5. Дополнительные возможности
Инструкции данного раздела не выполняются в рамках первичной установки компонентов программы.
Необходимость выполнения действий данного раздела определяется в процессе эксплуатации программы.
5.1. Установки опциональных приложений
Сервера сбора, хранения и индексирования логов устанавливаются независимо от наличия или отсутствия других приложений. Конкретные средства логирования и мониторинга не входят в состав данного решения и выбираются в соответствии с требованиями конкретного ведомства.
Обязательно необходимо установить, как минимум один из серверов базы данных ADB (Greenplum), ADQM (Clickhouse) или ADG (Tarantool).
Обязательно нужно установить, как минимум одно программное обеспечение для работы со СМЭВ:
CМЭВ3-адаптер;
группа приложений состоящих из ПОДД-адаптера - Модуль исполнения запросов, Агент ПОДД, Диспетчер сообщений для ПОДД «Kafka» (ADSP).
Агент ПОДД и Диспетчер сообщений для ПОДД «Kafka» (ADSP) не входят в состав данного решения и устанавливаются отдельно, согласно соответствующей документации.
5.2. Материлиазованные представления
Материализованное представление — это набор записей, который является результатом исполнения SELECT-запроса.
Материализованное представление позволяет предварительно вычислить результат запроса и сохранить его для будущего использования. SELECT-запрос, на котором строится представление, может обращаться к данным одной или нескольких логических баз данных.
Материализованное представление строится на основе данных одной СУБД хранилища (далее — СУБД-источник), а его данные размещаются в других СУБД. Это позволяет создавать инсталляции, где одна СУБД служит полноценным хранилищем исходных данных, а остальные СУБД отвечают за быструю выдачу данных по запросам чтения. В текущей версии системы доступно создание материализованных представлений в ADQM, ADG и ADP на основе данных ADB.
Материализованное представление помогает ускорить запросы к данным в следующих случаях:
если представление содержит результаты сложного запроса, который на исходных данных выполняется дольше;
если запросы к представлению возвращают значительно меньше данных, чем запросы к исходным данным;
если запросы относятся к категории, которую СУБД хранилища, где размещены данные представления, выполняет более эффективно, чем СУБД-источник (например, ADG быстрее всех из поддерживаемых СУБД обрабатывает чтение по ключу).
Материализованное представление дает доступ к актуальным и архивным данным. Чтение горячих данных из представления недоступно: это позволяет избежать чтения изменений, загруженных из СУБД-источника только частично. Данные материализованного представления хранятся аналогично данным логических таблиц — в физических таблицах хранилища, которые автоматически создаются при создании представления (см. Рисунок - 5.4).
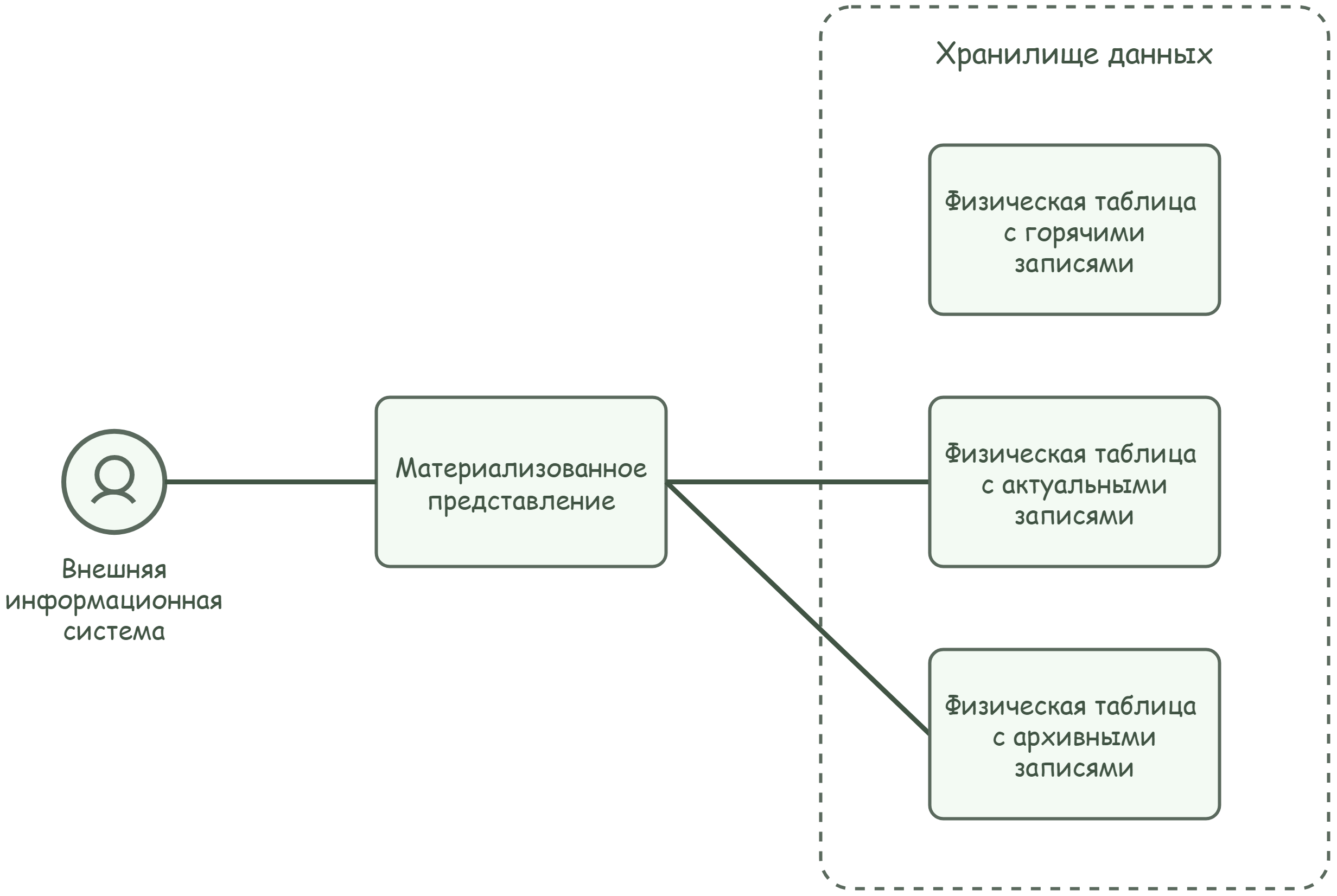
Рисунок - 5.4 Связи материализованного представления с физическими таблицами
Система поддерживает целостность данных материализованных представлений, размещенных в СУБД-приемнике, периодически синхронизируя их с СУБД-источником (см. Рисунок - 5.5).
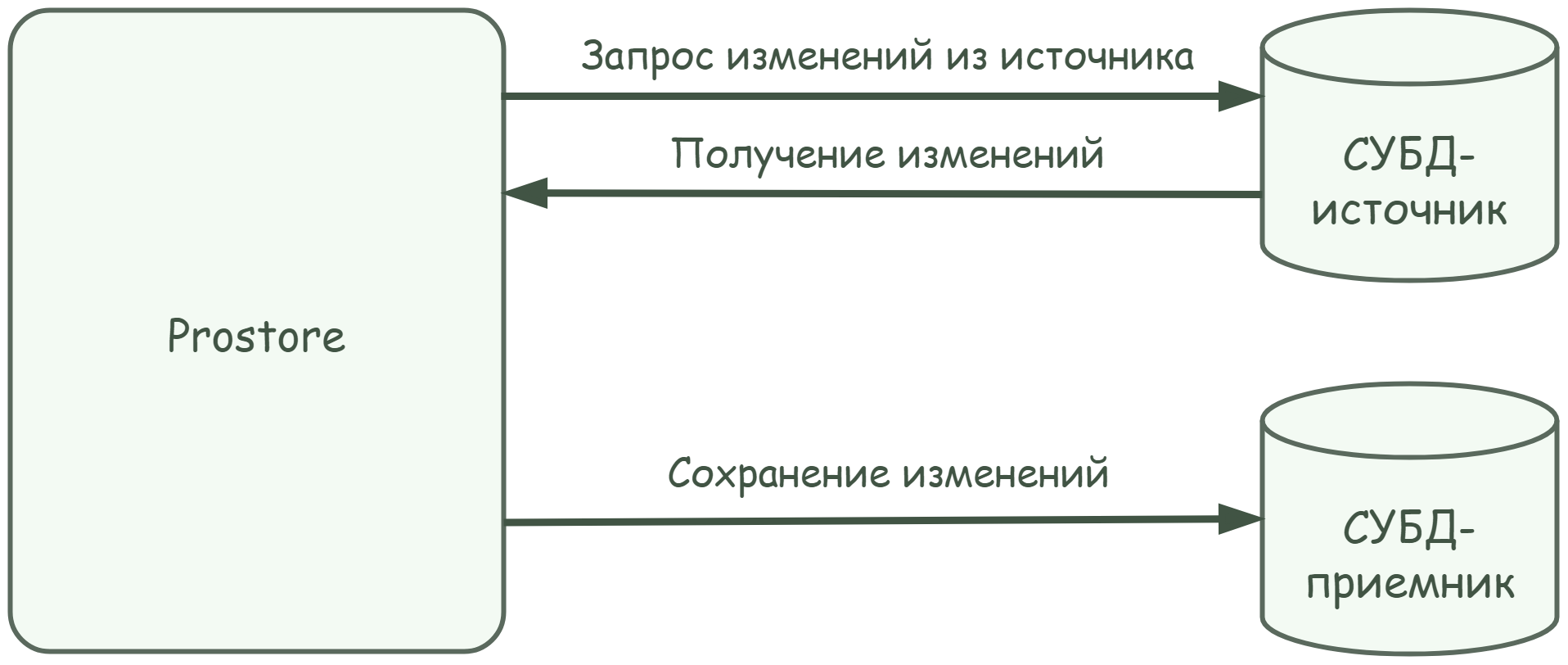
Рисунок - 5.5 Синхронизация материализованных представлений
Для материализованных представлений реализована возможность создания, чтения, записи, удаления из ADB в Postgres. Более подробная информация об операциях над мат.представлениями изложена в документации Prostore. Загрузка и обновление данных недоступны для материализованных представлений.
Примечание
Информацию о DDL-запросе, создавшем представление, можно получить с помощью запроса GET_ENTITY_DDL.
Примечание
По умолчанию система ведет статистику обработки запросов к данным логических сущностей. Чтобы получить статистику, выполните запрос GET_ENTITY_STATISTICS..
При запросе или выгрузке данных из материализованного представления можно указать момент времени, по состоянию на который запрашиваются данные. Если момент времени не указан, система возвращает (выгружает) данные, актуальные на момент последней синхронизации представления, иначе — данные, актуальные на запрашиваемый момент времени.
При запросе или выгрузке данных на указанный момент времени может оказаться, что материализованное представление отстало от СУБД-источника и не содержит запрошенные данные. В этом случае система перенаправляет запрос к исходным таблицам СУБД-источника (см. раздел Маршрутизация запросов к материализованным представлениям). Перенаправленный запрос может выполняться дольше, однако это позволяет получить данные, полностью актуальные на указанный момент времени.
Синхронизация материализованных представлений
Система периодически проверяет, нужно ли синхронизировать материализованные представления окружения с СУБД-источником. Периодичность проверки настраивается в конфигурации системы с помощью параметра MATERIALIZED_VIEWS_SYNC_PERIOD_MS; по умолчанию проверка запускается раз в 5 секунд.
Примечание
При необходимости синхронизацию материализованных представлений можно отключить, установив значение параметра MATERIALIZED_VIEWS_SYNC_PERIOD_MS равным 0.
Проверка материализованных представлений запускается по таймеру. Другие события (например, создание представления или загрузка данных) не запускают проверку представлений. При срабатывании таймера система проверяет, появились ли в СУБД-источнике дельты, закрытые после последней синхронизации и, если такие дельты появились, система синхронизирует материализованные представления с СУБД-источником.
Примечание
Материализованное представление, основанное на таблицах из разных логических баз данных, синхронизируется при наличии новых дельт в основной логической базе данных — в той, которой принадлежит представление.
Количество одновременно синхронизируемых представлений задается в конфигурации системы с помощью параметра MATERIALIZED_VIEWS_CONCURRENT. По умолчанию одновременно синхронизируется максимум два представления, а остальные, если они есть, ожидают следующего цикла проверки.
Данные представления синхронизируются отдельно по каждой закрытой дельте — с полным сохранением изменений, выполненных в этих дельтах. В каждой дельте для материализованного представления рассчитывается и сохраняется результат запроса, указанного при создании этого представления. Таким образом, материализованное представление имеет такой же уровень историчности данных, как и исходные логические таблицы, на которых построено представление.
Если системе не удалось синхронизировать материализованное представление, она делает несколько повторных попыток. Максимальное количество таких попыток регулируется параметром конфигурации MATERIALIZED_VIEWS_RETRY_COUNT. По умолчанию система делает до 10 попыток. Если количество попыток исчерпано, но представление так и не удалось синхронизировать, система прекращает попытки синхронизировать это представление. В случае перезапуска системы счетчики попыток синхронизации обнуляются, и система снова пытается синхронизировать представления, которые остались несинхронизированными.
Примечание
Статусы синхронизации материализованных представлений можно посмотреть с помощью запроса CHECK_MATERIALIZED_VIEW .
Пример синхронизации материализованного представления
Рассмотрим пример со следующими условиями:
логическая БД marketing содержит логическую таблицу
salesи материализованное представлениеsales_by_stores;- логическая БД содержит две дельты:
дельта 0: в таблицу sales загружено две записи (с идентификаторами 100 и 101);
дельта 1: в таблицу sales загружено еще две записи (с идентификаторами 102 и 103);
материализованное представление
sales_by_storesсодержит результат агрегации и группировки данных таблицыsalesи построено на основе следующего запроса:
CREATE MATERIALIZED VIEW marketing.sales_by_stores (
store_id INT NOT NULL,
product_code VARCHAR(256) NOT NULL,
product_units INT NOT NULL,
PRIMARY KEY (store_id, product_code)
)
DISTRIBUTED BY (store_id)
DATASOURCE_TYPE (adg)
AS SELECT store_id, product_code, SUM(product_units) FROM marketing.sales
WHERE product_code <> 'ABC0001'
GROUP BY store_id, product_code
DATASOURCE_TYPE = 'adb'
На рисунках ниже (см Рисунок - 5.6 и Рисунок - 5.7) показан порядок синхронизации материализованного представления sales_by_stores.
В каждой дельте рассчитывается и сохраняется сумма по столбцу product_units таблицы sales с группировкой по столбцам store_id и product_code.
При этом неважно, когда было создано материализованное представление: до дельты 0, после дельты 1 или в какой-то момент между этими дельтами.
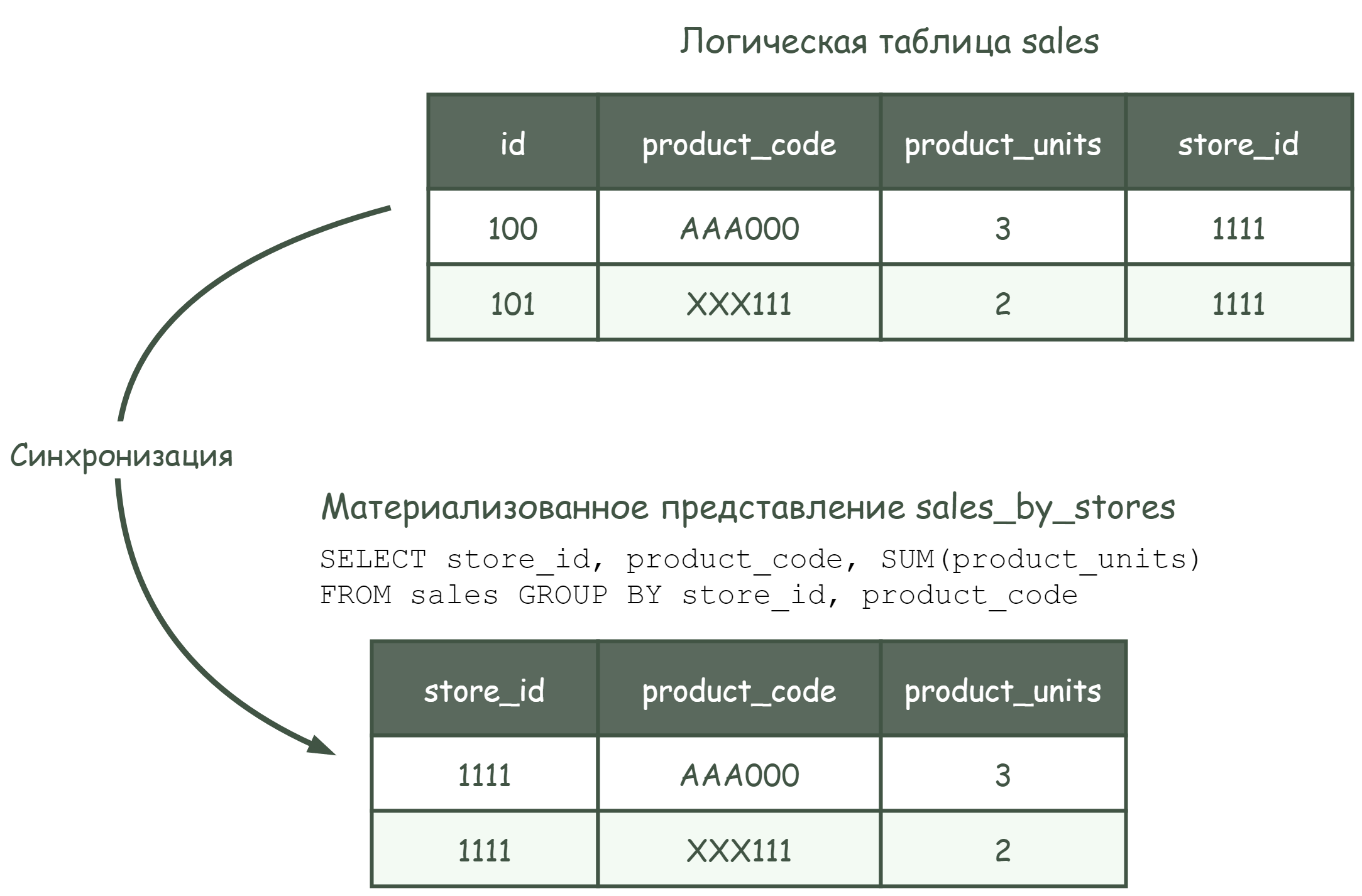
Рисунок - 5.6 Состояние данных на момент дельты 0
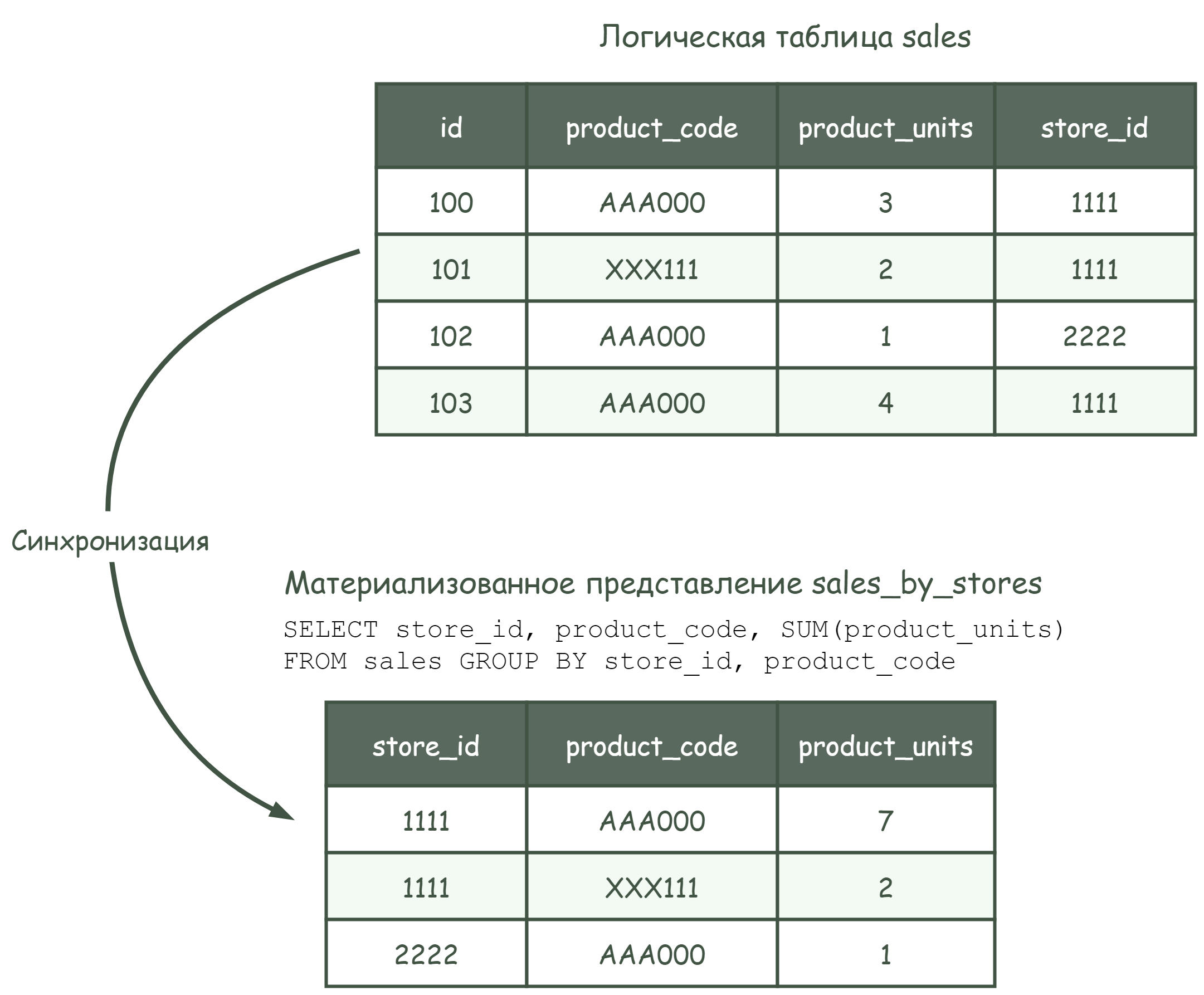
Рисунок - 5.7 Состояние данных на момент дельты 1
5.3. Маршрутизация запросов к материализованным представлениям
Запросы к данным материализованных представлений проходят все этапы маршрутизации, описанные выше, и затем — дополнительные этапы:
Если для материализованного представления не указано ключевое слово
FOR SYSTEM_TIME, запрос направляется в СУБД, где размещены данные этого представления. Из представления выбираются данные, актуальные на момент его последней синхронизации.Иначе, если ключевое слово
FOR SYSTEM_TIMEуказано, система проверяет, есть ли в представлении данные за запрашиваемый момент времени:Если в запросе есть ключевое слово
DATASOURCE_TYPE, а данных за запрашиваемый момент времени в представлении нет, в ответе возвращается исключение.- Если в запросе нет ключевого слова
DATASOURCE_TYPE: Если данные есть в представлении, запрос направляется в СУБД, где размещены данные этого представления.
Иначе запрос направляется к исходным таблицам СУБД-источника, на которых построено представление.
- Если в запросе нет ключевого слова
Примечание
В запросах к материализованным представлениям доступны не все выражения с ключевым словом FOR SYSTEM_TIME Подробнее см. в секции Доступность значений FOR SYSTEM_TIME раздела SELECT
5.4. Логирование
Лог-файлы компонентов могут быть найдены на соответствующих серверах, по относительным путям, описанным ниже (см. Таблица 5.1):
Наименование |
Относительный путь |
|---|---|
ClickHouse Server |
/var/log/clickhouse-server/clickhouse-server.log /var/log/clickhouse-server/clickhouse-server.err.log |
Greenplum Server |
/var/log/greenplum-server/greenplum-server.log /var/log/greenplum-server/greenplum-server.err.log |
Tarantool |
/var/log/tarantool-server/tarantool-server.log /var/log/tarantool-server/tarantool-server.err.log |
Apache Kafka |
/usr/lib/kafka/logs/*.log |
ПОДД-адаптер-Модуль исполнения запросов |
/opt/podd-migration/logs/application.log /opt/podd-adapter/logs/application.log |
СМЭВ3-адаптер |
/opt/smev3-adapter/logs/application.log |
ETL |
/opt/Airflow/logs /opt/spark/logs /opt/hadoop/logs |
REST-адаптер |
/opt/rest/logs |
5.5. Обновление
5.5.1. Менеджер кластера ADCM
Чтобы обновить ADCM вы должны сделать следующее:
Загрузить новый образ в докер:
docker pull arenadata/ADCM:latest
Остановить и удалить текущий контейнер:
docker stop ADCM docker rm ADCM
Создать новый контейнер как указано в документации ADCM: https://docs.arenadata.io/adcm/user/install.html
5.5.2. Диспетчер сообщений ADS
Обновление кластера ADS доступно с версии 1.4.11
ADCM предоставляет возможность обновления существующего кластера ADS.
Процесс обновления состоит из двух последовательных шагов:
Обновление бандла;
Обновление кластера.
В текущей версии доступно обновление кластеров как версий 1.3.X, так и 1.4.X
5.5.2.1. Обновление бандла
Для обновления бандла необходимо:
Загрузить бандл ADS новой версии. После его загрузки на вкладке Clusters в строке кластера с более старой версией бандла в колонке Upgrade появляется пиктограмма, указывающая на возможность обновления (см. Рисунок - 5.8).
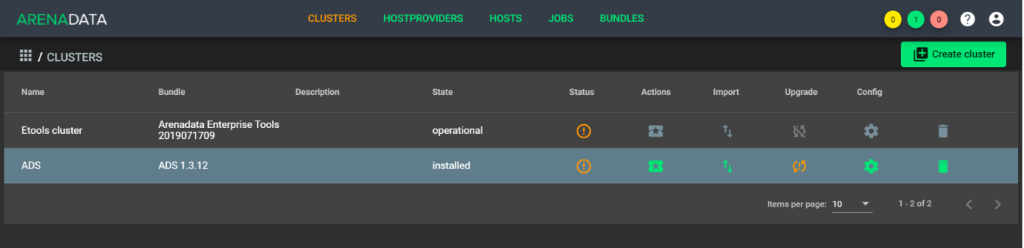
Рисунок - 5.8 Доступно обновление бандла
Нажать значок в колонке Upgrade и выбрать доступную требуемую версию из списка (см. Рисунок - 5.9).
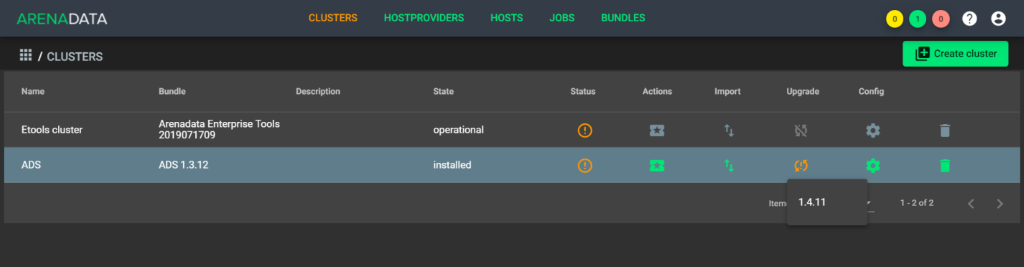
Рисунок - 5.9 Доступные обновления
В открывшемся диалоговом окне подтвердить действие, после чего кластер меняет состояние на
upgrade from 1.3.Xилиupgrade from 1.4.Xв зависимости от установленной версии бандла (см. Рисунок - 5.10).
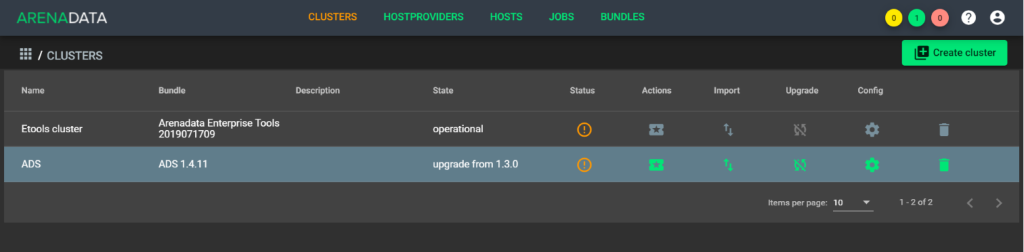
Рисунок - 5.10 Изменение состояния кластера после обновления
Примечание
Если заданные по умолчанию настройки сервисов Zookeeper, Kafka изменены, то их необходимо скопировать и сохранить прежде, чем приступить к обновлению конфигураций сервисов.
В частности, это касается файлов nifi.properties, zoo.cfg и server.properties сервиcов Nifi, Zookeeper и Kafka соответственно.
5.5.2.2. Обновление кластера
После завершения операции Upgrade Configs в кластере становится доступным действие Upgrade. Данная операция применяет новые настройки, полученные на предыдущем шаге, и обновляет пакеты всех сервисов до указанных версий.
В поле Actions для обновляемого кластера нажать на значок и выбрать действие Upgrade (см. Рисунок - 5.11).
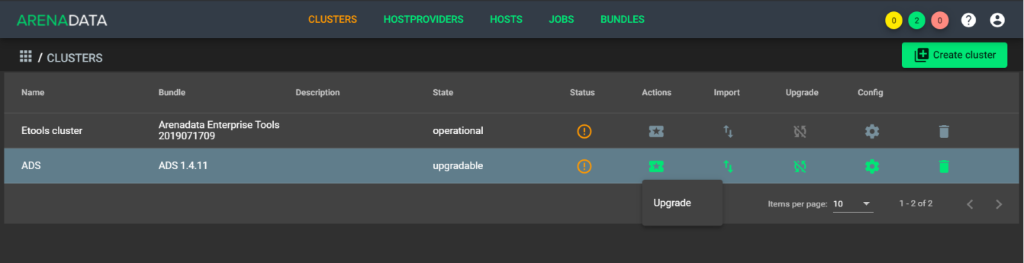
Рисунок - 5.11 Обновление пакетов сервисов
Подтвердить действие в открывшемся диалоговом окне нажатием кнопки Run.
После успешного завершения операции Upgrade кластер меняет свое состояние на installed.
Если заданные по умолчанию настройки сервисов были изменены перед обновлением, то после операции Upgrade Configs необходимо выполнить действия для соответствующих сервисов:
Перейти к настройкам сервиса Zookeeper, проверить раздел zoo.cfg и при необходимости внести сохраненные ранее изменения;
Перейти к настройкам сервиса Kafka, проверить разделы Main и server.properties и при необходимости внести сохраненные ранее изменения;
5.6. Миграция из Bare metal варианта установки в Kubernetes
В процессе миграции необходимо отделить модули, которым предстоит переехать в Kubernetes от тех, которые остаются в Bare Metal режиме инсталляции. Миграции подлежат модули адаптеров Витрины данных и модули Prostore. Kafka, Zookeeper и СУБД остаются вне Kubernetes.
Для мигрирующего модуля оформляется K8S deployment, конфигурация application.yml и logback.xml размещаются в K8S configmap.
При смене версии модуля необходимо актуализировать конфигурацию application.yml в соответствии с новой версией документации.
Альтернативно, вместо использования application.yml конфигурировать приложение можно через переменные окружения K8S контейнера.
Query-execution модуль может работать только в рамках одного пода.
Для модулей, имеющих HTTP-интерфейс, дополнительно формируется K8S service, обеспечивающий маршрутизацию к экземплярам модулей.
На диаграмме (см. Рисунок - 5.12) представлена миграция модуля исполнения запросов и Prostore.
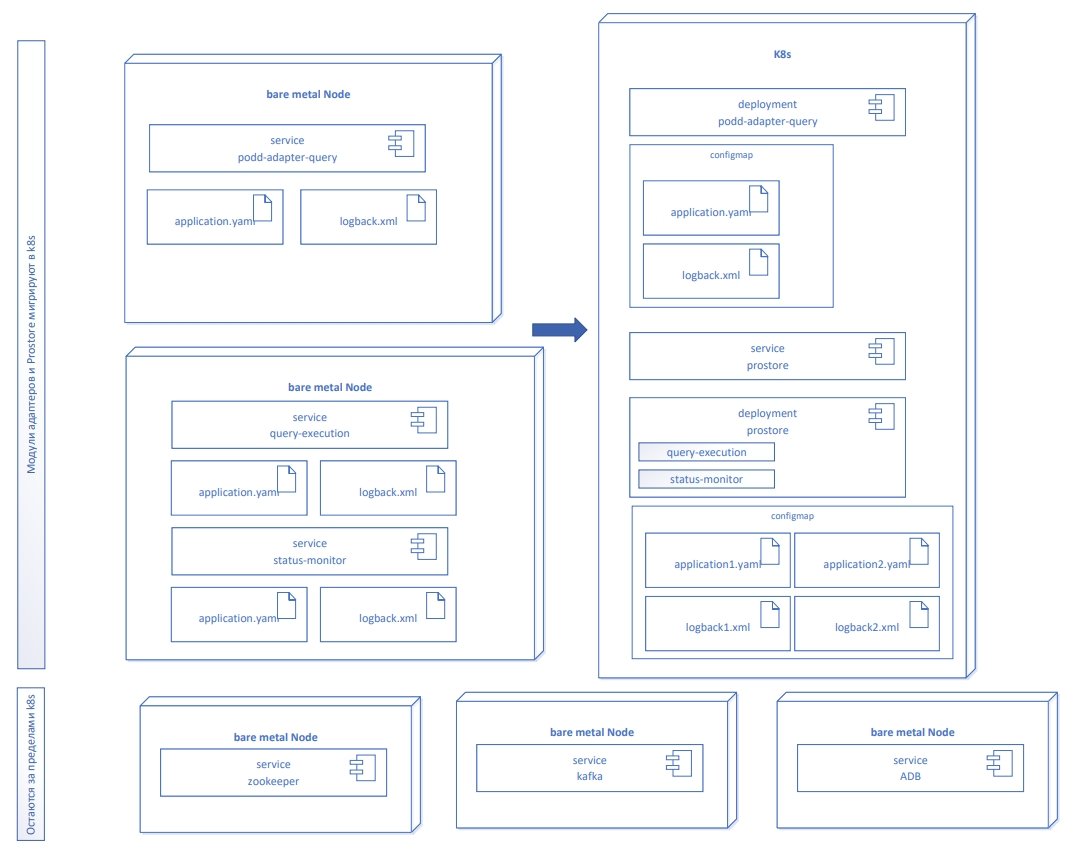
Рисунок - 5.12 Миграция в Kubernetes
Для миграции модуля в его корневой директории необходимо создать манифест файлы с инструкциями:
deployment;
service;
configmap.
Примеры создания манифест файлов приведены ниже.
Создать объекты из манифест файлов в Kubernetes можно при помощи утилиты kubectl:
kubectl apply -f <FILE_NAME>
5.6.1. Примеры инструкций по развертыванию ПОДД-адаптера — Модуля исполнения запросов в Kubernetes
Пример создания файла deployment
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/instance: podd-adapter-query
app.kubernetes.io/name: podd-adapter-query
name: podd-adapter-query
spec:
progressDeadlineSeconds: 600
replicas: 2
revisionHistoryLimit: 10
selector:
matchLabels:
app.kubernetes.io/instance: podd-adapter-query
app.kubernetes.io/name: podd-adapter-query
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
template:
metadata:
annotations:
prometheus.io/port: "9837"
prometheus.io/scrape: "true"
creationTimestamp: null
labels:
app.kubernetes.io/instance: podd-adapter-query
app.kubernetes.io/name: podd-adapter-query
spec:
containers:
# Основной контейнер приложения
# Настройки приложения через переменные среды
- env:
- name: AGENT_TOPIC_PREFIX
value: demo_view.
- name: DTMDB_COUNT
value: "5"
- name: DTMDB_DRIVER
value: ru.datamart.prostore.jdbc.Driver
- name: DTMDB_FETCH_SIZE
value: "1000"
- name: DTMDB_HOST
value: prostore
- name: DTMDB_MAX_POOL_SIZE
value: "5"
- name: DTMDB_PORT
value: "9090"
- name: DTMDB_SUBPROTOCOL
value: prostore
- name: ENVIRONMENT_NAME
value: k8s
- name: JAVA_OPTS
value: -Xmx2g
- name: JDBC_VERSION
value: 5.8.0
- name: K8S_SERVICE_NAME
value: podd-adapter-query
- name: KAFKA_BOOTSTRAP_SERVERS
value: demo-dtm-kz01.ru-central1.internal:9092
- name: LLR_ROWS_LIMIT
value: "1000"
- name: LOGBACK_PARAM
value: --logging.config=/app/fluent-bit/logback.xml
- name: PFS_HOST
value: pf.k8s.ru
- name: PFS_PORT
value: "80"
- name: PF_REQUEST_LOG_ENABLED
value: "true"
- name: PF_RESPONSE_LOG_ENABLED
value: "true"
- name: QUERY_REQUEST_LOG_ENABLED
value: "true"
- name: QUERY_RESPONSE_LOG_ENABLED
value: "true"
- name: TZ
value: Europe/Moscow
- name: VERTICLE_QUERY_REQUEST_INSTANCES
value: "1"
- name: VERTX_DTMPOOL
value: "10"
- name: VERTX_POOL_EVENTLOOPPOOL
value: "10"
- name: VERTX_POOL_QUERYPOOL
value: "20"
- name: VERTX_POOL_WORKERPOOL
value: "10"
- name: ZOOKEEPER_DS_ADDRESS
value: demo-dtm-kz01.ru-central1.internal:2181
- name: ZOOKEEPER_HOSTS
value: demo-dtm-kz01.ru-central1.internal
- name: ZOOKEEPER_PORT
value: "2181"
image: cr.yandex/crpfi51tpl7q2b98nn66/podd-adapter-query:5.1.10-develop-43
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /version
port: http
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
name: podd-adapter-query
ports:
- containerPort: 8083
name: http
protocol: TCP
- containerPort: 9837
name: metrics
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /version
port: http
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: "2"
memory: 3Gi
requests:
cpu: "1"
memory: 1Gi
securityContext: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
# Директория хранения логов приложения
- mountPath: /fluent-bit/logs/
name: fluent-bit-logs
# Директория хранения logback файла
- mountPath: /app/fluent-bit/
name: fluent-bit-logback
# Контейнер для сбора и передачи логов
- env:
- name: DEPLOYMENTUNIT
value: podd-adapter-query
image: fluent/fluent-bit:1.9.6
imagePullPolicy: IfNotPresent
name: fluent-bit
resources: {}
securityContext: {}
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
# Директория хранения логов приложения
- mountPath: /fluent-bit/logs/
name: fluent-bit-logs
# Настройки fluentbit
- mountPath: /fluent-bit/etc/
name: fluent-bit-config
dnsPolicy: ClusterFirst
imagePullSecrets:
- name: ycr
restartPolicy: Always
schedulerName: default-scheduler
securityContext: {}
serviceAccount: default
serviceAccountName: default
terminationGracePeriodSeconds: 30
volumes:
- configMap:
defaultMode: 420
items:
- key: parsers.conf
path: parsers.conf
- key: fluent-bit.conf
path: fluent-bit.conf
- key: scripts.lua
path: scripts.lua
name: fluent-bit-config-json-demo
name: fluent-bit-config
- configMap:
defaultMode: 420
items:
- key: logback.xml
path: logback.xml
name: fluent-bit-logback-json-demo
name: fluent-bit-logback
- emptyDir: {}
name: fluent-bit-logs
Пример создания файла service
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/instance: podd-adapter-query
app.kubernetes.io/name: podd-adapter-query
name: podd-adapter-query
spec:
ports:
- name: http
port: 8083
protocol: TCP
targetPort: http
selector:
app.kubernetes.io/instance: podd-adapter-query
app.kubernetes.io/name: podd-adapter-query
sessionAffinity: None
type: ClusterIP
Пример создания файла configmap
# В STDOUT выводит в JSON формате с полями подходящими для ГОСТЕХ
# В FILE_FLUENT выводит JSON формате с полями для внутреннего пользования стенда разработки и тестирования
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-logback-json-demo
namespace: default
data:
logback.xml: |
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<property name="serviceName" value="${K8S_SERVICE_NAME:-}"/>
<property name="instanceID" value="${HOSTNAME:-}"/>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<includeContext>false</includeContext>
<includeTags>true</includeTags>
<includeMdc>true</includeMdc>
<mdcKeyFieldName>requestId=traceId</mdcKeyFieldName>
<fieldNames>
<logger>className</logger>
<timestamp>dateTime</timestamp>
<level>logLevel</level>
<stackTrace>stackTrace</stackTrace>
<thread>threadName</thread>
<version>[ignore]</version>
<levelValue>[ignore]</levelValue>
</fieldNames>
<customFields>{"instanceID": "${instanceID}", "serviceName": "${serviceName}"}</customFields>
</encoder>
</appender>
<appender name="FILE_FLUENT" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/fluent-bit/logs/log.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/fluent-bit/logs/log.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>1</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
<append>false</append>
<encoder class="net.logstash.logback.encoder.LogstashEncoder">
<includeContext>false</includeContext>
<includeTags>true</includeTags>
<includeMdc>true</includeMdc>
<fieldNames>
<version>[ignore]</version>
<levelValue>[ignore]</levelValue>
</fieldNames>
</encoder>
</appender>
<root level="info" additivity="false">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILE_FLUENT"/>
</root>
</configuration>
Пример создания файла configmap для Fluentbit
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config-json-demo
data:
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File /fluent-bit/etc/parsers.conf
[INPUT]
Name tail
Path /fluent-bit/logs/log.log
Tag services
Buffer_Chunk_Size 400k
Buffer_Max_Size 6MB
Mem_Buf_Limit 6MB
Parser docker
Refresh_Interval 20
[FILTER]
Name record_modifier
Match *
Record hostname "${HOSTNAME}"
Record serviceName "${DEPLOYMENTUNIT}"
[OUTPUT]
Name forward
Match *
host demo-dtm-vector01.ru-central1.internal
port 24228
parsers.conf: |
[PARSER]
Name docker
Format json
Key_Name log
Time_Key @timestamp
scripts.lua: ""
5.6.2. Примеры инструкций по развертыванию Prostore в Kubernetes
Пример создания файла deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: prostore
namespace: dtm-dev
uid: 46d6e239-427e-4dad-a988-4ce44a53b75e
resourceVersion: '630322324'
generation: 39
creationTimestamp: '2023-03-03T07:36:03Z'
labels:
app.kubernetes.io/instance: prostore
app.kubernetes.io/managed-by: Helm
app.kubernetes.io/name: prostore
app.kubernetes.io/version: 6.7.0
helm.sh/chart: prostore-0.2.0
k8slens-edit-resource-version: v1
annotations:
deployment.kubernetes.io/revision: '35'
helm.sh/template: 1.0.1
meta.helm.sh/release-name: prostore
meta.helm.sh/release-namespace: dtm-dev
selfLink: /apis/apps/v1/namespaces/dtm-dev/deployments/prostore
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/instance: prostore
app.kubernetes.io/name: prostore
template:
metadata:
creationTimestamp: null
labels:
app.kubernetes.io/instance: prostore
app.kubernetes.io/name: prostore
annotations:
checksum/config: 2d5e69a4edfcbaf92ee27d05855c797f1a825c16c08d78b82db62da024cc7b1d
helm.sh/template: 1.0.1
kubectl.kubernetes.io/restartedAt: '2023-11-24T09:25:44Z'
rollout: QMnGFyw4ilxm
spec:
volumes:
- name: logs-q
emptyDir: {}
- name: logs-s
emptyDir: {}
- name: logback-q
configMap:
name: prostore.config
items:
- key: logback-q.xml
path: logback.xml
defaultMode: 420
- name: logback-s
configMap:
name: prostore.config
items:
- key: logback-s.xml
path: logback.xml
defaultMode: 420
- name: fluent-bit-config-q
configMap:
name: prostore.config
items:
- key: parsers.conf
path: parsers.conf
- key: fluent-bit-q.conf
path: fluent-bit.conf
defaultMode: 420
- name: fluent-bit-config-s
configMap:
name: prostore.config
items:
- key: parsers.conf
path: parsers.conf
- key: fluent-bit-s.conf
path: fluent-bit.conf
defaultMode: 420
containers:
- name: prostore
image: registry.gosuslugi.local/dtm-dev/query-execution:6.8.1
command:
- java
- '-XX:MaxRAMPercentage=80.0'
- '-jar'
- dtm-query-execution-core.jar
args:
- '--logging.config=logback.xml'
ports:
- name: http-q
containerPort: 9090
protocol: TCP
- name: metrics-q
containerPort: 8080
protocol: TCP
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
- name: ADB_HOST
value: 10.81.0.99
- name: ADB_MPPW_DEFAULT_MESSAGE_LIMIT
value: '1000'
- name: ADB_MPPW_FDW_TIMEOUT_MS
value: '2000'
- name: ADB_MPPW_USE_ADVANCED_CONNECTOR
value: 'true'
- name: ADB_NAME
- name: ADB_PASS
value: dtm
- name: ADB_USERNAME
value: dtm
- name: ADP_HOST
value: postgres
- name: ADP_PASS
value: dtm
- name: ADP_PORT
value: '5432'
- name: ADP_USERNAME
value: dtm
- name: ADP_MAX_POOL_SIZE
value: '4'
- name: KAFKA_JET_POLL_DURATION_MS
value: '1000'
- name: KAFKA_JET_POLL_BUFFER_SIZE
value: '1000'
- name: KAFKA_JET_DB_BUFFER_SIZE
value: '3000'
- name: ADP_EXECUTORS_COUNT
value: '4'
- name: ADP_REST_START_LOAD_URL
value: http://kafka-postgres-writer:8096/newdata/start
- name: ADP_REST_STOP_LOAD_URL
value: http://kafka-postgres-writer:8096/newdata/stop
- name: ADP_MPPW_CONNECTOR_VERSION_URL
value: http://kafka-postgres-writer:8096/versions
- name: ADP_MPPR_QUERY_URL
value: http://kafka-postgres-reader:8094/query
- name: ADP_MPPR_CONNECTOR_VERSION_URL
value: http://kafka-postgres-reader:8094/versions
- name: CORE_PLUGINS_ACTIVE
value: ADP
- name: DTM_NAME
value: dev
- name: EDML_CHANGE_OFFSET_TIMEOUT_MS
value: '180000'
- name: EDML_DATASOURCE
value: ADP
- name: EDML_DEFAULT_CHUNK_SIZE
value: '500'
- name: EDML_FIRST_OFFSET_TIMEOUT_MS
value: '180000'
- name: KAFKA_BOOTSTRAP_SERVERS
value: kafka-0.kafka-headless:9092
- name: KAFKA_JET_WRITERS
value: http://kafka-jet-writer:8080
- name: KAFKA_STATUS_EVENT_ENABLED
value: 'true'
- name: KAFKA_STATUS_EVENT_TOPIC
value: status.event
- name: KAFKA_STATUS_EVENT_WRITE_OPERATIONS_ENABLED
value: 'true'
- name: >-
LOGGING_LEVEL_RU_DATAMART_PROSTORE_QUERY_EXECUTION_CORE_BASE_SERVICE
value: warn
- name: TZ
value: Europe/Moscow
- name: ZOOKEEPER_DS_ADDRESS
value: zookeeper-0.zookeeper-headless:2181
- name: ZOOKEEPER_KAFKA_ADDRESS
value: zookeeper-0.zookeeper-headless:2181
resources:
limits:
cpu: '1'
memory: 4Gi
requests:
cpu: 125m
memory: 128Mi
volumeMounts:
- name: logs-q
mountPath: /app/logs
- name: logback-q
mountPath: /app/logback.xml
subPath: logback.xml
livenessProbe:
httpGet:
path: /actuator/health
port: metrics-q
scheme: HTTP
initialDelaySeconds: 20
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
readinessProbe:
httpGet:
path: /actuator/health
port: metrics-q
scheme: HTTP
initialDelaySeconds: 20
timeoutSeconds: 5
periodSeconds: 10
successThreshold: 1
failureThreshold: 3
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: Always
- name: fluent-bit-q
image: registry.gosuslugi.local/proxy-docker.io/fluent/fluent-bit:1.9.6
env:
- name: POD_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.name
- name: POD_NAMESPACE
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
- name: POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: NODE_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: spec.nodeName
resources:
limits:
cpu: 100m
memory: 256Mi
requests:
cpu: 100m
memory: 256Mi
volumeMounts:
- name: logs-q
mountPath: /app/logs
- name: fluent-bit-config-q
mountPath: /fluent-bit/etc/
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
imagePullPolicy: IfNotPresent
restartPolicy: Always
terminationGracePeriodSeconds: 30
dnsPolicy: ClusterFirst
securityContext: {}
imagePullSecrets:
- name: registry.gosuslugi.local
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 25%
maxSurge: 25%
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
Пример создания файла service
apiVersion: v1
kind: Service
metadata:
name: prostore
spec:
ports:
- name: jdbc
port: 9090
protocol: TCP
targetPort: jdbc
selector:
app.kubernetes.io/instance: prostore
app.kubernetes.io/name: prostore
sessionAffinity: None
type: ClusterIP
Пример создания файла configmap
# В STDOUT выводит в простом "читаемом" формате
# В FILE_FLUENT выводит в logfmt формате с полями для внутреннего пользования стенда разработки и тестирования
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-logback
data:
logback.xml: |
<configuration>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>
<Pattern>
%d{yyyy-MM-dd HH:mm:ss.SSS} %-5level %logger{36} - %msg%n
</Pattern>
</pattern>
</layout>
</appender>
<appender name="FILE_FLUENT" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>/fluent-bit/logs/log.log</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>/fluent-bit/logs/log.%d{yyyy-MM-dd}.log</fileNamePattern>
<maxHistory>1</maxHistory>
<totalSizeCap>1GB</totalSizeCap>
</rollingPolicy>
<append>false</append>
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>
<Pattern>
@timestamp="%d{yyyy-MM-dd'T'HH:mm:ss.SSSXXX, UTC}" level=%level threadName="%thread" logger="%logger" message="%replace(%replace(%m){'\n','\\n'}){'\"','\''}" exception="%replace(%replace(%ex){'\"','\''}){'\n','\\n'}%nopex" \n
</Pattern>
</pattern>
</layout>
</appender>
<root level="debug" additivity="false">
<appender-ref ref="STDOUT"/>
<appender-ref ref="FILE_FLUENT"/>
</root>
</configuration>
Пример создания файла configmap для Fluentbit
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config-demo
data:
fluent-bit.conf: |
[SERVICE]
Flush 1
Log_Level info
Daemon off
Parsers_File /fluent-bit/etc/parsers.conf
[INPUT]
Name tail
Path /fluent-bit/logs/log.log
Tag services
Buffer_Chunk_Size 400k
Buffer_Max_Size 6MB
Mem_Buf_Limit 6MB
Parser logfmt
Refresh_Interval 20
[FILTER]
Name record_modifier
Match *
Record hostname "${HOSTNAME}"
Record serviceName "${DEPLOYMENTUNIT}"
[OUTPUT]
Name forward
Match *
host demo-dtm-vector01.ru-central1.internal
port 24228
parsers.conf: |
[PARSER]
Name logfmt
Format logfmt
scripts.lua: ""