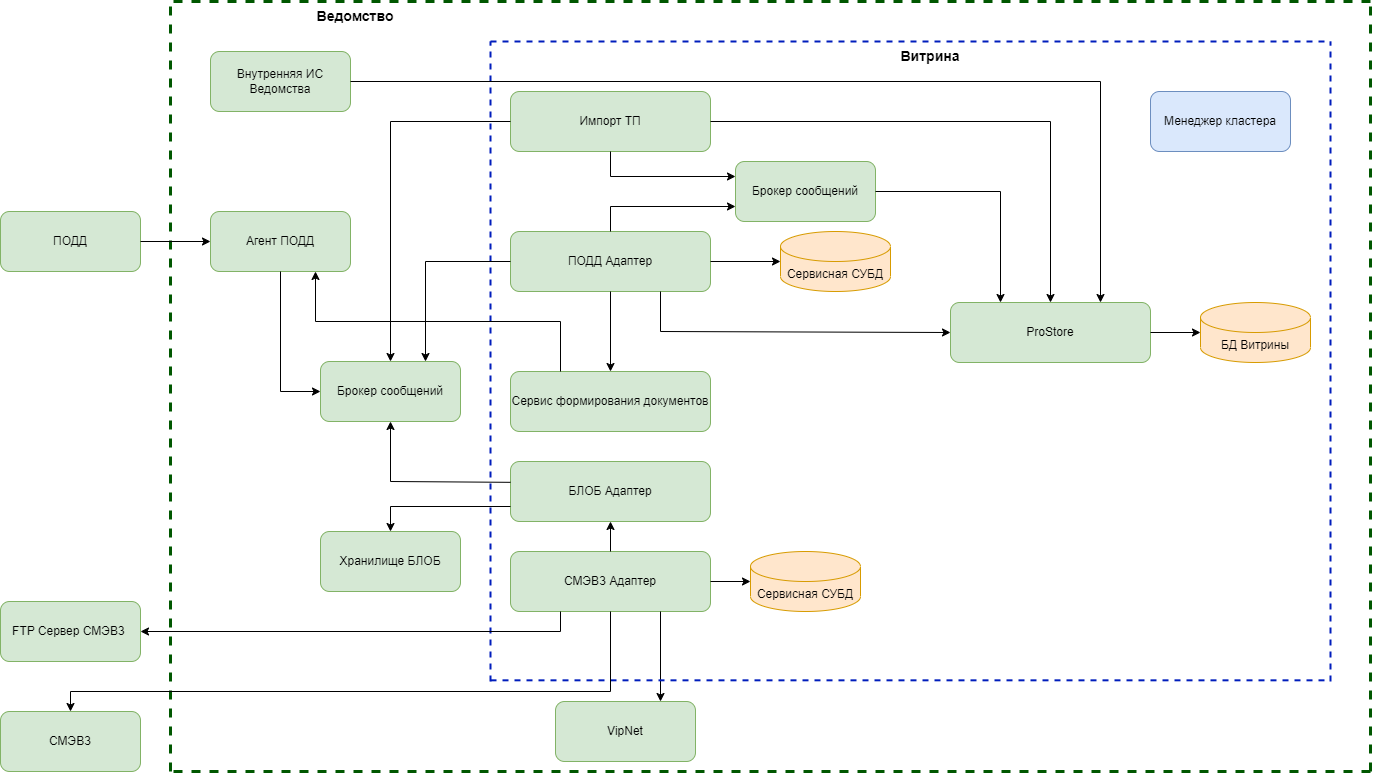
Рисунок - 6.60 Компонентная структура Программы
Для мониторинга работы в модуле ПОДД-адаптер-Модуль группировки данных ТП реализованы метрики и HealthCheck, перечисленные в Таблица 6.7.
Для мониторинга работы в модуле ПОДД-адаптер-Модуль-Модуль импорта данных ТП реализованы метрики и HealthCheck, перечисленные в Таблица 6.8.
Для мониторинга работы в модуле ПОДД-адаптер-Модуль исполнения запросов реализованы метрики и HealthCheck, перечисленные в Таблица 6.9.
Для мониторинга работы в модуле ПОДД-адаптер-Модуль MPPR реализованы метрики и HealthCheck, перечисленные в Таблица 6.10.
Для мониторинга работы в модуле ПОДД-адаптер-Модуль MPPW реализованы метрики и HealthCheck, перечисленные в Таблица 6.11.
Для мониторинга работы в модуле ПОДД-адаптер-Модуль-Wrapper реализованы метрики и HealthCheck, перечисленные в Таблица 6.12.
№ |
Название |
Описание |
Chunk Total |
Среднее количество обработанных блоков данных в секунду |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
№ |
Название |
Описание |
Chunk Total |
Среднее количество обработанных блоков данных в секунду |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
№ |
Название |
Описание |
Chunk Total |
Среднее количество обработанных блоков данных в секунду |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
№ |
Название |
Описание |
Chunk Total |
Среднее количество обработанных блоков данных в секунду |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
№ |
Название |
Описание |
Chunk Total |
Среднее количество обработанных блоков данных в секунду |
|
CPU Usage |
Использование CPU |
|
JVM Total |
Объем памяти виртуальной машины Java |
|
Log Events |
Количество событий (в журналах логирования) в минуту |
|
Liveness |
HealthCheck |
№ |
Название |
Описание |
Liveness |
HealthCheck |
6.2.18. Пакетная загрузка больших объемов данных при первичном наполнении витрины
В рамках выполненной заявки, в целях уменьшения количества итераций загрузки данных из брокера сообщений в СУБД ADB витрины данных при первичном наполнении витрины (без историчности) для реализации возможности однократного переноса горячих записей вместо многократного порционного режима, были разработаны следующие функции пакетной загрузки больших объемов данных при первичном наполнении витрины:
функция переноса «горячих» записей витрины в «актуальные» записи витрины путём формирования SQL-запроса и отправки его в ADB на обновление данных (UPDATE) из физической таблицы staging в таблицу actual;
функция переноса «горячих» записей витрины в «актуальные» записи витрины путём формирования SQL-запроса и отправки его в ADB на вставку данных (INSERT) из физической таблицы staging в таблицу actual;
универсальный механизм переноса «горячих» данных в ADB вне зависимости от используемого коннектора из Брокера сообщений в ADB.
Запрос на пакетную загрузку больших объемов данных из брокера сообщений Kafka обрабатывается в следующем порядке:
Внешняя информационная система отправляет запрос INSERT SELECT FROM upload_external_table через JDBC-драйвер Prostore.
Запрос поступает в сервис исполнения запросов Prostore.
Сервис исполнения запросов отправляет команду на загрузку данных в соответствующие коннекторы и отслеживает состояние загрузки с помощью сервиса мониторинга статусов Kafka.
Команда отправляется в коннекторы тех СУБД хранилища, в которых хранятся данные логической таблицы, или той СУБД, где размещается standalone-таблица.
Информация о процессе загрузки данных сохраняется в сервисной базе данных.
Каждый задействованный коннектор загружает данные из топика Kafka в свою СУБД хранилища.
Данные считываются из топика, на который указывает внешняя таблица загрузки, используемая в запросе INSERT SELECT FROM upload_external_table.
По завершении загрузки каждого или всех пакетов данных (в зависимости от СУБД) сервис исполнения запросов отправляет в каждую задействованную СУБД команду на версионирование данных.
JDBC-драйвер возвращает ответ во внешнюю информационную систему. Ответ возвращается синхронно — после успешной загрузки всех данных.
Перенос «горячих» записей витрины в «актуальные» записи витрины осуществляется на этапе версионирования данных (шаг 8).
6.2.18.1. Описание технического решения по переносу «горячих» записей витрины в «актуальные» записи витрины путём формирования SQL-запроса и отправки его в ADB на обновление данных (UPDATE) из физической таблицы staging в таблицу actual
В рамках технического решения для Типового ПО витрины данных были проведены следующие работы:
реализация создания обогащенного SQL-запроса UPDATE на обновление данных из физической таблицы staging в таблицу actual;
отправка обогащенного SQL-запроса UPDATE в ADB через модуль плагина ADB.
6.2.18.2. Описание процесса создания обогащенного SQL-запроса UPDATE на обновление данных из физической таблицы staging в таблицу actual
В процессе переноса «горячих» записей витрины в «актуальные» записи витрины осуществляется версионирование данных. В процессе версионирования данных создается обогащенный SQL-запрос UPDATE, предназначенный для обновления данных в физической таблице actual по данных из физической таблицы staging. Обогащенный запрос к ADB на обновление данных в физической таблицы logical_table_1_actual на основе данных из физической таблицы logical_table_1_staging имеет вид:
UPDATE testdb_bulk_insert_1.logical_table_1_actual actual
SET
sys_to = -1,
sys_op = staging.sys_op
FROM (
SELECT id, MAX(sys_op) as sys_op
FROM testdb_bulk_insert_1.logical_table_1_staging
GROUP BY id
WHERE staging.id=actual.id AND
actual.sys_from < 0 AND actual.sys_to IS NULL
6.2.18.3. Описание процесса отправки обогащенного SQL-запроса UPDATE в ADB через модуль плагина ADB
В процессе переноса «горячих» записей витрины в «актуальные» записи витрины осуществляется версионирование данных. В процессе версионирования данных созданный обогащенный SQL-запрос UPDATE отправляется для исполнения в СУБД ADB. Отправка запроса производится через модуль плагина ADB посредством JDBC-соединения.
6.2.18.3.1. Описание технического решения по переносу «горячих» записей витрины в «актуальные» записи витрины путём формирования и отправки SQL-запроса в ADB на вставку данных (INSERT) из физической таблицы staging в таблицу actual
В рамках технического решения для Типового ПО витрины данных были проведены следующие работы:
реализация создания обогащенного SQL-запроса INSERT на вставку данных из физической таблицы staging в таблицу actual;
отправка обогащенного SQL-запроса INSERT в ADB через модуль плагина ADB.
6.2.18.4. Описание процесса создания обогащенного SQL-запроса INSERT на вставку данных из физической таблицы staging в таблицу actual
В процессе переноса «горячих» записей витрины в «актуальные» записи витрины осуществляется версионирование данных. В процессе версионирования данных создается обогащенный SQL-запрос INSERT, предназначенный для вставки данных из физической таблицы staging в физическую таблицу actual. Обогащенный запрос к ADB на вставку данных из физической таблицы logical_table_1_staging в физическую таблицу logical_table_1_actual имеет вид:
INSERT INTO testdb_bulk_insert_1.logical_table_1_actual (id, boolean_col, int32_col, int_col, bigint_col, float_col, double_col, char10_col, varchar_col, uuid_col, link_col, date_col, time_col, timestamp_col, sys_from, sys_op)
SELECT DISTINCT ON (staging.id) staging.id, staging.boolean_col, staging.int32_col, staging.int_col, staging.bigint_col, staging.float_col, staging.double_col, staging.char10_col, staging.varchar_col, staging.uuid_col, staging.link_col, staging.date_col, staging.time_col, staging.timestamp_col, 0 AS sys_from, 0 AS sys_op FROM testdb_bulk_insert_1.logical_table_1_staging staging
LEFT JOIN testdb_bulk_insert_1.logical_table_1_actual actual ON staging.id=actual.id AND actual.sys_from = 0
WHERE actual.sys_from IS NULL AND staging.sys_op <> 1, params=null), PreparedStatementRequest(sql=TRUNCATE testdb_bulk_insert_1.logical_table_1_staging
6.2.18.5. Описание процесса отправки обогащенного SQL-запроса INSERT в ADB через модуль плагина ADB
В процессе переноса «горячих» записей витрины в «актуальные» записи витрины осуществляется версионирование данных. В процессе версионирования данных созданный обогащенный SQL-запрос INSERT отправляется для исполнения в СУБД ADB. Отправка запроса производится через модуль плагина ADB посредством JDBC-соединения.
6.2.18.5.1. Описание технического решения по переносу «горячих» данных в ADB вне зависимости от используемого коннектора из Брокера сообщений в ADB
В рамках технического решения для Типового ПО витрины данных были проведены следующие работы:
реализация алгоритма переноса «горячих» данных в ADB, обеспечивающего независимость переноса «горячих» записей витрины в «актуальные» записи витрины от используемого коннектора.
6.2.18.6. Описание алгоритма переноса «горячих» записей витрины в «актуальные» записи витрины вне зависимости от используемого коннектора
Процесс переноса «горячих» данных в ADB осуществляется согласно алгоритму переноса «горячих» записей витрины в «актуальные» записи витрины вне зависимости от используемого коннектора. Алгоритм представляет собой последовательность следующих этапов. На первом этапе из Сервиса исполнения запросов осуществляется вызов операции массово-параллельной записи для начала переноса «горячих» данных в ADB. Вызываемая операция производится с помощью коннектора из Брокера сообщений в ADB. На втором этапе посредством коннектора выполняется чтение данных из топика Брокера сообщений и наполнение этими данными физической таблицы staging в ADB. Когда все данные прочитаны, производится коммит чтения загруженных данных, а управление возвращается в Сервис исполнения запросов. На третьем этапе в Сервисе исполнения запросов создается обогащенный SQL-запрос UPDATE на обновление данных из физической таблицы staging в таблицу actual. Далее этот запрос отправляется посредством JDBC на исполнение в СУБД ADB. При успешном выполнении этого запроса создается обогащенный SQL-запрос INSERT на вставку данных из физической таблицы staging в таблицу actual. Далее этот запрос также отправляется посредством JDBC на исполнение в СУБД ADB. После исполнения обогащенного запроса в ADB управление возвращается в Сервис исполнения запросов, который завершает операцию массово-параллельной записи. Алгоритм в виде блок-схемы приведен на рис. A.1. Как видно из тестового описания и блок-схемы, алгоритм переноса «горячих» записей витрины в «актуальные» записи витрины архитектурно и функционально не зависит от используемого коннектора, поскольку все шаги алгоритма выполняются после завершения работы коннектора из Брокера сообщений в ADB.
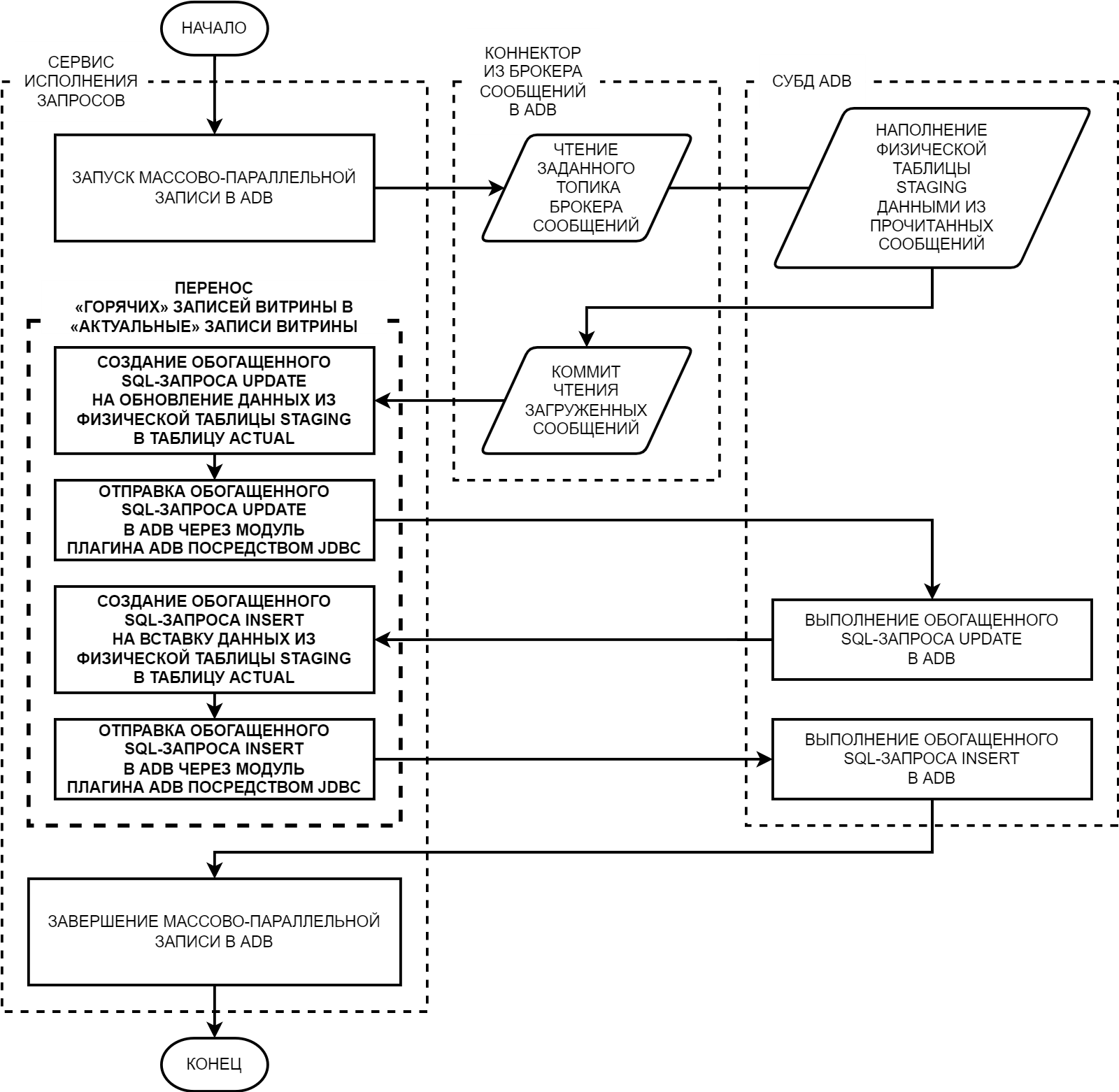
Рисунок - 6.61 Блок-схема алгоритма переноса «горячих» данных в ADB с субалгоритмом переноса «горячих» записей витрины в «актуальные» записи витрины
6.2.19. Исполнение запросов с табличными параметрами через неверсионируемые таблицы
В рамках выполненных работ, в целях исключения блокировок при одновременной работе ETL и загрузке дельт (набора изменяемых данных), обеспечения возможности исполнения распределенных запросов с табличными параметрами через неверсионируемые таблицы (необходимо для витрины Росреестра и иных витрин с часто изменяющимися данными, поставляемыми из различных источников) было доработано Типовое ПО витрины данных. В рамках данного требования были выполнены следующие работы:
реализована функция записи адаптером ПОДД временных данных из ТП запроса в неверсионируемые таблицы;
реализована функция удаления адаптером ПОДД временных данных из ТП из неверсионируемых таблиц после их использования в целевом запросе;
проведено нагрузочное тестирование типового ПО витрины данных с доработанными модулями / компонентами.
В рамках данного требования нагрузочное тестирование Типового ПО витрины данных проводится на конфигурациях установки Стандарт и Лайт.
Целевой показатель назначения – исполнение запросов с табличными параметрами не блокируется при заливке дельт. Показатели времени исполнения запросов с табличными параметрами определяются инфраструктурой витрины и сложностью запросов.
6.2.19.1. Описание технического решения по записи адаптером ПОДД временных данных из табличных параметров запроса в неверсионируемые таблицы
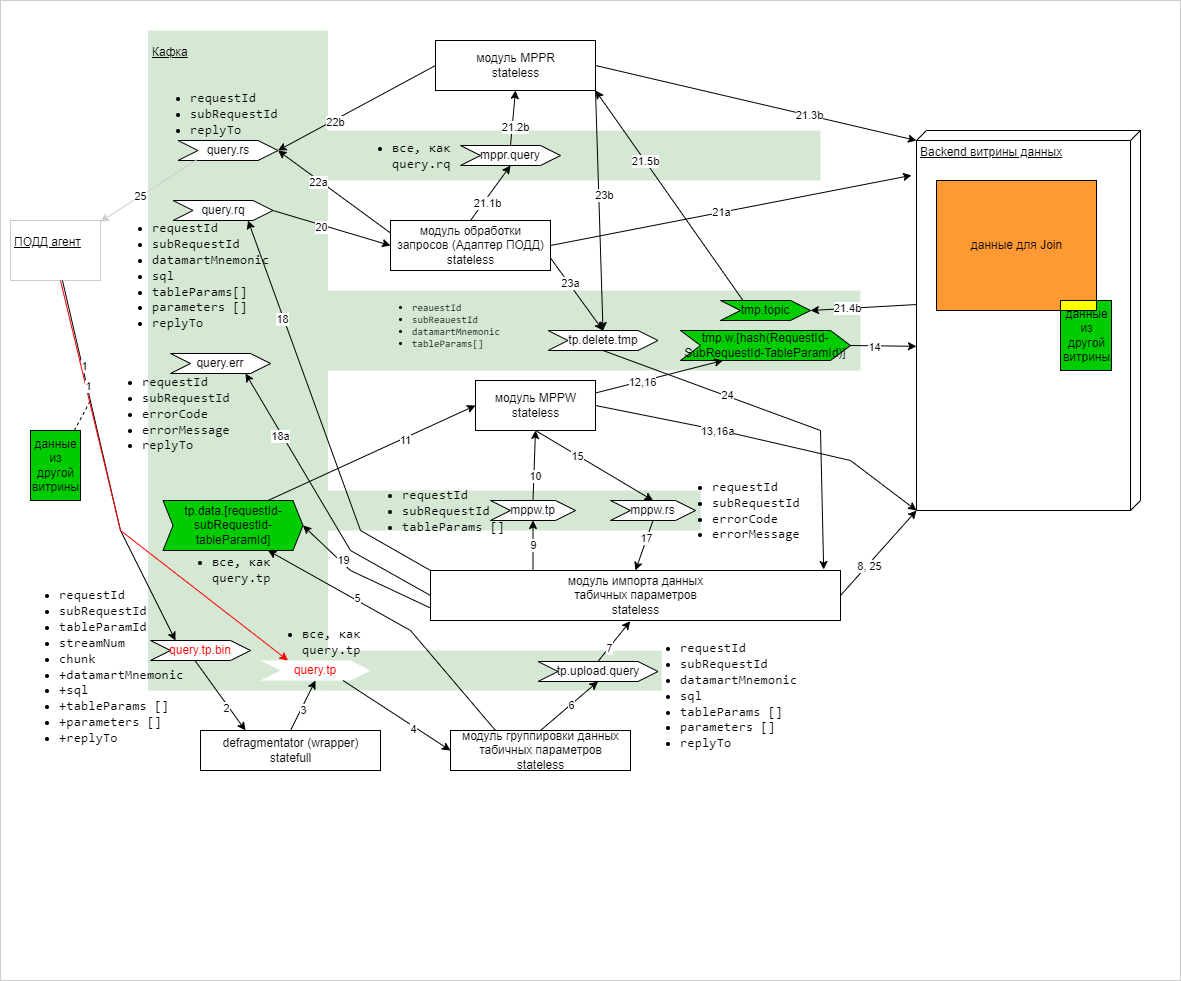
Рисунок - 6.62 Архитектурное решение по исполнению запросов с ТП через неверсионируемые таблицы
Описание функциональности модулей представлено в Таблица 6.13
Название модуля |
Выполняемая функциональность |
Модуль группировки данных ТП |
Распределяет (группирует) фрагменты каждого запроса по отдельным топикам. Это позволяет распределить обработку запросов между экземплярами модулей MPPW |
Модуль импорта данных ТП |
Управляет жизненным циклом табличных параметров запроса в витрине (создает временные таблицы, контролирует загрузку данных в них, передает запрос на исполнение, удаляет использованные временные таблицы) |
Модуль MPPW |
Загружает (в многопоточном режиме) данные табличных параметров во временные таблицы витрины |
Модуль обработки запросов (Адаптер ПОДД) |
Управляет исполнением всех поступающих запросов (не только запросов с табличными параметрами). Если запрос допускает получение большого количества строк ответа, Адаптер ПОДД делегирует обработку этого запроса Модулю MPPR. В противном случае Адаптер самостоятельно отправляет запрос на исполнение в СУБД витрины и передает полученный ответ на запрос Агенту ПОДД |
Модуль MPPR |
Адаптирован для обработки в параллельном режиме запросов, допускающих большое количество строк в ответе |
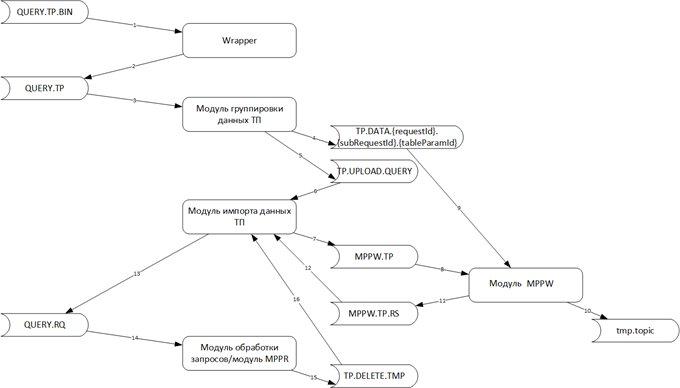
Рисунок - 6.63 Структура данных технического решения
В зависимости от способа разбиения на чанки передача ТП разделена на 2 топика:
– QUERY.TP (построчное); – QUERY.TP.BIN (бинарное)
Топик |
Продюсер |
Консьюмер |
Предназначение |
QUERY.TP.BIN |
Агент ПОДД |
Wrapper |
Передача ТП при бинарном разбиении на чанки |
QUERY.TP |
Wrapper/Агент ПОДД |
Модуль группировки данных ТП |
Передача ТП при построчном разбиении на чанки |
TP.UPLOAD.QUERY |
Модуль группировки данных ТП |
Модуль импорта данных ТП |
Создание временных таблиц в ProStore |
QUERY.RQ |
Модуль импорта данных ТП |
Адаптер ПОДД (модуль обработки запросов) |
Топик sql запросов на исполнение |
TP.DATA.{requestId}.{subRequestId}.{tableParamId} |
Модуль группировки данных ТП |
Модуль массив-параллельной записи данных (модуль MPPW) |
Загрузка чанков данных табличных параметров |
MPPW.TP |
Модуль импорта данных ТП |
Модуль MPPW |
Загрузка чанков во временные таблицы |
MPPW.TP.RS |
Модуль MPPW |
Модуль импорта данных ТП |
Получение ответа от модуля MPPW при загрузке чанков во временные таблицы |
tmp.w.[nameHash] |
Модуль MPPW |
Prostore |
Временный топик чанков для MPPW ProStore’а |
TP.DELETE.TMP |
Модуль обработки запросов |
Модуль импорта данных ТП |
Топик для удаления временных таблиц в ProStore |
6.2.19.2. Реализация модуля группировки данных ТП
В ходе выполнения работ реализован модуль группировки данных табличных параметров, который реализует распределение (группировку) фрагментов каждого запроса по отдельным топикам. Это позволяет распределять обработку запросов между экземплярами модулей MPPW. Модуль группировки данных табличных параметров реализует следующую функциональность:
6.2.19.3. Реализация модуля импорта ТП
В ходе выполнения работ реализован модуль импорта табличных параметров, который реализует следующую функциональность:
Получение сообщения на запрос с табличными параметрами из топика Kafka
tp.upload.query.Замена имени таблицы в запросе (необходимо найти название таблицы, совпадающее с name атрибута табличного параметра вида
@{tableParamName}и заменить на имяreadable_[hash(RequestId_SubRequestId_TableParamId)], без символа@. Переименование таблицы требуется для обработки конкурентных запросов).Создание целевой временной writable таблицы с именем
writable_[hash(RequestId_SubRequestId_TableParamId)]в витрине данных с опцией создания standalone table, с указанием на standalone таблицуstandalone_[hash(RequestId_SubRequestId_TableParamId).Создание целевой временной readable таблицы с именем
readable_[hash(RequestId_SubRequestId_TableParamId)]c указанием той же standalone таблицы без опции создания standalone таблицы (имя readable таблицы должно совпадать с именем временной таблицы в запросе sql за вычетом символа@).Направление задания модулю MPPW через топик
mppw.tp(в качестве целевой таблицы указываетсяwritable_[hash(RequestId_SubRequestId_TableParamId)], далее ожидание ответа об окончании загрузки табличных параметров в топикеmppw.rs).
6.2.19.4. Реализация модуля MPPW
В ходе выполнения работ доработан модуль массив-параллельной загрузки данных (далее MPPW), который реализует следующую функциональность:
Получение сообщения из топика
mppw.tpПодписка на топик
tp.data.[RequestId-SubRequestId-TableParamId], ожидание поступления последнего чанка в течение таймаута. Если таймаут истек, модуль отписывается и формирует ответ с ошибкой. Если все успешно, прочитанные чанки преобразует по типам данных и помещает во временный топик для загрузки данных. Имя временного топика, используемого как внешняя таблица определяется следующим образом:tmp.w.[RequestId-SubRequestId-TableParamId], если он существует на момент начала заливки данных, его следует пересоздать.Создание внешней таблицы загрузки (Upload External Table) c опцией
auto.create.sys_op.enable=falseбез открытия дельты.Подача команды на заливку данных во внешней writeable-таблице.
Ожидание окончания заливки.
Повторение всех операций для всех таблиц в рамках запроса/подзапроса, формирование одного сообщения ответ в топике
mppw.rs.Фиксация оффсета.
6.2.19.5. Реализация модуля обработки запросов (Адаптер ПОДД)
В ходе выполнения работ доработан модуль обработки запросов (Адаптер ПОДД), который реализует следующую функциональность:
Получение сообщение из
query.rq.
2. В случае режима LLR, Адаптер ПОДД реализует следующий порядок действий:
- выполняет запрос;
- возвращает данные в query.rs;
- сохраняет сообщение в tp.delete.tmp для модуля импорта табличных параметров о завершении выполнения запроса;
- фиксирует оффсет.
1. В случае режима MPPR, Адаптер ПОДД реализует следующий порядок действий:
- формирует сообщение в топик mppr.query (делегирует);
- фиксирует оффсет.
6.2.19.6. Реализация модуля MPPR
В ходе выполнения работ доработан модуль MPPR, который, в случае делегирования запроса на этот модуль, реализует следующую функциональность:
Получает сообщение из
mppr.query.Обращается в витрину.
Создает внешнюю таблицу выгрузки (Download External Table).
Выгружает данные через временный топик и внешнюю таблицу выгрузки (Download External Table) в топик
query.rs.Удаляет временный топик и внешнюю таблицу выгрузки (Download External Table)
Кладет сообщение в топик Kafka
tp.delete.tmpдля модуля импорта табличных параметров о завершении выполнения запроса.Фиксирует оффсет.
6.2.19.6.1. Описание технического решения по удалению адаптером ПОДД временных данных из табличных параметров из неверсионируемых таблиц после их использования в целевом запросе
В рамках выполненных работ было реализовано удаление адаптером ПОДД временных данных из табличных параметров из неверсионируемых таблиц после их использования в целевом запросе. В ходе выполнения работ был доработан модуль MPPW, который реализует следующую функциональность:
удаление временного топика
tmp.w.[nameHash];удаление внешней таблицы загрузки (Upload External Table).
Модуль импорта данных табличных параметров удаляет топик tp.data.[RequestId-SubRequestId-TableParamId].
Также модуль импорта данных табличных параметров при получении сообщения в топике tp.delete.tmp выполняет следующие действия:
удаление внешней таблицы на чтение (Readable Table), без опции удаления таблицы-источника данных (Standalone Table)
удаление внешней таблицы на запись (Writable Table) с опцией удаления таблицы-источника данных (Standalone Table).
6.2.20. Модуль загрузки данных в Витрину из внешних источников
В рамках выполненных работ необходимо обеспечить возможность обновления информации в таблице витрины данных при одновременной загрузке данных из нескольких внешних источников, действующими несогласованно. В рамках данного требования были реализованы следующие технические решения:
функция авторизации доступа источников только к своим записям;
функция асинхронной загрузки данных из источников по REST;
функция получения статуса асинхронного задания по REST-интерфейсу;
функция временного хранилища данных;
функция обработки очереди файлов при помощи реализованного модуля исполнения асинхронных заданий.
В рамках выполненных работ реализована авторизация доступа источников только к своим записям, которая обеспечивает следующие функциональные особенности:
- аутентификация реализуется на основе JWT токена, предоставляемого для каждого ВУЗа индивидуально и заблаговременно. В нагрузке токена передается информация:
кем сформирован токен;
идентификатор ВУЗа, для которого сформирован токен;
подпись токена формируется методом получения хеш-функции SHA-256 с секретом.
Для загрузки данных в витрину со стороны ВУЗов в POST-запросе передается загружаемый файл и HTTP заголовок аутентификации с токеном авторизации.
Для загружаемых файлов доступен формат CSV.
При получении запроса сервис для передачи данных выполняет проверку токена:
определяется идентификатор ВУЗа по поступившему токену;
- проверяется наличие идентификатора среди прочитанных в очереди;
если идентификатор обнаружен, то сервисом формируется подпись, которая сверяется с подписью в поступившем токене (при формировании подписи используется тот же секрет, что и при формировании токена для ВУЗа);
при недопустимом идентификаторе ВУЗа или ошибочной подписи возвращается статус запроса с ошибкой;
при корректном идентификаторе ВУЗа и верной подписи выполняется обработка запроса.
6.2.20.1. Описание формата CSV для сервиса загрузки данных
Описание параметров формата CSV приведено в Таблица 6.15.
Параметр |
Значение |
|---|---|
Разделитель строк |
Любой вариант из CR/LF (0x0D0A), CR (0x0D), LF (0x0A) |
Разделитель полей |
По настройке csv-parser/separator |
Строка заголовка |
Обязательно |
Порядок полей в строке |
Определяется строкой заголовка |
Ограничитель текстового поля |
По настройке csv-parser/quote-char |
Символ маскировки в текстовом поле |
По настройке csv-parser/escape-char |
Обнаружение значения null |
По настройке csv-parser/field-as-null |
Кодирование символов |
UTF-8 |
Десятичный разделитель |
Символ «.» (0x2E), может не указываться для целых значений |
Формат даты |
Любой из (без кавычек): «dd.MM.yyyy», «yyyy-MM-dd» |
Формат времени |
Любой из (без кавычек): «HH:mm:ss», «H:mm:ss» |
Формат даты-времени |
Любой из (без кавычек): «yyyy-MM-dd HH:mm:ss», «dd.MM.yyyy HH:mm:ss» |
6.2.20.1.1. Описание технического решения по реализации асинхронной загрузки данных из источников по REST
Для обеспечения параллельной загрузки данных с независимым масштабированием REST интерфейса, обеспечена буферизация поступающих на загрузку данных. Буферизированные данные направляются в базу менеджером дельт с группировкой по базам данных. Обеспечены следующие функциональные особенности:
идентификатор генерируется по стандарту UUID;
метаданные от сервера витрины кешируются механизмом, и проверяются на соответствие по количеству и по типам полей (при несоответствии загружаемых данных метаданным целевой таблицы сервис для передачи / загрузки данных возвращает статус запроса с ошибкой, без размещения данных в очереди на загрузку);
загруженные данные размещаются вместе с UUID в очереди с именем «queue»;
формируется запись с ключом «status.[UUID запроса]» и статусом 0 в очереди;
клиенту, отправившему запрос, возвращается успешный статус запроса вместе с UUID;
в логе приложения формироваться запись события получения запроса на загрузку с указанием идентификатора запроса, идентификатора ВУЗа, времени обработки и размера загруженных данных.
Методы интерфейса rest-uploader:
http://host:port/v1/datamarts/{datamart_name}/tables/{table_name}/upload - загрузка данных в витрину;
http://host:port/v1/requests/{request}/status - получение статуса запроса.
6.2.20.2. Архитектура технического решения по реализации асинхронной загрузки данных из источников по REST
Для реализации асинхронной загрузки данных из источников по REST была реализована архитектура, показанная на Рисунок - 6.64
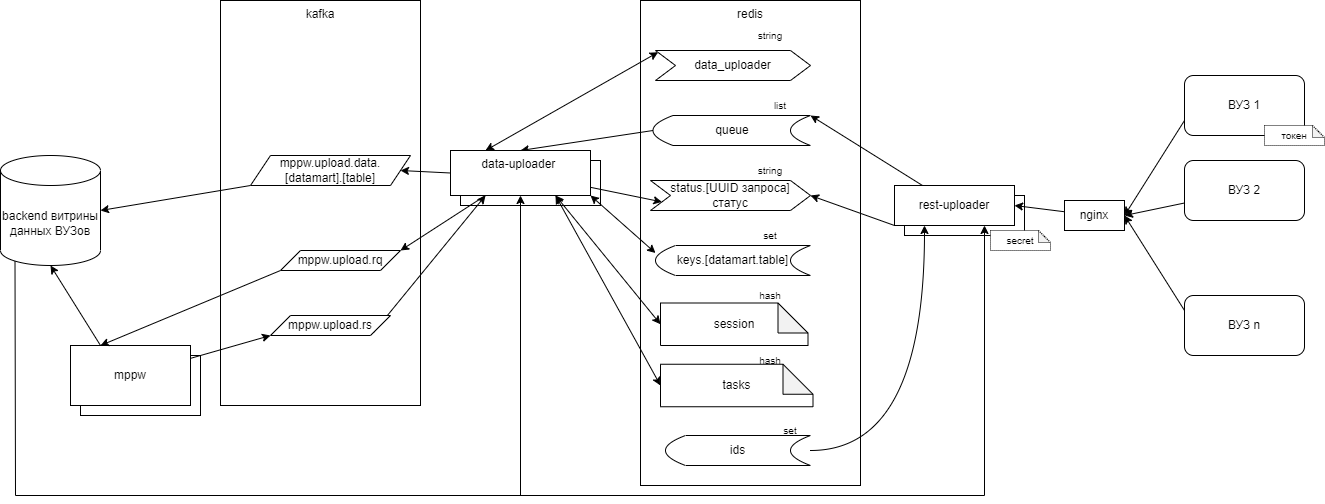
Рисунок - 6.64 Архитектура асинхронной загрузки данных из источников по REST
6.2.20.2.1. Описание технического решения по реализации получения статуса асинхронного задания по REST-интерфейсу
В рамках выполненных работ реализован механизм получения статуса асинхронного задания по REST-интерфейсу, который обеспечивает следующие функциональные особенности:
для получения статуса асинхронного задания со стороны ВУЗа выполняется GET-запрос, с HTTP заголовком аутентификации и токеном авторизации;
сервис для передачи данных проверяет полученный токен авторизации:
в случае некорректного токена возвращается статус с ошибкой;
при корректном токене определяется значение из записи статуса по ключу идентификатора запроса и возвращается успешный код ответа и статус запроса в теле ответа в формате «[статус]:[описание]»
если запись не обнаружена, присваивается соответствующий статус.
Реализованы статусы для следующих событий:
0 – запрос буферизирован;
1 – ожидает открытия дельты;
2 – в обработке;
3 – успешно обработан;
4 – ошибка обработки запроса;
5 – идентификатор не обнаружен.
6.2.20.2.2. Описание технического решения временного хранилища данных
Для загрузки данных витрину в качестве временного хранилища данных используется СУБД Redis. В рамках выполненных работ был добавлен лист с именем QUEUE, агрегирующий загружаемые данные для временного хранения.
6.2.20.2.3. Описание технического решения обработки очереди файлов при помощи модуля исполнения асинхронных заданий
В рамках выполненных работ реализован модуль исполнения асинхронных заданий, который обеспечивает обработку очереди файлов, используя следующие функциональные особенности:
обработка очереди файлов производится циклами;
очередь файлов работает в режиме упорядочения процесса по принципу «первым пришел – первым обслужен» (FIFO);
каждый элемент в очереди файлов содержит UUID задания, имя витрины и таблицы, содержимое CSV-файла;
файлы в очереди могут относится к разным витринам и/или разным таблицам одной витрины.
Для наглядности на Рисунок - 6.65 представлена диаграмма последовательности обработки запросов на загрузку данных.
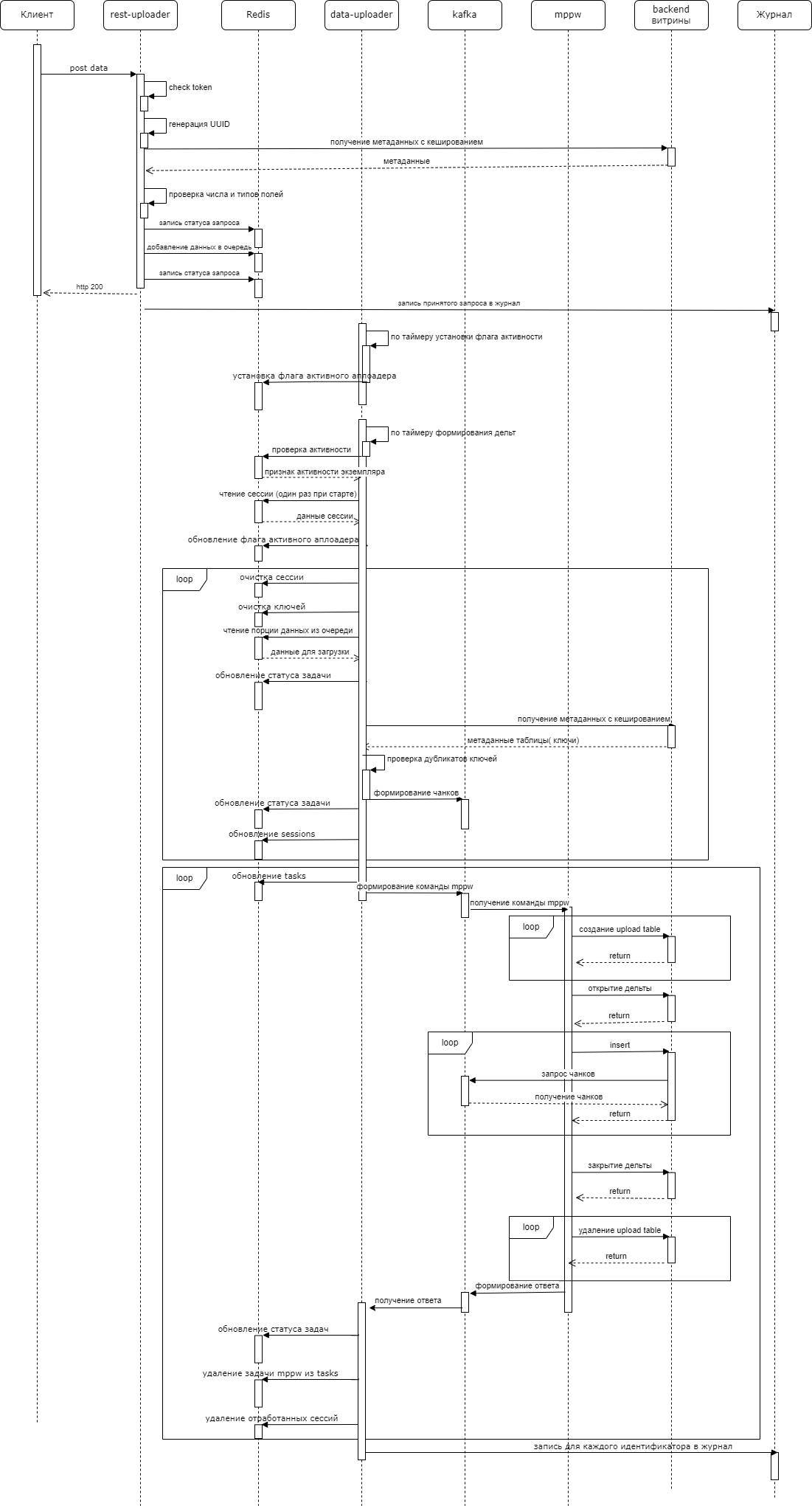
Рисунок - 6.65 Диаграмма последовательности обработки запросов на загрузку данных
6.2.20.3. Описание технического решения работы активного экземпляра модуля исполнения асинхронных заданий
Возможно существование нескольких экземпляров модулей, но из всех запущенных экземпляров в активном режиме может быть не более одного. Реализована настройка периодичности попыток перехода в активный режим каждого экземпляра. При попытке перехода в активный режим:
при запуске экземпляр генерирует UUIDv4 (идентификатор экземпляра);
устанавливает значение ключа data_uploader (только при его отсутствии) равным UUID экземпляра с указанной длительностью жизни;
если установить значение не удается, то экземпляр переходит в активный режим, в случае если значение ключа удалось установить, то экземпляр остается в неактивном режиме и повторяет попытку переключение через заданное время.
Находясь в активном режиме, экземпляр модуля с заданным интервалом подтверждает свою активность, считывая текущее значение ключа data_uploader. При отсутствии ключа, или если содержимое ключа отличается от сгенерированного при запуске экземпляра, экземпляр переходит в неактивный режим и совершает попытки перейти в активный режим. При наличии ключа экземпляр модуля продлевает свою активность.
На Рисунок - 6.66 показана диаграмма работы активного экземпляра модуля исполнения асинхронных заданий.
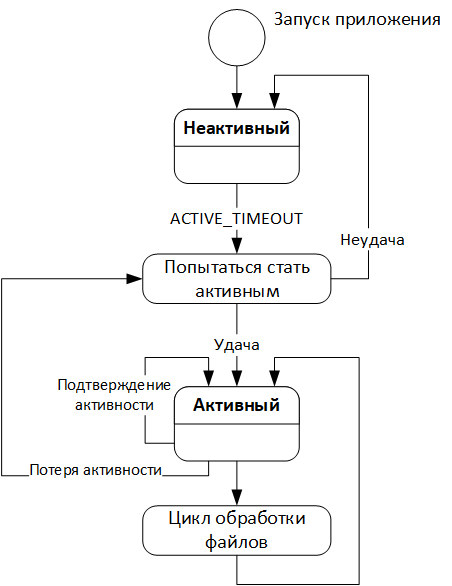
Рисунок - 6.66 Диаграмма работы активного экземпляра модуля исполнения асинхронных заданий
6.2.20.4. Описание технического решения цикла обработки файлов
В активном режиме экземпляр модуля исполнения асинхронных заданий начинает исполнение цикла обработки файлов.
На Рисунок - 6.67 отображена диаграмма работы основного цикла обработки файлов.
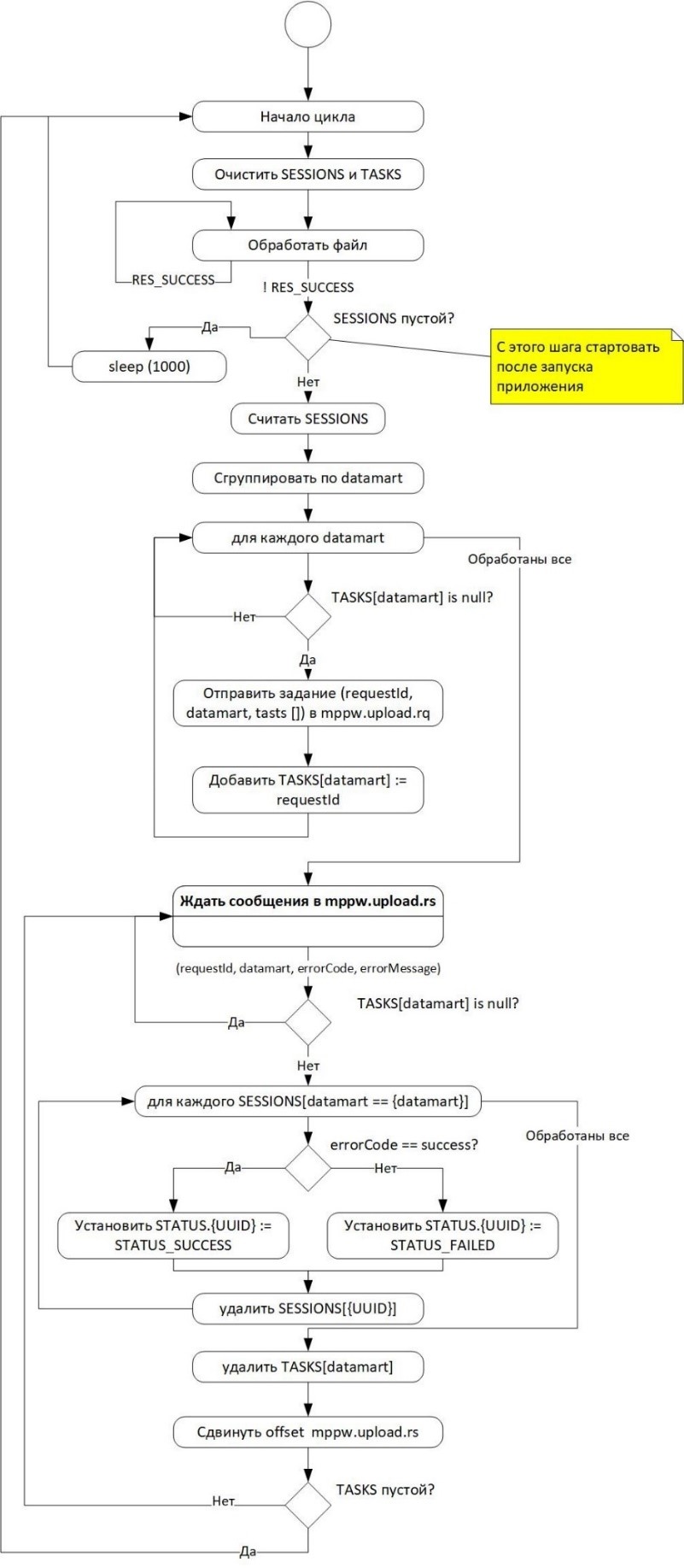
Рисунок - 6.67 Диаграмма работы основного цикла обработки файлов
Обработка очереди файлов производится циклами:
из очереди последовательно считываются файлы;
содержимое каждого файла делиться на составные части;
части помещаются в очередь MPPW;
чтение из очереди файлов прекращается;
подаются команды модулю MPPW на запись дельт для каждой из витрин, к таблицам которой относились считанные файлы;
дожидаются от MPPW исполнение всех поданных заданий.
После исполнения всех поданных заданий цикл повторяется.
Очередь файлов работает в режиме упорядочения процесса по принципу «первым пришел – первым обслужен».
В очереди файлов каждый элемент содержит:
UUID задания;
имя витрины и таблицы;
содержимое CSV-файла.
Подряд идущие в очереди файлы могут относиться к разным витринам и/или разным таблицам одной витрины.
В рамках одного цикла считывание файлов из очереди производится до первого наступления хотя бы одного из условий:
очередь файлов пуста;
с момента первого считанного (в рамках этого цикла) файла из очереди прошло более заданного времени;
в рамках этого цикла обработано не менее заданного количества строк;
в обрабатываемом файле встретилась строка, содержащая значение первичного ключа, уже встречавшееся в рамках этого цикла для этой таблицы этой витрины.
Значения первичных ключей, обработанных в рамках этого цикла, накапливается в списках с именами KEYS.{имя витрины}.{имя таблицы}. Если первичный ключ составной, то используется конкатенация значений составляющих его полей, разделенных символом «_». Поля объединяются в порядке, указанном в метаданных целевой таблицы витрины.
Вычитывание файлов из очереди должно производиться по одному в соответствии с очередностью попадания файла в очередь.
Если значение в ключе с именем STATUS.{UUID} (UUID - номер задания из считанного файла) равно STATUS_FAILED, то файл не обрабатывается и пропускается.
Перед обработкой файла устанавливается значение в ключе с именем STATUS.{UUID} (UUID - номер задания из считанного файла) равным STATUS_PROCESSING.
В одну часть MPPW могут помещаться строки только из одного файла. Добавление строк файла в часть MPPW прерывается при выполнении хотя бы одного из условий:
больше нет записей в файле;
количество строк в части больше заданного;
с момента первого считанного (в рамках этого цикла) файла из очереди прошло более заданного количества секунд;
в рамках этого цикла обработано не менее заданного количества строк;
в обрабатываемом файле встретилась строка, содержащая значение первичного ключа, уже встречавшееся в рамках этого цикла для этой таблицы этой витрины.
После успешной обработки файл удаляется из очереди.
При прерывании добавления строк файла в часть MPPW заменить в начале списка исходный (полный) файл на его необработанный остаток (не забыв строку заголовка).
Части с данными (из CSV-файлов) для MPPW помещаются в топики Kafka с именем, созданным по шаблону:
mppw.upload.data.{имя витрины}.{имя таблицы}
На этапе отправки заданий в MPPW группируются все элементы множества SESSIONS с одинаковым именами витрин и для каждой такой группы. При этом данному заданию присваивается уникальный UUIDv4. Задание отправляется с атрибутами:
UUIDv4;
имя витрины;
список с именами таблиц.
В хэш-таблицу хранилища данных добавляется значение UUIDv4 с ключом datamart.
На Рисунок - 6.68 показана схема процедуры обработки одного файла.
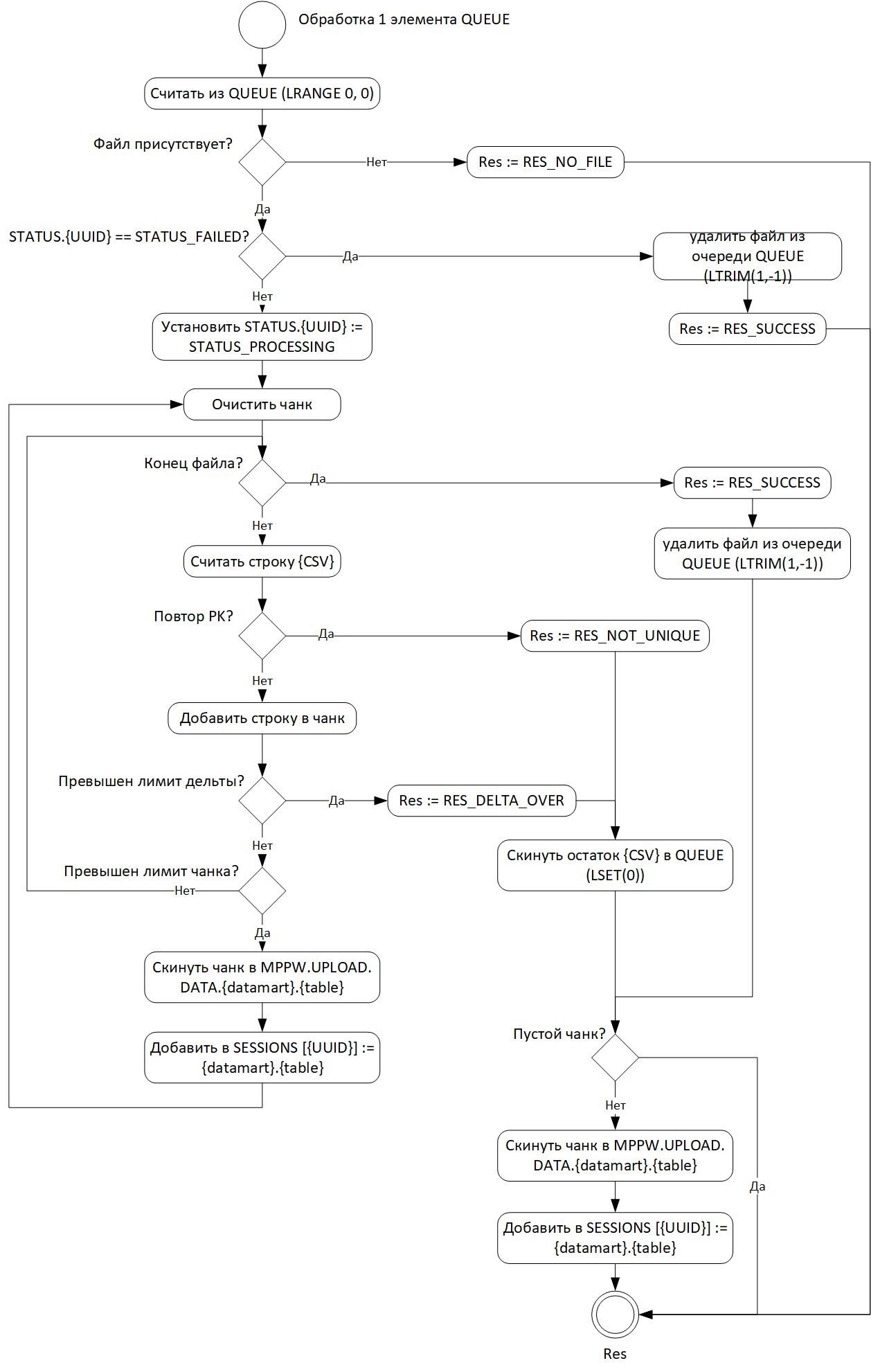
Рисунок - 6.68 Схема процедуры обработки одного файла
6.2.20.4.1. Особенности и ограничения
Архитектура модуля загрузки данных в витрину из внешних источников имеет следующие функциональные особенности и ограничения:
однопоточная загрузка данных из буфера в витрину;
работа по загрузке данных происходит в защищенном контуре, защита от перехвата токенов на сетевом оборудовании не реализована;
размер загружаемого файла в одном запросе не должен превышать 512 Мб, ограничение обусловлено работой хранилища данных.
6.2.21. Кластеризация модулей витрин данных
В рамках выполненных работ необходимо кластеризовать модули Типового ПО витрины данных для обеспечения отказоустойчивости, горизонтального масштабирования и оптимизации использования ресурсов.
В рамках данного требования были выполнены следующие работы:
доработаны 8 модулей слоя сервисов адаптеров и 2 модуля исполнения запросов ядра Prostore в Типовом ПО витрины данных в соответствии с ранее разработанными требованиями к кластеризации модулей витрины данных;
контейнеризированы доработанные 10 модулей Типового ПО витрины данных.
6.2.21.1. Описание технического решения по доработке 8 модулей слоя сервисов адаптеров
Управление экземплярами модулей адаптеров выполняет специализированный контроллер управления модулями адаптеров витрины.
Контроллер отслеживает для каких арендаторов, и для каких витрин запущены экземпляры модулей адаптеров, анализирует нагрузку на них и принимает решения о запуске/остановке экземпляров.
Все модули адаптеров, которые запускаются как докер контейнеры необходимо снабжать метками, идентифицирующими назначение, арендатора и витрину. Это позволяет универсализировать подход к мониторингу и учету утилизации ресурсов. Оснащение экземпляров метками позволяет быстро получить информацию о статусе экземпляров определенного типа или о статусе экземпляров, обслуживающих запросы к определенной витрине.
Использование одного контроллера для всех арендаторов позволяет упростить подключение новых арендаторов и конфигурирование множества адаптеров. Ключевым показателем оценки утилизации экземпляров модулей витрины принимается процент утилизации CPU.
Запуск и остановка экземпляров модулей адаптеров может приводить к частому ребалансу Kafka, что может повлечь
снижение производительности на время переходного процесса. С целью снижения эффекта остановки консьюминга сообщений
на время ребаланса, необходимо использовать стратегию ребаланса partition.assignment.strategy=CooperativeStickyAssignor.
Взаимодействие экземпляров модулей витрины данных и контроллера управления модулями отражено в виде диаграммы на Рисунок - 6.69 (на примере модуля исполнения запросов и модуля mppr).
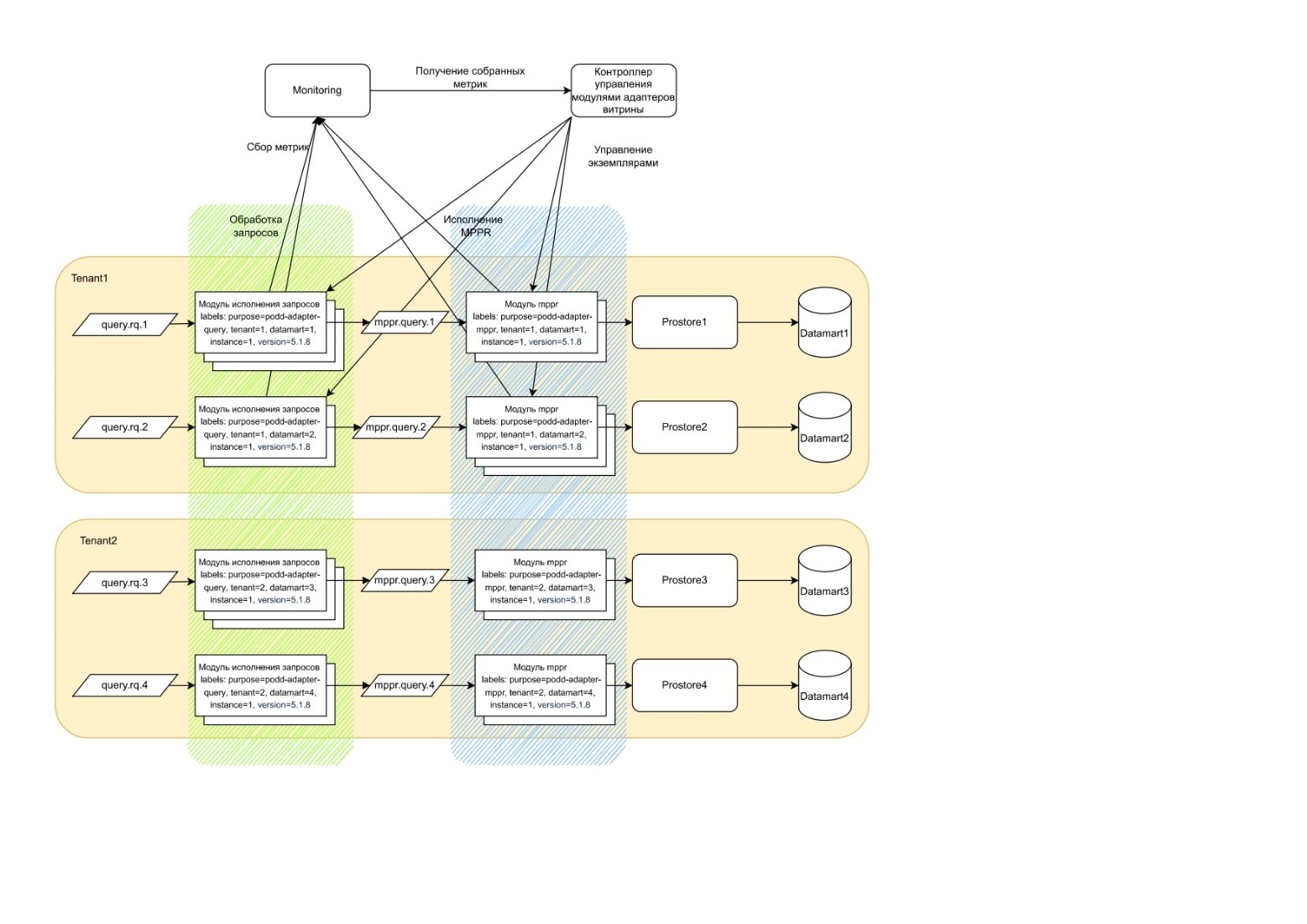
Рисунок - 6.69 Взаимодействие экземпляров модулей витрины данных и контроллера управления модулями
6.2.21.2. Реализация доработки 8 модулей слоя сервисов адаптеров
В рамках выполненных работ были доработаны модули слоя адаптеров витрины:
модуль исполнения запросов;
модуль MPPR;
модуль MPPW;
модуль подписок;
модуль импорта табличных параметров;
модуль группировки частей табличных параметров;
модуль сервиса формирования документов;
адаптер SMEV3.
В рамках кластеризации используются следующие сервисы и приложения:
Среда контейнеризации Kubernetes;
Брокер сообщений Kafka совместно с Zookeeper вне Kubernetes;
Сервис мониторинга Prometheus/Grafana;
СУБД ADB;
Jmeter;
Fluentbit в виде дополнительного контейнера узла, только для модуля исполнения запросов;
HaProxy;
Vector;
ClickHouse.
В рамках выполненных работ реализована следующая функциональность:
горизонтальное масштабирование Сервиса исполнения запросов;
демонстрация влияния количества экземпляров сервиса на утилизацию оборудования конкретным экземпляром;
демонстрация влияния количества экземпляров сервиса на производительность Витрины данных.
В рамках доработки модуля исполнения запросов решено использовать groupId=f(имя топика). Например, hex(MD5(upcase(имя топика))) Данное решение позволяет избежать проблемы ребалансировки всех консьюмеров всех витрин при поднятии/снятии экземпляра адаптера для одной витрины, поскольку все экземпляры Модуля используют единый константный groupId при работе с топиком QUERY.RQ. В одну группу должны входить только консьюмеры, между которыми должна производиться ребалансировка.
В рамках доработки модуля MPPR:
обеспечено использование уникальных имен топиков для выгрузки данных из ProStore (результат mppr-запросов);
шаблон для запроса:
mppr.datamart.table.subrequestIdшаблон для подписки:
mppr.datamart.table.requestId.synIdобеспеченны уникальные имена download external таблиц;
вынесен в настройки топик получения уведомлений от Простора об изменениях логической модели (status.event);
вынесены в настройки имена топиков получения заданий от модуля исполнения запросов и от модуля ТП;
вынесены в настройки имена консьюмеров для топиков заданий от модуля исполнения запросов и от модуля ТП;
вынесены в настройки имена консьюмеров для топиков выгрузки чанков;
обеспечены многопартиционные топики
mppr.query,mppr.subscription, допустимо число партиций больше чем возможное число экземпляров модуля MPPR. Для сбаланированной нагрузки число партиций должно быть кратным числу экземпляров.
В рамках доработки модуля MPPW для табличных параметров:
осуществлен переход на standalone таблицы;
обеспечены уникальные имена топиков;
обеспечены уникальные имена upload external table;
обеспечено число партиций топика
mppw.tp.
Для подписок:
обеспечено число партиций топика
mppw.delta;решена ошибка с повторно используемым именем топика при загрузке в ADG.
В рамках доработки модуля подписок внесены обновления:
реализована работа zookeeper с учетом конкурентной среды;
реализована работа всех экземпляров модуля с топиками
delta.rqпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками
delta.inпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками
replication.rqпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками
replication.in.rqпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками
replication.cancel.rqпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками
tp.upload.errпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками
tp.upload.in.errпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками
delta.notification.inпод единым consumerGroupId, задаваемым через конфигурацию;реализована работа всех экземпляров модуля с топиками topicS под единым consumerGroupId, задаваемым через конфигурацию.
В рамках доработки модуля импорта табличных параметров реализовано:
обеспечение уникальных имен внешних таблиц на чтение и запись;
адаптация имен таблиц в запросе к новым уникальным именам;
многопартиционные топики
tp.upload.query,mppw.tp.rs,tp.delete.tmp;группы консьюмеров разведены на разные группы;
подписка на топик
cancel.rqдля каждого экземпляра под своим уникальным group_id (для всех модулей).
В рамках доработки модуля группировки чанков табличных параметров обеспечено нужное число партиций в топике kafka query.tp.
В рамках доработки сервиса формирования документов (сервис ФД) обеспечивается балансировка http-запросов перед сервисом ФД.
В рамках доработки адаптера СМЭВ3 реализовано отсутствие хранения состояния (stateless сервис). Хранение состояния вынесено в zookeeper.
В рамках выполненных работ отлажена балансировка нагрузки между экземплярами модуля хранения данных.
Для проверки балансировки запросов:
топик
query.rqдолжен содержать более одной партиции;серия запросов направленных к
query.rqдолжна быть распределена между экземплярами модулей исполнения запросов и экземплярами query-execution-core;в логах обоих экземпляров модулей исполнения запросов должны быть записи об обработке запросов;
в логах обоих экземпляров query-execution-core должны быть записи об обработке запросов.
Взаимодействие компонент при исполнении запросов LLR представлено в виде диаграммы на Рисунок - 6.70
Рисунок - 6.70 Взаимодействие компонент при исполнении запросов LLR
Взаимодействие компонент при исполнении запросов MPPR представлено в виде диаграммы на Рисунок - 6.71
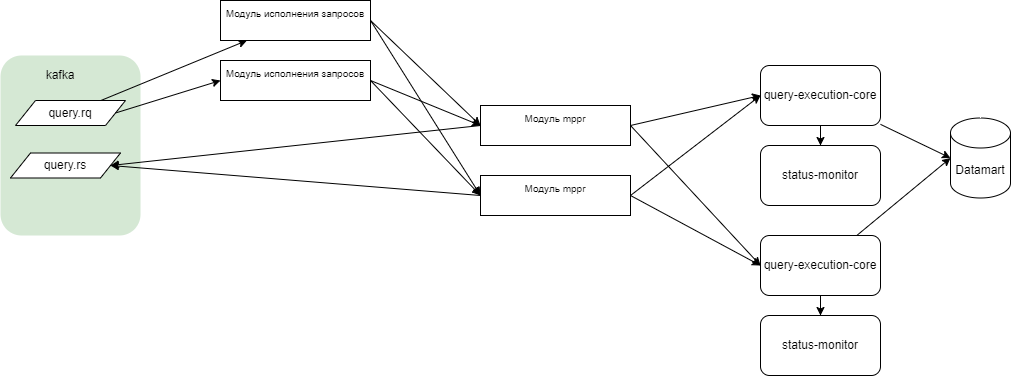
Рисунок - 6.71 Взаимодействие компонент при исполнении запросов MPPR
Взаимодействие компонент при передаче данных по подпискам представлено в виде диаграммы на Рисунок - 6.72
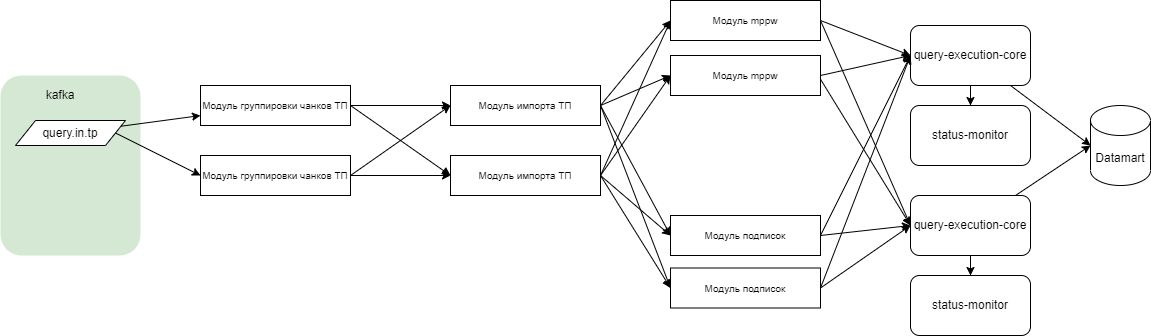
Рисунок - 6.72 Взаимодействие компонент при передаче данных по подпискам
Взаимодействие компонент при запросе к сервису формирования документов представлено в виде диаграммы на Рисунок - 6.73

Рисунок - 6.73 Взаимодействие компонент при запросе к сервису формирования документов
6.2.21.2.1. Описание технического решения по доработке 2 модулей сервиса исполнения запросов ядра Prostore
В рамках выполненных работ были доработаны модули исполнения запросов ядра Prostore:
ядро Prostore;
статус монитор.
Было реализованы следующие технические решения:
возможность поддерживать работу кластеризованного сервиса исполнения запросов из двух и более узлов с экземплярами сервиса исполнения запросов;
возможность добавлять в конфигурацию сервиса исполнения запросов узел с экземпляром сервиса исполнения запросов;
возможность удалять из конфигурации сервиса исполнения запросов узел экземпляром сервиса исполнения запросов.
6.2.21.3. Описание технического решения по поддержке работы кластеризованного сервиса исполнения запросов из двух и более узлов с экземплярами сервиса исполнения запросов
В рамках технического решения для типового ПО «Витрина данных НСУД» были проведены следующие работы:
реализация режима асинхронного взаимодействия узла кластеризованного сервиса исполнения запросов с общими компонентами;
реализация архитектуры кластеризованного сервиса исполнения запросов c выделенным узлом для изменения информационной схемы, отката дельт, синхронизации материализованных представлений и сбора статистики через счетчик, выполняемых в штатном порядке.
6.2.21.4. Реализация режима асинхронного взаимодействия узла кластеризованного сервиса исполнения запросов с общими компонентами
Реализация режима асинхронного взаимодействия узла кластеризованного сервиса исполнения запросов с общими компонентами была выполнена в ходе следующих работ:
реализация режима асинхронного взаимодействия узла кластеризованного сервиса исполнения запросов со служебной БД;
реализация режима асинхронного взаимодействия узла кластеризованного сервиса исполнения запросов с хранилищем;
реализация режима асинхронного взаимодействия узла кластеризованного сервиса исполнения запросов с брокером сообщений.
Для поддержания асинхронного взаимодействия узла кластеризованного сервиса исполнения запросов была реализована архитектура, приведенная на Рисунок - 6.74.
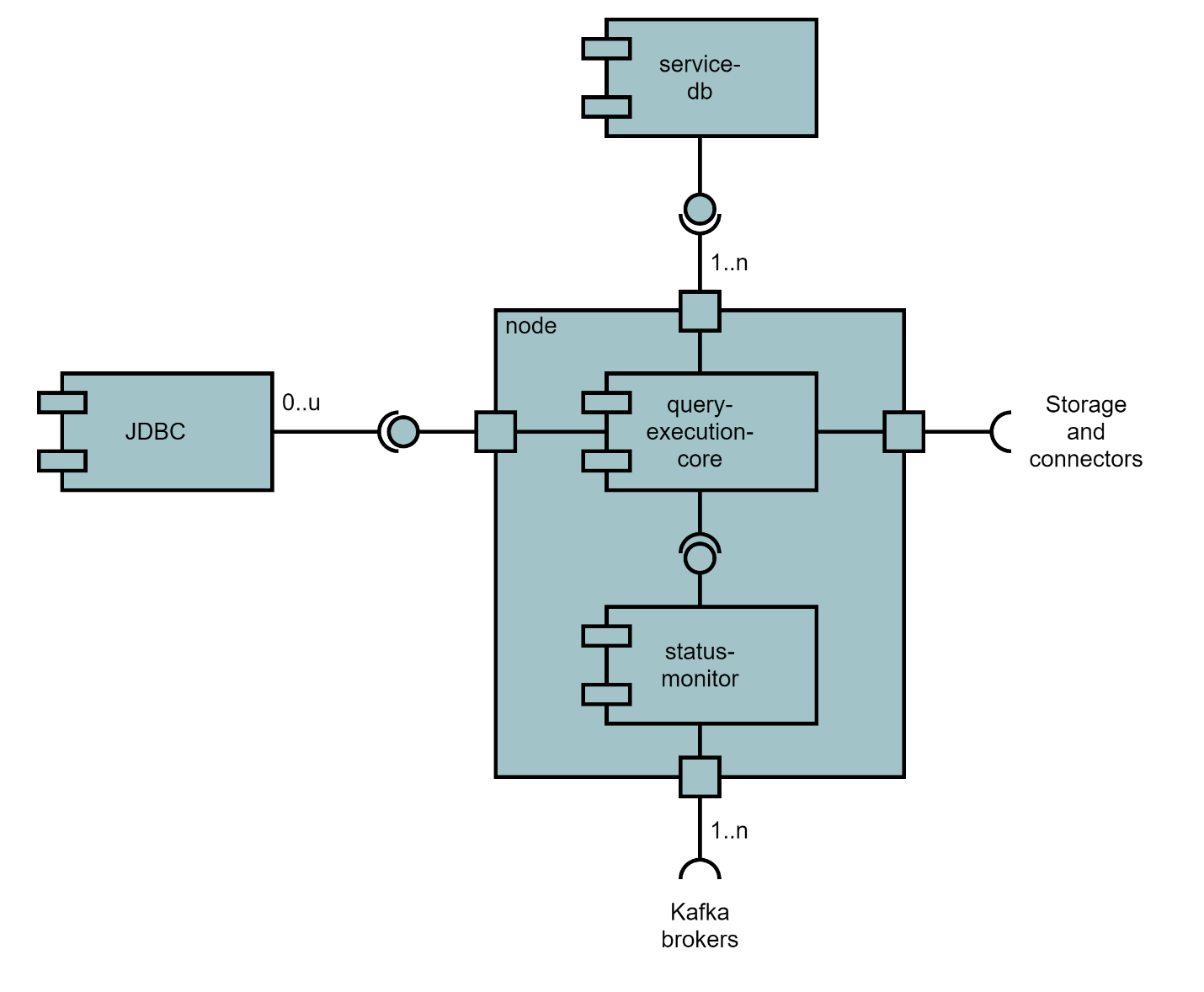
Рисунок - 6.74 Архитектура узла кластеризованного сервиса исполнения запросов
Все узлы кластеризованного сервиса исполнения запросов являются архитектурно одинаковыми. Каждый узел содержит два модуля, а именно:
модуль ядра сервиса исполнения запросов;
модуль статус-монитора.
Модуль ядра сервиса исполнения запросов обрабатывает входные запросы, получаемые от внешнего пользователя через одно из подключений JDBC-драйвера, и по результатам работы взаимодействует с общими компонентами.
Узел кластеризованного сервиса исполнения запросов обращается к служебной БД с целью взаимодействия с информационной схемой путём запросов на языке HSQL. Взаимодействие осуществляется асинхронно, а обеспечение асинхронности делегируется служебной СУБД.
Узел кластеризованного сервиса исполнения запросов взаимодействует с общим хранилищем через набор модулей-коннекторов, обеспечивающих подключение к соответствующим СУБД. Взаимодействие осуществляется асинхронно, а обеспечение асинхронности делегируется тем СУБД хранилища, к которым происходит обращение.
Узел кластеризованного сервиса исполнения запросов взаимодействует с общим брокером сообщений Kafka через модуль статус-монитора. Взаимодействие осуществляется асинхронно с помощью соответствующего модуля-коннектора, а обеспечение асинхронности делегируется брокеру сообщений Kafka.
В ходе выполнения работ реализована архитектура кластеризованного сервиса исполнения запросов, организованная из узлов сервиса исполнения запросов по сетевой топологии типа звезда. Архитектура кластеризованного сервиса представлена на Рисунок - 6.75.
Рисунок - 6.75 Архитектура кластеризованного сервиса с топологией типа звезда
В реализованной архитектуре тип узла с сервисом исполнения запросов (выделенный/невыделенный) определяется следующими настройками конфигурационного файла сервиса исполнения запросов на этом узле:
интервал синхронизации материализованных представлений ${MATERIALIZED_VIEWS_SYNC_PERIOD_MS: 0}. Положительное значение для выделенного узла, нулевое значение для невыделенных узлов;
сбор статистики через счетчик ${сбор каунтов в статистике:false}. Значение ИСТИНА для выделенного узла, значение ЛОЖЬ для невыделенных узлов.
6.2.21.5. Описание технического решения по добавлению в конфигурацию сервиса исполнения запросов узла с экземпляром сервиса исполнения запросов
Кластеризованный сервис исполнения запросов может быть расширен путем добавления узла в текущую конфигурацию функционирующего кластера без приостановки его работы. Добавление узла представляет собой типовой запуск нового экземпляра модуля ядра сервиса исполнения запроса и модуля статус-монитора. При этом конфигурационные файлы новых экземпляров модулей должны быть такими же, как и конфигурационные файлы экземпляров соответствующих модулей, уже запущенных на невыделенных узлах кластера. В частности, в этих конфигурационных файлах должны быть указаны одинаковые настройки соединений с общими компонентами кластера.
Следует отметить, что в кластеризованном сервисе исполнения запросов не ведётся специального учета количества подключенных узлов.
6.2.21.6. Описание технического решения по удалению из конфигурации сервиса исполнения запросов узла с экземпляром сервиса исполнения запросов
Кластеризованный сервис исполнения запросов может быть сокращен путем удаления узла из текущей конфигурации функционирующего кластера без приостановки его работы. Удаление узла представляет собой типовую остановку в нём экземпляра модуля ядра сервиса исполнения запроса и модуля статус-монитора. При этом для сохранения полной функциональности кластера допускается удаление только невыделенного узла. В противном случае, штатный вызов операций изменения информационной схемы, отката дельт, синхронизации материализованных представлений и сбора статистики через счетчик будет недоступен.
6.2.21.6.1. Описание технического решения по контейнеризации доработанных 10 модулей Типового ПО витрины данных
В рамках выполненных работ реализована возможность вызова сторонних библиотек.
Каждый модуль оформлен как докер образ, что позволяет минимизировать сложности по добавлению и подготовке серверов, предназначенных для развертывания экземпляров модулей.
Ограничение ресурсов конкретного экземпляра осуществляется на уровне лимитов контейнеров.
Каждый контейнер модуля содержит драйверы нескольких версий. Для выбора версии драйвера при запуске контейнера используется
entrypoint.sh. JDBC драйвер вызывается основным модулем.
Использование докер контейнеров позволяет приоритезировать экземпляры модулей и соответственно приоритезировать базы данных.
Каждый докер контейнер должен отмечаться системой из шести меток, определяющих тип модуля, версию модуля, арендатора, витрину,
номер экземпляра и имя сервера, на котором запущен экземпляр.
Модули, предназначенные для обработки запросов к конкретной базе данных, должны помечаться меткой, например datamart=registration.
Так же специализированными метками нужно отмечать экземпляры каждого модуля, работающих по БД арендатора, например tenant=vedomstvo1.
Метка purpose, соответствующую типу модуля, задается на этапе сборки докер образа. Значения метки purpose для модулей адаптера витрины данных приведены ниже в Таблица 6.16, описывающей состав модулей адаптеров витрины данных.
Наименование модуля |
statefull/stateless |
Что требуется для обеспечения кластеризации |
Значение метки назначения purpose |
|---|---|---|---|
ПОДД модуль исполнения запросов |
stateless |
Требуется обеспечить нужное число партиций к топиках kafka query.*,report.* (metadata.newdata, statistics.rq) |
podd-adapter-query |
ПОДД MPPR |
stateless |
Требуется обеспечить нужное число партиций к топикам kafka mppr.query, mppr.subscription |
podd-adapter-mppr |
ПОДД MPPW |
statefull |
Требуется обеспечить нужное число партиций к топиках kafka mppw.delta.in.rq, mppw…. |
podd-adapter-mppw |
ПОДД модуль подписок |
statefull |
podd-adapter-replicator |
|
ПОДД модуль импорта табличных параметров |
statefull |
podd-adapter-import-tp |
|
ПОДД модуль группировки чанков табличных параметров |
stateless |
Требуется обеспечить нужное число партиций к топике kafka query.tp |
|
Сервис Формирования документов |
stateless |
Требуется дополнительный балансировщик перед сервисом ФД |
|
Адаптер Смев3 |
stateless (сохранение состояния по подпискам вынесено в zookeeper) |
smev3-adapter |
Версия модуля адаптера витрины данных помечается в метке version, например version=5.1.8
Для обозначения номера экземпляра используется метка instance, а метка server используется для информирования на каком сервере работает данный экземпляр.
Ключевым показателем оценки утилизации экземпляров модулей витрины принимается процент утилизации CPU. В качестве целевого значения показателя утилизации процессора рекомендуется использовать 50-85%. Меньший уровень целевой утилизации обеспечивает дополнительный запас мощности за счет упреждающего старта экземпляров. Повышенный уровень целевой утилизации позволит быстрее останавливать экземпляры модулей и приведет к более интенсивному высвобождению ресурсов при снижении нагрузки на витрину.
6.2.21.6.2. Особенности и ограничения
Архитектура кластеризованного сервиса исполнения имеет следующие функциональные особенности и ограничения:
отсутствие ведущего узла;
отсутствие встроенного сервиса балансировки нагрузки между узлами;
отсутствие поддержки мгновенно консистентных логических представлений одних таблиц на разных узлах;
для всех узлов должно быть выключена настройка автоматического восстановления состояния ${AUTO_RESTORE_STATE: false};
необходимость в наличии выделенного узла для изменения информационной схемы, отката дельт и синхронизации материализованных представлений, сбора статистики через счетчик;
необходимость запретов на изменение информационной схемы, откат дельт и синхронизацию материализованных представлений, сбор статистики через счетчик для невыделенных узлов;
отсутствие видимости внешних таблиц чтения и записи в информационной схеме.
6.2.22. Генерация номера отчета в сервисе печатных форм
В целях обеспечения возможности единого учёта и идентификации документов (печатных форм, отчётов, выписок), сформированных на основании данных витрины, была реализована функция создания уникальных номеров в сервисе формирования документов (сервис печатных форм Типового ПО витрины данных).
В рамках данного требования были выполнены следующие работы:
реализована функция расширения pebble-шаблона;
реализовано долговременное хранение неограниченного списка счетчиков (проведено регрессионного тестирования модуля для выявления дефектов работоспособности с новым окружением);
реализовано атомарное изменение счетчика при параллельном использовании этой функции (взаимодействие с внешними, по отношению к модернизируемой ИС, системами, находящимися в контуре ИЭП - синхронное взаимодействие pebble-расширения с сервисом счетчика: zookeeper);
реализована передача дополнительной информации по параметрам печатных форм из ПОДД в Витрину.
6.2.22.1. Схема взаимодействия технического решения
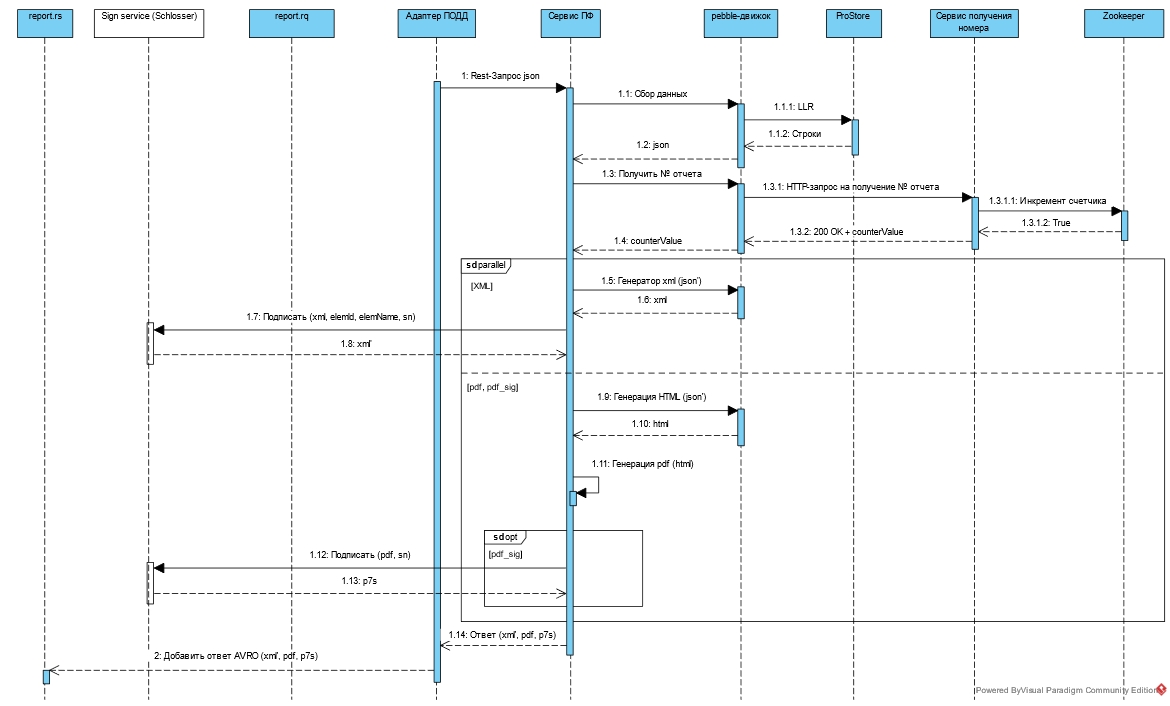
Рисунок - 6.76 Схема взаимодействия между компонентами Витрины
6.2.22.2. Описание технического решения по реализации функции расширения peeble-шаблона
В рамках выполнения работ по реализации функции расширения pebble-шаблона при осуществлении инкремента на стороне сервиса Pebble был реализован следующий функционал:
Реализовано новое расширение pebble
GetCounterExtension, которое наследует классAbstractExtension. Расширение вызывает по REST API сервис для изменения и получения номера отчета и далее подставляет в результат pebble.Доработка конфигурации Pebble (PebbleConfig.java) новым расширением
GetCounterExtension.Реализация отдельного шаблона для номера печатной формы.
Расширение шаблонов
generate_pdf_1.pebиgenerate_xml_1.pebполем, содержащим номер отчета.
6.2.22.3. Описание технического решения по реализации функции долговременного хранения неограниченного списка счетчиков
В рамках выполнения работ по реализации функции долговременного хранения неограниченного списка счетчиков был реализован следующий функционал:
Реализован сервис получения номера печатных форм;
Проведена инициализация произвольного счетчика.
Осуществлено обнуление произвольного счетчика.
6.2.22.4. Описание технического решения по реализации сервиса получения номера печатных форм
Реализован сервис получения номера печатных форм с интерфейсом GET /api/{service}/number.
openapi: 3.0.0
x-stoplight:
id: 1fmc89z7l5xho
info:
title: CounterService
version: '1.0'
description: API сервиса получения номера для ПФ
contact:
name: Vsevolod Pashkin
email: vpashkin@it-one.ru
servers:
- url: 'http://localhost:3000'
paths:
'/api/{service}/number/{counter}':
parameters:
- schema:
type: string
name: service
in: path
required: true
description: Название сервиса
- schema:
type: string
name: counter
in: path
required: true
description: Название счетчика
get:
summary: Получение уникального номера
tags:
- CounterService
responses:
'200':
description: OK
content:
application/json:
schema:
$ref: '#/components/schemas/CounterServiceResponseForm'
'400':
description: Bad Request
operationId: get-api-service-number-counter
description: Запрос на получение номера счетчика
parameters: []
components:
schemas:
CounterServiceResponseForm:
title: CounterServiceResponseForm
x-stoplight:
id: lxvd969jw2kuw
type: object
properties:
service:
type: string
description: Название сервиса
name:
type: string
description: Название счетчика
number:
type: integer
description: Номер
required:
- service
- name
- number
tags:
- name: CounterService
6.2.22.5. Описание технического решения по инициализации произвольного счетчика
Стартовое значение при инициализации любого счетчика определяться конфигурационным параметром клиента COUNTER_START_NUMBER.
6.2.22.6. Описание технического решения по обнулению произвольного счетчика
В рамках выполнение работ по реализации функции долговременного хранения неограниченного списка счетчиков было
реализовано периодическое обнуление счетчика. Периодичность определяется конфигурационным параметром
клиента COUNTER_RESET_PERIOD.
- После выполнения работ по реализации функции долговременного хранения неограниченного списка счетчиков было проведено
регрессионное тестирование модуля для выявления дефектов работоспособности с новым окружением.
6.2.22.6.1. Описание технического решения по реализации атомарного изменения счетчика при параллельном использовании этой функции
В рамках выполнения работ по реализации атомарного изменения счетчика при параллельном использование этой функции был реализован следующий функционал:
операция инкремента счетчика;
повторение попытки инкремента счетчика.
6.2.22.7. Операция инкремента счетчика
С целью функционирования операции инкремента счетчика была реализована функция атомарного изменения счетчика, которая содержит блокировку исполнения части кода. Если во время выполнения операции инкремента счетчика версия узла была изменена, то производится повторение попытки инкремента счетчика.
6.2.22.8. Повторение попытки инкремента счетчика
Для корректной работы функции инкремента была реализована функция повторного изменения инкремента счетчика после проверки версионирования. Функция определяется следующими конфигурационными параметрами:
количество повторений
COUNTER_RETRY_AFTER_FAILURE;время засыпания
COUNTER_UPDATE_TIMEOUT.
6.2.22.8.1. Описание технического решения по реализации передачи дополнительной информации по параметрам печатных форм из ПОДД в Витрину
- В рамках выполнения работ по реализации передачи дополнительной информации по параметрам печатных форм из ПОДД в
Витрину реализована передача названия счетчика в запросе на формирование документа из ПОДД в Витрину.
В атрибуте parameters запроса на формирование документа в топик report.rq содержится отдельное поле counter
типа string, содержащее информацию о счетчике, из которого необходимо получить уникальный номер.
6.2.22.8.2. Описание технического решения по обеспечению конкурентной записи (инкремент счетчика) в многопоточном режиме
В рамках выполнения работ реализована конкурентную запись (инкремент счетчика) в многопоточном режиме. При настройке счетчиков в Zookeeper была обеспечена защита от конкурентной записи за счет версионирования узлов Zookeeper.
Проблема конкурентного доступа в Zookeeper решена по схеме «сравнить и заменить»: каждому узлу Zookeeper
соответствует его версия, которая указывается при изменении узла. В случае изменения узла его версия
изменяется, при этом клиент получает соответствующее исключение EntityVersionException.
6.2.23. Реализация применения комплексных ключей в модуле CSV-Uploader в Типовом ПО Витрина данных
В целях обеспечения возможности использования комплексных ключей в типовом ПО Витрина данных обеспечено создание и наполнение витрин данных с применением комплексных первичных ключей и комплексных ключей шардирования в модуле CSV-uploader.
Для реализации вышеуказанной функциональности выполнены следующие работы:
Реализована поддержка парсинга комплексных первичных ключей в модуле CSV-uploader.
Реализована поддержка передачи модулем CSV-uploader в ядро Типового ПО Витрины данных (Prostore):
комплексных первичных ключей;
комплексных ключей шардирования.
В рамках данного требования ПОДД СМЭВ не дорабатывался.
В рамках выполнения данной работы нагрузочные испытания создания и использования комплексных ключей не предусматривались.
6.2.23.1. Описание технического решения по реализации поддержки парсинга комплексных первичных ключей в модуле CSV-Uploader
Для обеспечения поддержки парсинга комплексных первичных ключей в модуле CSV-Uploader и передаче в ядро Типового ПО Витрина данных комплексных первичных ключей при создании структуры Витрины данных выполняется парсинг всех первичных ключей , указанных в структуре таблицы.
Пример структуры Витрины данных с комплексным первичным ключом:
<?xml version="1.0" encoding="UTF-8"?>
<soapenv:Envelope xmlns:xsd="http://www.w3.org/2001/XMLSchema" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:ns="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/1.3" xmlns:soapenv="http://schemas.xmlsoap.org/soap/envelope/" xmlns="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/1.3" xmlns:ns1="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/basic/1.3" xmlns:ns2="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/basic/1.3" xmlns:ns3="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/faults/1.3" xmlns:ns4="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/routing/1.3">
<soapenv:Body>
<ns:SendRequestRequest>
<ns:SenderProvidedRequestData Id="SIGNED_BY_CALLER" xmlns:ns="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/1.3" xmlns:ns2="urn://x-artefacts-smev-gov-ru/services/message-exchange/types/basic/1.3">
<ns:MessageID>ed5ec1ee-9326-11ed-b8c5-0242c0a86014</ns:MessageID>
<ns2:MessagePrimaryContent>
<podd:PODDMetadataRequest xmlns:podd="urn://x-artefacts-podd-gosuslugi-local/metadata/datamart/2/1.6.0" xmlns:ns1="urn://x-artefacts-podd-gosuslugi-local/metadata/types/1.4.0">
<podd:requestId>ed5ec478-9326-11ed-b8c5-0242c0a86014</podd:requestId>
<podd:metadata>
<ns1:datamart>
<ns1:id>ffaeba4e-2d2d-4b87-946f-a9b1ba195b40</ns1:id>
<ns1:mnemonic>demo_view_eip</ns1:mnemonic>
<ns1:description> Тестовая витрина 12.01.23</ns1:description>
<ns1:tenantId>2b8a7fef-44d8-431f-bf7e-41c610fca5f2</ns1:tenantId>
<ns1:ogrn>1180738664215</ns1:ogrn>
<ns1:version>
<ns1:major>1</ns1:major>
<ns1:minor>1</ns1:minor>
</ns1:version>
<ns1:supportedFrom>2023-01-11T21:00:00.000Z</ns1:supportedFrom>
<ns1:datamartClass>
<ns1:id>567ce265-5dab-4133-b0e3-9ed4a0cb8cc2</ns1:id>
<ns1:mnemonic>ticket</ns1:mnemonic>
<ns1:description>ticket</ns1:description>
<ns1:classAttribute>
<ns1:id>b10dce6e-b31f-4a44-935d-6e8b069f15c8</ns1:id>
<ns1:mnemonic>id</ns1:mnemonic>
<ns1:description>id</ns1:description>
<ns1:type>STRING</ns1:type>
</ns1:classAttribute>
<ns1:classAttribute>
<ns1:id>2ed56a7b-aec6-4b1b-8acd-818417abe127</ns1:id>
<ns1:mnemonic>passengerid</ns1:mnemonic>
<ns1:description>passengerid</ns1:description>
<ns1:type>STRING</ns1:type>
</ns1:classAttribute>
<ns1:classAttribute>
<ns1:id>7c4ab661-a486-4c37-88cb-6c25eda99b65</ns1:id>
<ns1:mnemonic>tripid</ns1:mnemonic>
<ns1:description>tripid</ns1:description>
<ns1:type>STRING</ns1:type>
</ns1:classAttribute>
<ns1:classAttribute>
<ns1:id>b11ac749-4ad6-46fc-a12b-1ce2f8893fe5</ns1:id>
<ns1:mnemonic>number</ns1:mnemonic>
<ns1:description>number</ns1:description>
<ns1:type>INTEGER</ns1:type>
</ns1:classAttribute>
<ns1:classAttribute>
<ns1:id>40c41c1b-76c1-4cf0-8306-0ebf9533bcf2</ns1:id>
<ns1:mnemonic>bycard</ns1:mnemonic>
<ns1:description>bycard</ns1:description>
<ns1:type>BOOLEAN</ns1:type>
</ns1:classAttribute>
<ns1:classAttribute>
<ns1:id>95bb9a6d-768e-4099-92c8-c03882c5fd20</ns1:id>
<ns1:mnemonic>price</ns1:mnemonic>
<ns1:description>price</ns1:description>
<ns1:type>DOUBLE</ns1:type>
</ns1:classAttribute>
<ns1:classAttribute>
<ns1:id>cf5dbe10-97b6-4981-80ce-ea82433122c0</ns1:id>
<ns1:mnemonic>sold</ns1:mnemonic>
<ns1:description>sold</ns1:description>
<ns1:type>TIMESTAMP</ns1:type>
</ns1:classAttribute>
<ns1:classAttribute>
<ns1:id>9cdc0aa7-07cd-4623-9e36-d954eab8e484</ns1:id>
<ns1:mnemonic>bablo</ns1:mnemonic>
<ns1:description>валюта</ns1:description>
<ns1:type>STRING</ns1:type>
</ns1:classAttribute>
<ns1:primaryKey>
<ns1:id>b10dce6e-b31f-4a44-935d-6e8b069f15c8</ns1:id>
<ns1:mnemonic>id</ns1:mnemonic>
<ns1:description>id</ns1:description>
<ns1:type>STRING</ns1:type> </ns1:primaryKey>
<ns1:primaryKey>
<ns1:id>b11ac749-4ad6-46fc-a12b-1ce2f8893fe5</ns1:id>
<ns1:mnemonic>number</ns1:mnemonic>
<ns1:description>number</ns1:description>
<ns1:type>INTEGER</ns1:type>
</ns1:primaryKey>
</ns1:datamartClass>
</ns1:datamart>
</podd:metadata>
</podd:PODDMetadataRequest>
</ns2:MessagePrimaryContent>
</ns:SenderProvidedRequestData>
</ns:SendRequestRequest>
</soapenv:Body>
</soapenv:Envelope>
При этом в случае, если в загружаемой структуре присутствует хотя бы одна таблица без первичного ключа, модуль CSV-uploader возвращает ошибку: «Ошибка генерации таблиц по XML».
6.2.23.2. Описание технического решения по реализации поддержка передачи модулем CSV-uploader в ядро Типового ПО Витрины комплексных первичных ключей и комплексных ключей шардирования
Для обеспечения поддержки реализации передачи модулем CSV-uploader в ядро Типового ПО Витрины комплексных первичных ключей и комплексных ключей шардирования, для каждой таблицы загружаемой структуры ИС при формировании DDL передавать в Prostore мнемонику (mnemonic) всех полей типа primaryKey в качестве:
PRIMARY KEY;DISTRIBUTED BY.
DDL на создание таблиц. При этом в случае использования комплексного первичного ключа, ключ шардирования соответствует первичному ключу и тоже является комплексным.
Пример DDL для структуры таблиц с комплексным первичным ключом:
CREATE TABLE demo_view_eip.ticket (
id UUID,
passengerid UUID,
tripid UUID,
"number" BIGINT NOT NULL,
bycard BOOLEAN,
price DOUBLE,
sold TIMESTAMP,
PRIMARY KEY (id,"number")
)
DISTRIBUTED BY (id,"number")
6.2.24. Технические решения по сбору статистики и протоколированию обработанных запросов
Технические решения по протоколированию запросов и ответов (в том числе для выполнения требований к хранению данных о предоставленных пользователям выписках), и возможности протоколирования информации о том, какие данные и какому ведомству были предоставлены.
В рамках выполненных работ были реализованы следующие технические решения:
фиксация запросов и ответов в модулях витрины данных:
podd-adapter;
podd-adapter-mppr;
podd-adapter-replicator;
printable-form-service;
blob-adapter;
smev3-adapter;
обработка протоколируемых запросов и ответов;
хранение протоколируемых запросов и ответов, с возможностью извлекать данные по уникальному идентификатору;
поддержка протокола ПОДД, обеспечивающего передачу идентифицирующих атрибутов запросов;
фиксация, передача, хранение и очистка идентифицирующих атрибутов запросов.
6.2.24.1. Описание технического решения по фиксации запросов и ответов в модулях витрины данных
6.2.24.1.1. Архитектура технического решения
На Рисунок - 6.77 представлена архитектура технического решения по фиксации запросов и ответов в модулях витрины данных.
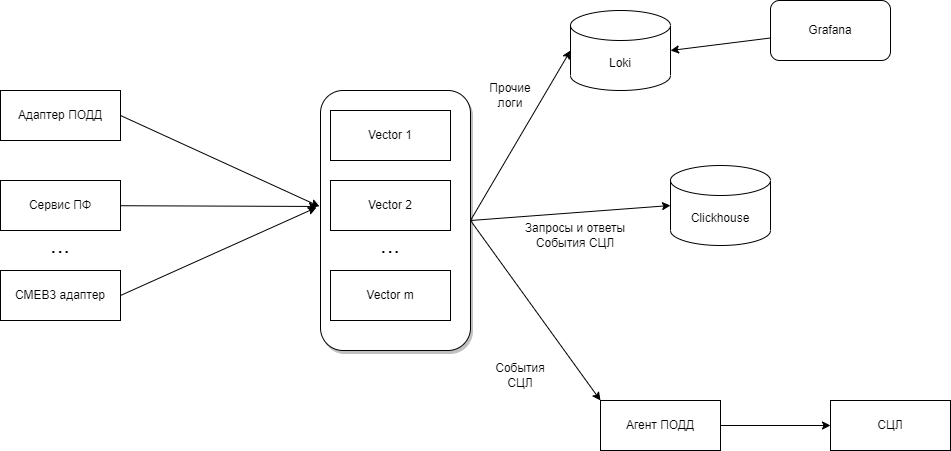
Рисунок - 6.77 Архитектура технического решения по фиксации запросов и ответов в модулях витрины данных
6.2.24.1.2. Реализация фиксации запросов и ответов в модулях витрины данных
Для реализации фиксации запросов и ответов в модулях витрины данных используется система логирования, которая отвечает следующим функциональным особенностям:
Используется единый формат записи логов для модулей Витрины данных – org.apache.log4j.fileAppender, предназначенный для записи логов в файл. Используется для хранения логов форма JSON.
Уровень логирования определяется конфигурационным параметром в файле logback.xml. Логирование запросов и ответов конфигурируется отдельно.
Поддерживаются следующие режимы логирования:
DEBUG – логирование отладочных событий
INFO – логирование запросов и ответов, события СЦЛ и прочие информационные сообщения, события запуска и остановки приложения;
WARN – логирование предупреждений;
ERROR – логирование всех ошибок.
Для всех типов запросов и ответов, текст сообщения должен содержать объект с полями:
заголовки(массив);
ключ;
значение.
Атрибутивный состав журналируемых полей представлен в tab_23.
Поле (ClickHouse) |
Поле на нижнем уровне |
Родитель |
Тип переменной |
Описание |
Обязательность |
Модуль, в котором генерируется данная переменная |
|---|---|---|---|---|---|---|
logger |
string |
Имя класса, породившего событие |
Нет |
Все |
||
timestamp |
long |
Дата и время события в формате system time milli seconds since epoch |
Да |
Все |
||
level |
string |
Уровень журналирования |
Да |
Все |
||
message |
string |
Текст события MessageType == request - сериализованный request MessageType == response - сериализованный response |
Да |
Все |
||
requestId |
string |
Идентификатор, который позволяет отследить события в разных сервисах в рамках одного входящего запроса (UUID запроса) |
Нет |
Все |
||
messageType |
string |
Тип события
|
Да |
Все |
||
customerId |
string |
Идентификатор автора запроса |
Да |
адаптер ПОДД |
||
customerOgrn |
string |
ОГРН ИС Потребителя |
Да |
адаптер ПОДД модуль ФД |
||
queryMnemonic |
string |
Мнемоника РЗ, сформированная по правилу: <мнемоника витрины>. <мнемоника РЗ>.<версия РЗ> Если запрос распределенный, то формируется по правилу: podd.<мнемоника РЗ>. <версия РЗ> |
Да |
модуль исполнения запросов модуль ФД |
||
codeEvent |
Message |
string |
Идентификатор типа события |
Да |
Все |
|
requestId |
Message |
string |
UUID запроса |
Да |
Все |
|
subRequestId |
Message |
string |
UUID подзапроса |
Нет |
адаптер ПОДД MPPR-модуль |
|
datamartId |
Message |
string |
Имя витрины |
Нет |
адаптер ПОДД |
|
isForEstimation |
Message |
boolean |
|
Нет |
адаптер ПОДД |
|
queryRequestId |
Message |
string |
requestId исходного запроса, на основании которого порожден этот запрос |
Нет |
BLOB-адаптер |
|
hasTableParams |
Message |
boolean |
Запрос с использованием табличных параметров |
Нет |
адаптер ПОДД |
|
dataVolume |
Message |
Long |
Размер возвращаемых данных (в байтах) |
Нет |
адаптер ПОДД MPPR-модуль Модуль ФД BLOB-адаптер |
|
isMppr |
Message |
boolean |
При исполнении запроса был задействован MPPR режим |
Нет |
адаптер ПОДД MPPR-модуль |
|
errorCode |
Message |
string |
Код ошибки, возвращенный в ответ на запрос (Если ошибки не возникло, то пустая строка) |
Нет |
адаптер ПОДД MPPR-модуль Модуль ФД BLOB-адаптер |
6.2.24.2. Описание технического решения по обработке протоколируемых запросов и ответов
В рамках технического решения по обработке протоколируемых запросов и ответов реализована система анализа лог-файлов, которая состоит из набора объектов типа Vector. Каждый экземпляр представляет собой роутер событий, принимающим сообщения из одного или нескольких источников, опционально применяющим над этими сообщениями преобразования, и отправляющим их в один или несколько конечных систем хранения. Реализация маршрутизации различных типов событий, которые возникают в модулях Витрины Данных, представлена в Таблица 6.17.
Тип журналируемого события |
Хранилище данных |
|---|---|
События СЦЛ |
СЦЛ, ClickHouse |
События запросов и ответов |
ClickHouse |
Прочие логи: - события запуска и остановки экземпляров модулей адаптеров, другие технологические информационные события;
витрины данных;
данных. |
Loki |
6.2.24.3. Описание технического решения по хранению протоколируемых запросов и ответов, с возможностью извлекать данные по уникальному идентификатору
В рамках технического решения по хранению протоколируемых запросов и ответов с возможностью извлечение данных по уникальному идентификатору реализовано использование колоночной аналитической базы данных ClickHouse.
Ключевые функциональные особенности базы данных ClickHouse:
движок базы данных: по умолчанию ClickHouse использует движок Atomic;
движок таблиц: MergeTree;
версия ClickHouse: LTS;
запрос на создание таблицы хранения логов в ClickHouse: CREATE TABLE.
CREATE TABLE {Название БД}.logs
(
logger String,
timestamp DateTime,
level String,
requestId String,
message String,
messageType String,
customerId String,
customerOgrn String,
queryMnemonic String
)
ENGINE = MergeTree()
PARTITION BY timestamp
ORDER BY timestamp
SETTINGS index_granularity = 8192;
6.2.24.4. Описание технического решения по поддержке протокола ПОДД, обеспечивающего передачу идентифицирующих атрибутов запросов
В рамках технического решения по поддержке протокола ПОДД реализована передача идентифицирующих атрибутов запросов согласно протоколу обмена сообщениями ПОДД-Витрина.
В запросы модулей исполнения запросов, сервиса печатных форм и ТП (топики Kafka query.rq, report.rq и query.tp соответственно) добавлены следующие атрибуты, описание которых представлено в Таблица 6.18.
Наименование нового атрибута |
Тип |
Дефолтное значение |
Описание атрибута |
|---|---|---|---|
customerId customerOgrn queryMnemonic |
string, null string, null string, null |
null null null |
Мнемоника ИС Потребителя ОГРН ИС Потребителя Мнемоника РЗ, сформированная по правилу: <мнемоника витрины>.<мнемоника РЗ>.<версия РЗ> Если запрос распределенный, то формируется по правилу: podd.<мнемоника РЗ>.<версия РЗ> |
6.2.24.5. Описание технического решения по фиксации, передачи, хранению и очистки идентифицирующих атрибутов запросов
При выполнении запроса query.tp в модуль группировки данных табличных параметров (podd-adapter-group-tp) реализована следующая функциональность:
обработка идентифицирующих атрибутов customerId, customerOgrn и queryMnemonic при получении сообщения из топика Kafka query.tp;
передача идентифицирующих атрибутов customerId, customerOgrn и queryMnemonic в составе команды для модуля импорта табличных параметров podd-adapter-import-tp во внутренний топик Kafka tp.upload.query;
В модуле импорта табличных параметров podd-adapter-import-tp реализована следующая функциональность:
обработка атрибутов customerId, customerOgrn и queryMnemonic при получении сообщения из топика Kafka tp.upload.query;
сохранение идентифицирующих атрибутов запросов в числе прочих атрибутов табличных параметров в Zookeeper;
отправка идентифицирующих атрибутов запросов в составе команды к модулю исполнения запросов podd-adapter-query в топик Kafka query.rq.
Также в рамках технического решения реализовано добавление идентифицирующих атрибутов в лог-файл отдельными атрибутами и отправка идентифицирующих атрибутов запросов в ClickHouse отдельными полями для быстрой фильтрации.
6.2.24.6. Особенности и ограничения
В рамках данного требования глубина хранения протоколируемых запросов и ответов определяются настроечным параметром в типовом ПО витрины данных.
6.2.25. Технические решения по реализации обеспечения совместимости Типового ПО Витрина данных под управлением операционных систем Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП
В целях поддержки отечественной операционной системы из реестра Российского ПО, устойчивого предоставления госуслуг и межведомственного обмена обеспечена совместимость Типового ПО Витрина данных на серверах с предустановленной операционной системой Astra Linux, РЕД ОС, АЛЬТ Сервер 8 СП.
Для реализации вышеуказанной функциональности выполнены следующие работы:
Проведено тестирование процесса развертывания витрины данных на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП.
Проведено регрессионное тестирование функционирования витрины данных без подключения к ПОДД на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП.
Подготовлен отчет о регрессионном тестировании витрины данных на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП.
По итогам регрессионного тестирования выполнены необходимые доработки Типового ПО Витрина данных для обеспечения совместимости с операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП.
Подготовлены скрипты и проведены серии нагрузочных испытаний.
Подготовлен отчёт о результатах нагрузочного тестирования.
6.2.25.1. Описание тестирования процесса развертывания витрины данных на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП
Целью тестирования процесса развертывания витрины данных на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП является:
проверка работоспособности Типового ПО «Витрина данных» на операционной системе «Astra Linux 1.7 (уровень защищенности «Воронеж»)»;
проверка работоспособности Типового ПО «Витрина данных» на операционной системе «РЕД ОС 7.2»;
проверка работоспособности Типового ПО «Витрина данных» на операционной системе «АЛЬТ Сервер 8 СП».
Для проведения тестирования на операционной системе «Astra Linux 1.7 (уровень защищенности «Воронеж»)» был подготовлен тестовый стенд с программными компонентами, приведенными в Таблица 4.1.
№ |
Название компонента |
Версия |
|---|---|---|
1 |
ПОДД Агент |
einfahrt:3.2.0-pre-2 |
2 |
Agent Driver |
podd-jdbc-driver-3.2.0-SNAPSHOT-fat.jar |
3 |
СМЭВ3 Адаптер |
smev3-adapter:4.0.12 |
4 |
Сервис формирования документов |
printable-form-service:1.1.1 |
5 |
Rest Адаптер |
rest-adapter:4.3.6 |
6 |
Модуль асинхронной загрузки данных из сторонних источников |
rest-uploader:1.0.4 |
7 |
Модуль исполнения асинхронных заданий |
data-uploader:1.0.4 |
8 |
Сервис считывания BLOB |
blob-adapter:1.1.7 |
9 |
Модуль исполнения запросов |
podd-adapter-query:5.2.0 |
10 |
Модуль подписок |
podd-adapter-replicator:1.1.0 |
11 |
Модуль группировки чанков репликации |
podd-adapter-group-repl:1.1.1 |
12 |
Модуль MPPR |
podd-adapter-mppr:5.1.6 |
13 |
Модуль MPPW |
podd-adapter-mppw:5.1.2 |
14 |
Модуль группировки чанков табличных параметров |
podd-adapter-group-tp:5.1.2 |
15 |
Модуль импорта данных табличных параметров |
podd-adapter-import-tp:5.1.2 |
16 |
Дефрагментатор |
podd-avro-defragmentator:5.0.5 |
17 |
Сервис счетчика |
counter-provider:1.0.0 |
18 |
Redis |
версия из репозитория Astra Linux (7.0.5) |
19 |
csv-uploader |
csv-uploader:1.0.26 |
20 |
Prostore |
query-execution:6.0.0 status-monitor:6.0.0 |
21 |
Prostore Driver |
dtm-jdbc-6.0.0.jar |
22 |
ADS |
kafka 2.6.0 zookeeper 3.5.8 |
23 |
ADB |
6.15.0 |
24 |
FDW |
0.10.2 |
25 |
PXF |
1.0 |
26 |
Kafka-pxf-connector |
1.0.0 |
Для проведения тестирования на операционной системе «РЕД ОС 7.2» был подготовлен тестовый стенд с программными компонентами, приведенными в Таблица 6.20.
№ |
Название компонента |
Версия |
|---|---|---|
1 |
ПОДД Агент |
einfahrt:3.2.0-pre-2 |
2 |
Agent Driver |
podd-jdbc-driver-3.2.0-SNAPSHOT-fat.jar |
3 |
СМЭВ3 Адаптер |
smev3-adapter:4.0.12 |
4 |
Сервис формирования документов |
printable-form-service:1.1.1 |
5 |
Rest Адаптер |
rest-adapter:4.3.6 |
6 |
Модуль асинхронной загрузки данных из сторонних источников |
rest-uploader:1.0.4 |
7 |
Модуль исполнения асинхронных заданий |
data-uploader:1.0.4 |
8 |
Сервис считывания BLOB |
blob-adapter:1.1.7 |
9 |
Модуль исполнения запросов |
podd-adapter-query:5.2.0 |
10 |
Модуль подписок |
podd-adapter-replicator:1.1.0 |
11 |
Модуль группировки чанков репликации |
podd-adapter-group-repl:1.1.1 |
12 |
Модуль MPPR |
podd-adapter-mppr:5.1.6 |
13 |
Модуль MPPW |
podd-adapter-mppw:5.1.2 |
14 |
Модуль группировки чанков табличных параметров |
podd-adapter-group-tp:5.1.2 |
15 |
Модуль импорта данных табличных параметров |
podd-adapter-import-tp:5.1.2 |
16 |
Дефрагментатор |
podd-avro-defragmentator:5.0.5 |
17 |
Сервис счетчика |
counter-provider:1.0.0 |
18 |
Redis |
версия из репозитория |
19 |
csv-uploader |
csv-uploader:1.0.26 |
20 |
Prostore |
query-execution:6.0.0 status-monitor:6.0.0 |
21 |
Prostore Driver |
dtm-jdbc-6.0.0.jar |
22 |
ADS |
kafka 2.6.0 zookeeper 3.5.8 |
23 |
ADB |
6.15.0 |
24 |
FDW |
0.10.2 |
25 |
PXF |
1.0 |
26 |
Kafka-pxf-connector |
1.0.0 |
Для проведения тестирования на операционной системе «АЛЬТ Сервер 8 СП» был подготовлен тестовый стенд с программными компонентами, приведенными в Таблица 6.21.
№ |
Название компонента |
Версия |
|---|---|---|
1 |
ПОДД Агент |
einfahrt:3.2.0-pre-2 |
2 |
Agent Driver |
podd-jdbc-driver-3.2.0-SNAPSHOT-fat.jar |
3 |
СМЭВ3 Адаптер |
smev3-adapter:4.0.12 |
4 |
Сервис формирования документов |
printable-form-service:1.1.1 |
5 |
Rest Адаптер |
rest-adapter:4.3.6 |
6 |
Модуль асинхронной загрузки данных из сторонних источников |
rest-uploader:1.0.4 |
7 |
Модуль исполнения асинхронных заданий |
data-uploader:1.0.4 |
8 |
Сервис считывания BLOB |
blob-adapter:1.1.7 |
9 |
Модуль исполнения запросов |
podd-adapter-query:5.2.0 |
10 |
Модуль подписок |
podd-adapter-replicator:1.1.0 |
11 |
Модуль группировки чанков репликации |
podd-adapter-group-repl:1.1.1 |
12 |
Модуль MPPR |
podd-adapter-mppr:5.1.6 |
13 |
Модуль MPPW |
podd-adapter-mppw:5.1.2 |
14 |
Модуль группировки чанков табличных параметров |
podd-adapter-group-tp:5.1.2 |
15 |
Модуль импорта данных табличных параметров |
podd-adapter-import-tp:5.1.2 |
16 |
Дефрагментатор |
podd-avro-defragmentator:5.0.5 |
17 |
Сервис счетчика |
counter-provider:1.0.0 |
18 |
Redis |
версия из репозитория |
19 |
csv-uploader |
csv-uploader:1.0.26 |
20 |
Prostore |
query-execution:6.0.0 status-monitor:6.0.0 |
21 |
Prostore Driver |
dtm-jdbc-6.0.0.jar |
22 |
ADS |
kafka 2.6.0 zookeeper 3.5.8 |
23 |
ADB |
6.15.0 |
24 |
FDW |
0.10.2 |
25 |
PXF |
1.0 |
26 |
Kafka-pxf-connector |
1.0.0 |
В результате установки:
Типовое ПО «Витрина данных» полностью работоспособно;
все взаимосвязи между компонентами настроены автоматически;
все необходимые компоненты запущены.
В процессе установки используется единый конфигурационный файл (настраиваемый перед установкой).
Процесс установки поддерживает детализированную диагностику возникающих ошибок.
Все возникающие в процессе установки ошибки логируются.
В процессе установке автоматически настраиваются взаимосвязи между компонентами программы.
Инструмент установки включает механизм проверки полноты выполненной установки компонентов и того, что все необходимые компоненты запустились.
6.2.25.2. Описание регрессионного тестирования функционирования витрины данных без подключения к ПОДД на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП
Целью проведения регрессионного тестирования является проверка работоспособности Типового ПО «Витрина данных» на операционных системах Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП.
Для проведения регрессионного тестирования подготовлены основные сценарии тестирования модулей Типового ПО Витрина данных.
Каждый сценарий тестирования содержит описание шага тестирования с указанием ожидаемого результата и статусом прохождения шага.
6.2.25.3. Описание подготовки отчетов о регрессионном тестировании витрины данных на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП
По итогам проведения регрессионного тестирования были подготовлены отчеты о регрессионном тестировании Типового ПО «Витрина данных» на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП по каждой из операционных систем.
Каждый отчет о регрессионном тестировании содержит разделы:
цели тестирования;
конфигурация стенда для тестирования;
методика тестирования и ожидаемые контрольные результаты;
результаты тестирования;
замечания к разработке;
план доработок.
В разделе «Цели тестирования» приведены основные сценарии тестирования.
В разделе «Конфигурация стенда для тестирования» указаны версии программных компонентов ПО «Витрина данных».
В разделе «Методика тестирования и ожидаемые контрольные результаты» прописаны шаги воспроизведения каждого сценария с указанием ожидаемого результата и статуса прохождения шага.
В разделе «Результаты тестирования» приведено описание выявленных дефектов и результатов тестирования.
В разделе «Замечания к разработке» приведена таблица с описанием найденных дефектов.
В приложении «План доработок» приведен план доработок найденных дефектов.
6.2.25.4. Описание выполнения необходимых доработок Типового ПО Витрина данных по итогам регрессионного тестирования для обеспечения совместимости с операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП
По результатам регрессионного тестирования Типового ПО «Витрина данных» на операционной системе Astra Linux разработка имеет дефект с серьезностью Trivial. Дефект не блокирующий и не критичный. Он не влияет на функциональность. Приоритет дефекта Low, так как не оказывает никакого влияния на общее качество продукта. Есть возможность для работы с тестируемой функцией. Дефект был исправлен в процессе тестирования.
По результатам регрессионного тестирования Типового ПО «Витрина данных» на операционной системе АЛЬТ Сервер 8 СП разработка имеет дефект с серьезностью Trivial. Дефект не блокирующий и не критичный. Он не влияет на функциональность. Приоритет дефекта Low, так как не оказывает никакого влияния на общее качество продукта. Есть возможность для работы с тестируемой функцией. Дефект был исправлен в процессе тестирования.
По результатам регрессионного тестирования Типового ПО «Витрина данных» на операционной системе РЕД ОС разработка имеет дефект с серьезностью Trivial. Дефект не блокирующий и не критичный. Он не влияет на функциональность. Приоритет дефекта Low, так как не оказывает никакого влияния на общее качество продукта. Есть возможность для работы с тестируемой функцией. Дефект был исправлен в процессе тестирования.
6.2.25.5. Описание подготовки скриптов и проведения нагрузочного тестирования
На целевых ОС нагрузочное тестирование проводится только на модулях слоя адаптеров, отвечающих за исполнение запросов LLR:
query-execution;
status-monitor;
podd-adapter-query.
Наполнение витрины данными:
модель данных тестовая с таблицей vehicleregdata (данные регистрации ТС);
1,5 млн записей в таблице vehicleregdata;
ключи генерируемых данных используют диапазон от 1 до 1,5 млн;
объем одной записи 100 байт;
избирательность прочих ( не ключевых) полей не важна, могут быть одинаковые значения.
Вид нагрузки:
запросы на получение одной записи по ключу с Limit 1 для работы в режиме LLR, фильтруемое значение выбирается случайным образом из диапазона генерированных данных;
запросы направляются в Кафка в топик query.rq, ответы фиксируются в топике query.rs;
каждый поток создает запрос и ожидает ответа, фиксирует время от запроса до ответа, следующий запрос посылает после получения ответа на предыдущий запрос.
Нагрузка:
(А) нарастает последовательно до тех пор, пока итоговая производительность не станет снижаться или пока не начнутся массовые ошибки;
Нарастает до расчётной стабильной и сохраняется на этом уровне.
Перед началом эксперимента необходим перезапуск ADB и стирание файлового кеша на ADB и рабочих узлах.
Накопление кеша в процессе одного эксперимента считаем естественным ускорителем.
6.2.25.6. Описание подготовки отчета о результатах нагрузочного тестирования
По итогам проведения тестирования были подготовлены отчеты о нагрузочном тестировании Типового ПО «Витрина данных» на серверах с предустановленными операционными системами Astra Linux, РЕД ОС и АЛЬТ Сервер 8 СП по каждой из операционных систем.
Каждый отчет о нагрузочном тестировании содержит разделы:
Общие сведения;
Цели тестирования;
Основные сценарии тестирования;
Конфигурация стенда для тестирования;
Результаты тестирования;
Замечания к разработке.
В разделе «Общие сведения» приведены сведения об объекте тестирования.
В разделе «Цели тестирования» приведены основные цели проведения нагрузочных испытаний.
В разделе «Сценарии тестирования» прописаны шаги воспроизведения каждого сценария с указанием ожидаемого результата и статуса прохождения шага.
В разделе «Конфигурация стенда для тестирования» указаны версии программных компонентов ПО «Витрина данных».
В разделе «Результаты тестирования» приведено описание выявленных дефектов и результатов тестирования.
В разделе «Замечания к разработке» приведена таблица с описанием найденных дефектов.
6.2.26. Выполнение запросов с системными параметрами
6.2.26.1. Общее описание
Системный параметр не указывается в исходном sql запросе, передается как именованный в массиве namedParams используя служебное именование. Конструкция, соответствующая параметру подставляется во все таблицы запроса, кроме standalone таблиц.
Именованный параметр: указан в sql с :name, в зависимости от мнемоники, из массива namedParams в момент исполнения запроса в модуле query подставляется значение из элемента массива, соответствующего мнемонике.
Обработка системных и именованных параметров осуществляется Модулем исполнения запросов (podd-adapter-query).
Пример подстановки конструкции, соответствующей системному параметру в sql запрос представлена на рисунке ниже (см. Рисунок - 4.2).
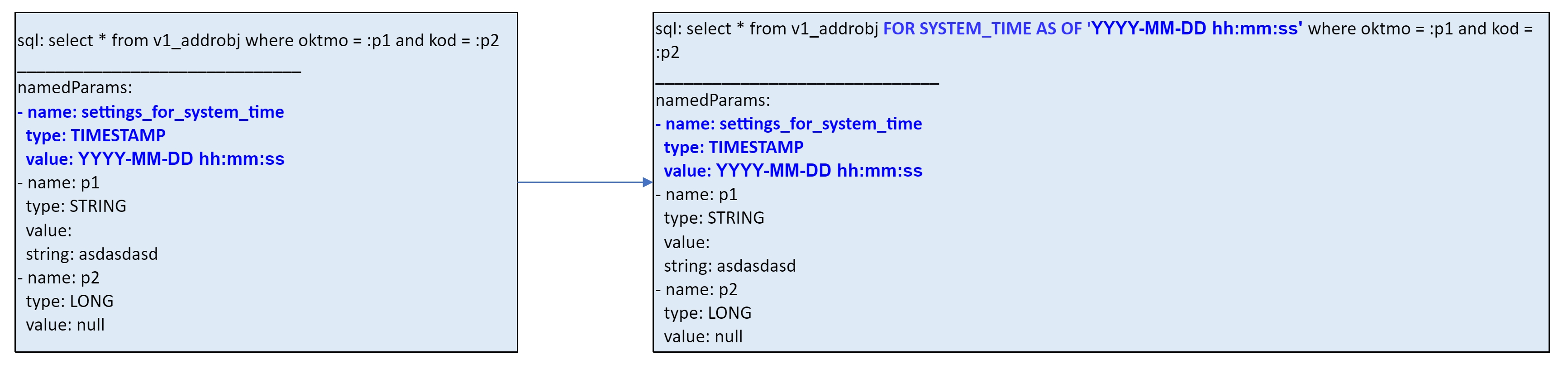
Рисунок - 6.78 Подстановка системного параметра в sql запрос
Массив именованных параметров (для передачи системных и именованных параметров) имеет следующую структуру:
- name: namedParams
description: Именованные параметры запроса
default: [ ]
type:
type: array
items:
type: record
name: NamedParam
description: Описание именованного параметра
fields:
- name: name
description: Имя (мнемоника) параметра
type: string
- name: type
type: string
description: Тип параметра
enum:
- BIG_DECIMAL
- BINARY
- BOOLEAN
- DATE
- DOUBLE
- FLOAT
- INTEGER
- LONG
- SHORT
- STRING
- TIME
- TIMESTAMP
- name: value
description: Значение параметра
type:
- string
- 'null'
6.2.26.2. Обработка системных параметров
Если блок
namedParamsне пустой, после парсинга запроса Calcite модуль podd-adapter-query проверяет наличие мнемоник системных параметров:
settings_for_system_time;
settings_for_system_time_started;
settings_for_system_time_finished.
В случае, если системный параметр есть, проверяет:
что параметр с префиксом
settings_один в списке;сам запрос не содержит конструкцию
FOR SYSTEM_TIMEни в одной из таблиц запроса;в случае, если одно из перечисленных выше условий не выполняется, в топик
query.errвозвращается ошибка: DATAMART-17473 (Неверное sql-выражение: [Двойное указание темпоральности недопустимо]).
Модуль проверяет value системного параметра по маске:
для параметра
settings_for_system_timevalue запроса должно быть таймштампом в формате YYYY-MM-DD hh:mm:ssдля параметров
settings_for_system_time_startedиsettings_for_system_time_finished:два целочисленных числа разделенных запятой („int1,int2“)
в случае, если value параметра не соответствует маске, в топик
query.errвозвращается ошибка: DATAMART-17473 (Неверное sql-выражение: [ Недопустимое значение параметра [ имя параметра] - [ значение параметра ]])В случае, если значение системного параметра null , возвращается ошибка: DATAMART-17473 ( Недопустимое значение параметра [имя параметра] = null )
Для параметров
settings_for_system_time_startedиsettings_for_system_time_finishedпроверяет, что первое значение int или timestamp меньше последнего:
в случае, если первое значение в строке больше второго, в топик
query.errвозвращается ошибка: DATAMART-17473 (Неверное sql-выражение: [Недопустимый (отрицательный) диапазон значений параметра [ имя параметра] - [ значение параметра ]])
После выполнения проверок 1-4 модуль podd-adapter-query подставляет системный параметр во все таблицы запроса, после имени таблицы в блоке from. (если в запросе есть блок where, то перед этим блоком). Исключение: временные таблицы загрузки табличных параметров, так как временные таблицы являются standalone (определяем по префиксу
readableв названии таблицы):
если в запросе используется системный параметр
settings_for_system_time:FOR SYSTEM_TIME AS OF 'YYYY-MM-DD hh:mm:ss[.microseconds],если в запросе используется системный параметр
«settings_for_system_time_started»:FOR SYSTEM_TIME STARTED IN (delta_num1, delta_num2), если строка состоит из двух целочисленных значений, разделенных запятой
если в запросе используется системный параметр
settings_for_system_time_finished:FOR SYSTEM_TIME FINISHED IN (delta_num1, delta_num2), если строка состоит из двух целочисленных значений, разделенных запятой
Подставляет в запрос остальные именованные параметры, в случае, если они присутствуют в запросе.
В случае, если в запросе есть limit и он меньше порогового значения или есть FORCE_LLR, то выполняются следующие действия:
в Prostore подается команду на получение данных через Rest-интерфейс Prostore;
данные из Prostore преобразуются в формат ПОДД и конвертирует timezone у полей, выгружаемых из Витрины к формату UTC в топик
query.rs.в случае, если вернулась ошибка , то возвращается ответ в
query.errс текстом ошибки
В случае, если в запросе отсутствует limit или настройка FORCE_LLR выключена, то передает сообщение в топик
mppr.delegate.rqи завершает выполнение запроса.
Рисунок - 6.79 Схема взаимодействия компонентов
6.2.26.3. Примеры преобразования запросов
Примеры запроса query.rq с системными параметрами settings_for_system_time_started и settings_for_system_time_finished c номерами дельт
sql: select * FROM demo_view.ticket join demo_view.passenger on demo_view.passenger.id =demo_view.ticket.passengerid
__________________________________________________________________________________________
"namedParams" : [ {
"name" : "settings_for_system_time_started",
"type" : "STRING",
"value" : {
"string" : "122, 123"
}
} ]
__________________________________________________________________________________________
преобразованный запрос, после подстановки параметра FOR SYSTEM_TIME STARTED IN:
select * FROM demo_view.ticket FOR SYSTEM_TIME STARTED IN (122,124) join demo_view.passenger FOR SYSTEM_TIME STARTED IN (122,124) on demo_view.passenger.id =demo_view.ticket.passengerid
__________________________________________________________________________________________
sql: select * FROM demo_view.ticket join demo_view.passenger on demo_view.passenger.id =demo_view.ticket.passengerid
_________________________________________________________________________________________
"namedParams" : [ {
"name" : "settings_for_system_time_started",
"type" : "STRING",
"value" : {
"string" : "122,123"
}
} ]
___________________________________________________________________________________________
преобразованный запрос, после подстановки параметра FOR SYSTEM_TIME FINISHED IN:
select * FROM demo_view.ticket FOR SYSTEM_TIME FINISHED IN (122,124) join demo_view.passenger FOR SYSTEM_TIME FINISHED IN (122,124) on demo_view.passenger.id =demo_view.ticket.passengerid
**Пример запроса query.rq с системным параметром settings_for_system_time:
sql: select * FROM demo_view.ticket join demo_view.passenger on demo_view.passenger.id =demo_view.ticket.passengerid
___________________________________________________________________________________________
namedParams:
- name: settings_for_system_time
type: TIMESTAMP
value:
string: 2022-11-14 16:00:00
__________________________________________________________________________________________
преобразованный запрос, после подстановки параметра FOR SYSTEM TIME: select * FROM demo_view.ticket FOR SYSTEM_TIME AS OF '2022-11-14 16:00:00' join demo_view.passenger FOR SYSTEM_TIME AS OF :p2 on demo_view.passenger.id =demo_view.ticket.passengerid
query.tp, системные параметры (к табличному параметру не подставляем, так как таблица standalone):
sql: select count(*) from @tbl el LEFT JOIN demo_view.passenger on @tbl.firstname.firstname = demo_view.ticket.firstname
___________________________________________________________________________________________
namedParams:
- name: settings_for_system_time
type: TIMESTAMP
value:
string: 2022-11-14 16:00:00
__________________________________________________________________________________________
преобразованный запрос, после подстановки параметра FOR SYSTEM TIME: select count(*) from @tbl el LEFT JOIN demo_view.passenger FOR SYSTEM_TIME AS OF '2022-11-14 16:00:00' on @tbl.firstname.firstname = demo_view.ticket.firstname
Примеры запросов с системными и именованными параметрами
Пример недопустимой конструкции запроса с системными и именованными параметрами:
sql: select * FROM demo_view.ticket join demo_view.passenger FOR SYSTEM_TIME AS OF :p2 on demo_view.passenger.id =demo_view.ticket.passengerid
________________________________________________________________________________________________
namedParams:
- name: settings_for_system_time
type: TIMESTAMP
value:
string: 2022-11-14 16:00:00
- name: p1
type: TIMESTAMP
value:
string: 2022-11-14 15:00:00
__________________________________________________________________________________________
преобразованный запрос, после подстановки параметра FOR SYSTEM TIME: select * FROM demo_view.ticket FOR SYSTEM_TIME AS OF 2022-11-14 16:00:00 join demo_view.passenger FOR SYSTEM_TIME AS OF :p2 on demo_view.passenger.id =demo_view.ticket.passengerid
Пример запроса с системными и именованными параметрами в блоке where:
sql: select * FROM demo_view.ticket JOIN demo_view.passenger on demo_view.passenger.id =demo_view.ticket.passengerid WHERE passengerid=:p1 and price=:p2
___________________________________________________________________________________________________________________________________
namedParams:
- name: settings_for_system_time
type: TIMESTAMP
value: 2022-11-14 16:00:00
- name: p1
type: STRING
value:
string: 0fe26963-6cdf-4db6-b632-03825a408d35
- name: p2
type: DOUBLE
value: 719.4501969260996
__________________________________________________________________________________________
преобразованный запрос, после подстановки параметра FOR SYSTEM TIME: select * FROM demo_view.ticket FOR SYSTEM_TIME AS OF '2022-11-14 16:00:00' JOIN demo_view.passenger FOR SYSTEM_TIME AS OF '2022-11-14 16:00:00' on demo_view.passenger.id =demo_view.ticket.passengerid WHERE passengerid=:p1 and price=:p2