4. Установка программы
Установка витрины данных производится без необходимости доступа к сети Интернет для скачивания компонент.
4.1. Порядок установки
Проверить соответствие серверов техническим характеристикам (см. раздел Требования к серверам).
Выполнить предварительные действия перед установкой программы (см. раздел Предварительные действия).
Установить на серверы, в соответствующем порядке, следующее программное обеспечение:
Arenadata Cluster Manager (ADCM) - при условии использования CentOS 7.9;
Arenadata Streaming (ADS) - при условии использвания CentOS 7.9;
коннектор Kafka-Postgres;
ProStore;
СМЭВ QL Сервер;
СМЭВ3-адаптер;
ПОДД-адаптера - Модуль исполнения запросов;
ПОДД-адаптер – Модуль MPPR;
ПОДД-адаптер – Модуль MPPW;
ПОДД-адаптер – Модуль импорта данных табличных параметров;
ПОДД-адаптер – Модуль группировки данных табличных параметров;
ПОДД-адаптер – ПОДД-адаптер – Wrapper;
Data-uploader – Модуль исполнения асинхронных заданий;
REST-uploader – Модуль асинхронной загрузки данных из сторонних источников;
ПОДД-адаптер – Модуль подписки;
BLOB-адаптер;
Сервис формирования документов;
ETL;
CSV-uploader;
REST-адаптер;
Counter-provider.
Проверить работу всех компонентов программы (см. раздел Проверка программы).
Версии компонентов программы приведены в разделе «Состав компонентов в дистрибутиве» документа «Техническое описание программы ПО «Витрина данных НСУД»».
Примечание
Описание настроек модулей приведено в Руководстве администратора ПО «Витрина данных НСУД».
4.2. Установка ПО ProStore
Установка ProStore должна осуществляться после установки СУБД и брокера сообщений.
ПО ProStore поставляется в виде дистрибутива с компонентами в jar-файлах.
Процесс установки состоит из следующих действий приведен в разделе Сборка и развертывание документации Prostore.
4.3. Установка СМЭВ QL Сервера
4.3.1. Процесс установки
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.3.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файлов:
application.yaml- конфигурирует поведение сервера;credentials.yaml- конфигурирует представление сервера.
Пример файлов конфигурации и возможные настройки модуля см. в разделе Конфигурирование сервера Руководства администратора.
4.3.1.2. Загрузка JAR-файла на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.4. Установка СМЭВ3-адаптера
4.4.1. Установка модуля
Действия по установке выполняются через SSH консоль технологического пользователя.
4.4.1.1. Установка КриптоПро
Установка СМЭВ3-адаптера возможна, только если были добавлены ключи (контейнер закрытого ключа) для сервиса КриптоПро.
В случае использования для электронной подписи сервиса КриптоПро, необходимо предварительно выполнить шаги:
скачать КриптоПро JCP (https://www.cryptopro.ru/download?pid=129) для Java JDK на сервер, где будет установлен СМЭВ3–адаптер;
установить загруженное ПО, следуя инструкции и документации на официальном сайте;
получить сертификат для установки от уполномоченных лиц и установить его в КриптоПро.
4.4.2. Процесс установки
Модуль СМЭВ3-адаптер поставляется в виде JAR-файла. В поставку также входят следующие файлы:
файл настроек конфигурации модуля СМЭВ3-адаптер
application.yml;файлы для подключения к ProStore: JDBC–драйвер (
dtm-jdbc-driver-*.*.*.jar) иcommons-lang3-3.12.0.jar;сконфигурированные pebble-шаблоны.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить JAR-файл модуля.
Проверить установку модуля.
4.4.2.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация СМЭВ3-адаптер (application.yml) Руководства администратора.
4.4.2.2. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/smev3-adapter.
В случае, если ранее была установлена старая версия СМЭВ3-адаптера, сделайте его резервную копию.
4.4.2.3. Загрузка файлов на сервер
Загрузите в созданную на предыдущем шаге папку:
JAR-файл модуля;
файл настроек конфигурации модуля СМЭВ3-адаптер (
application.yml);файлы JDBC-драйвер (
dtm-jdbc-driver-*.*.*.jar) иcommons-lang3-3.12.0.jarдля подключения к ProStore;сконфигурированные pebble-шаблоны.
4.4.2.4. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.5. Установка ПОДД-адаптера - Модуль исполнения запросов
4.5.1. Процесс установки
Внимание
Данное руководство описывает процесс установки ПОДД-адаптера - Модуль исполнения запросов в «Витрину данных НСУД», для «Витрины данных Лайт» модуль будет добавлен автоматически при первоначальной установке программы.
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.5.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml для Модуля исполнения запросов см. в разделе Конфигурация ПОДД-адаптера - Модуль исполнения запросов (application.yml)
Руководства администратора ПО «Витрина данных НСУД».
Примечание
Значения настроек MYSQL_USER для MariaDB и SUBSCR_DB_USER для Модуля исполнения запросов, а также MYSQL_PASSWORD и SUBSCR_DB_PASS, должны совпадать.
4.5.1.2. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.6. Установка ПОДД-адаптер – Модуль MPPR
4.6.1. Процесс установки
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.6.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла application.yml, пример которого и возможные
настройки конфигурации модуля см. в разделе Конфигурация ПОДД-адаптера - Модуль MPPR (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.6.1.2. Загрузка JAR-файла на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название jar-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.6.1.3. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.7. Установка ПОДД-адаптер-Модуль MPPW
4.7.1. Установка модуля
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.7.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла application.yml, пример которого и возможные
настройки конфигурации модуля см. в разделе см. Конфигурация модуля ПОДД-адаптер - Модуль MPPW (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.7.1.2. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-mppw.
В случае, если ранее была установлена старая версия Модуль MPPW, сделайте его резервную копию.
4.7.1.3. Загрузка файлов на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/opt/podd-adapter-mppw
где,
file.jar- название jar-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-mppw- директория на сервере, в которую будет загружен файл.
4.7.1.4. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.8. Установка ПОДД-адаптер – Модуль импорта данных табличных параметров
4.8.1. Установка модуля
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.8.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе
Конфигурация модуля ПОДД-адаптер - Модуль импорта данных табличных параметров (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.8.1.2. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-import-tp.
В случае, если ранее была установлена старая версия Модуля импорта данных табличных параметров, сделайте его резервную копию.
4.8.1.3. Загрузка файлов на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/podd-adapter-import-tp
где,
file.jar- название jar-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-import-tp- директория на сервере, в которую будет загружен файл.
4.8.1.4. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.9. Установка ПОДД-адаптер – Модуль группировки данных табличных параметров
4.9.1. Установка модуля
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.9.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе
Конфигурация модуля ПОДД-адаптер – Модуль группировки данных табличных параметров (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.9.1.2. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-group-tp.
В случае, если ранее была установлена старая версия Модуля группировки данных табличных параметров, сделайте его резервную копию.
4.9.1.3. Загрузка файлов на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/opt/podd-adapter-group-tp
где,
file.jar- название jar-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-group-tp- директория на сервере, в которую будет загружен файл.
4.9.1.3.1. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.10. Установка ПОДД-адаптер – Wrapper
4.10.1. Установка модуля
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.10.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе
Конфигурация модуля ПОДД-адаптер - Wrapper (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.10.1.2. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-avro-defragmentator.
В случае, если ранее была установлена старая версия модуля ПОДД-адаптер - Wrapper, сделайте его резервную копию.
4.10.1.3. Загрузка файлов на сервер
Загрузите в созданную на предыдущем шаге папку:
JAR-файл модуля;
файл настроек конфигурации модуля ПОДД-адаптер - Wrapper (application.yml);
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/opt/podd-avro-defragmentator
где,
file.jar- название JAR-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-avro-defragmentator- директория на сервере, в которую будет загружен файл.
4.11. Установка модуля группировки чанков репликации
4.11.1. Процесс установки
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.11.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла application.yml, пример которого и
возможные настройки конфигурации модуля см. в разделе Конфигурация Модуля группировки чанков репликации (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.11.1.2. Загрузка JAR-файла на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название jar-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.12. Установка DATA-uploder – Модуль исполнения асинхронных заданий
4.12.1. Процесс установки
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.12.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе
Конфигурация модуля DATA-Uploader (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.12.1.2. Загрузка JAR-файла на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.13. Установка REST-uploader – Модуль асинхронной загрузки данных из сторонних источников
4.13.1. Процесс установки
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.13.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля REST-Uploader (application.yml)
Руководства администратора ПО «Витрина данных НСУД».
4.13.1.2. Загрузка JAR-файла на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.14. Установка ПОДД-адаптер – Модуль подписки
4.14.1. Установка модуля
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.14.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе
Конфигурация модуля ПОДД-адаптер - Модуль подписок (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.14.1.2. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-replicator.
В случае, если ранее была установлена старая версия Модуля подписки, сделайте его резервную копию.
4.14.1.3. Загрузка файлов на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/opt/podd-adapter-replicator
где,
file.jar- название JAR-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-replicator- директория на сервере, в которую будет загружен файл.
4.14.1.4. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.15. Установка BLOB-адаптер
4.15.1. Установка модуля
Модуль BLOB-адаптер поставляется в виде jar-файла.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить jar-файл модуля.
Проверить установку модуля.
4.15.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. Конфигурация BLOB-адаптера (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.15.1.2. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/blob-adapter.
В случае, если ранее была установлена старая версия модуля BLOB-адаптер, сделайте его резервную копию.
4.15.1.3. Загрузка файлов на сервер
Загрузите в созданную на предыдущем шаге папку:
jar-файл модуля;
файл настроек конфигурации модуля BLOB-адаптер (
application.yml).
4.16. Установка Сервиса формирования документов
4.16.1. Установки модуля
Действия по установке выполняются через SSH консоль технологического пользователя.
4.16.1.1. Установка модуля
Модуль Сервис формирования документов поставляется в виде JAR-файла.
В поставку также входят следующие файлы:
файл настроек конфигурации Сервиса формирования документов (
application.yml);файлы для подключения к Prostore: JDBC-драйвер (
dtm-jdbc-driver-*.*.*.jarиcommons-lang3-3.12.0.jar).
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить JAR-файл модуля.
Проверить установку модуля.
4.16.1.2. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе
Конфигурация Сервиса Формирования документов (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.16.1.3. Добавление папки для загрузки файлов модуля
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/printable-form-service.
В случае, если ранее была установлена старая версия Сервиса формирования документов, сделайте его резервную копию.
4.16.1.4. Загрузка файлов на сервер
Загрузите в созданную на предыдущем шаге папку:
JAR-файл модуля;
файл настроек конфигурации модуля Сервис формирования документов (
application.yml);файлы JDBC-драйвер (
dtm-jdbc-driver-*.*.*.jar) иcommons-lang3-3.12.0.jarдля подключения к Prostore.
4.16.1.5. Кластеризация модуля
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.17. Загрузка и удаление данных через ETL
4.17.1. Общее описание
4.17.1.1. Общие положения
Базовый сервис загрузки данных предоставляет возможность асинхронного приёма данных из сторонних источников с целью последующей загрузки их в Витрину данных. Загрузка/обновление данных осуществляется в соответствии с заранее подготовленными Avro-схемами.
Сервис загрузки данных реализуется компонентом ETL, предоставляющей REST API. Доступ к REST API должен осуществляться через Proxy API Datamart Studio. Перед загрузкой необходимо получить токен Proxy API, который в дальнейшем используется для авторизации при операциях, описанных в разделах ниже. При получении ошибки авторизации необходимо повторить авторизацию, получить новый токен и использовать его для дальнейшей загрузки.
Для взаимодействия с REST API (через Proxy API) в продуктивной среде на стороне источника данных требуется использовать сертифицированную версию ОС, а также механизмы, соответствующие требованиям безопасности, установленным для эксплуатации системы (например, через программный продукт Postman).
На стороне источника данных должны соблюдаться следующие требования к механизму взаимодействия:
Запрещается хранение логина и пароля в открытом виде на диске. Логин и пароль должны выгружаться из безопасного хранилища в память ВМ (или контейнера) при старте взаимодействия с Proxy API для дальнейшего использования, сама ВМ должна находиться в закрытом контуре ИС или ведомства.
Рекомендуется реализовать механизм стирания логина и пароля из памяти после успешной аутентификации через Proxy API.
В целях тестирования взаимодействия на тестовой среде может использоваться утилита curl.
4.17.2. Особенности реализации
4.17.2.1. Основные требования к исходным файлам
Загрузка данных в систему производится в виде сообщений, каждое из которых имеет структуру, представленную на Рисунок - 4.9
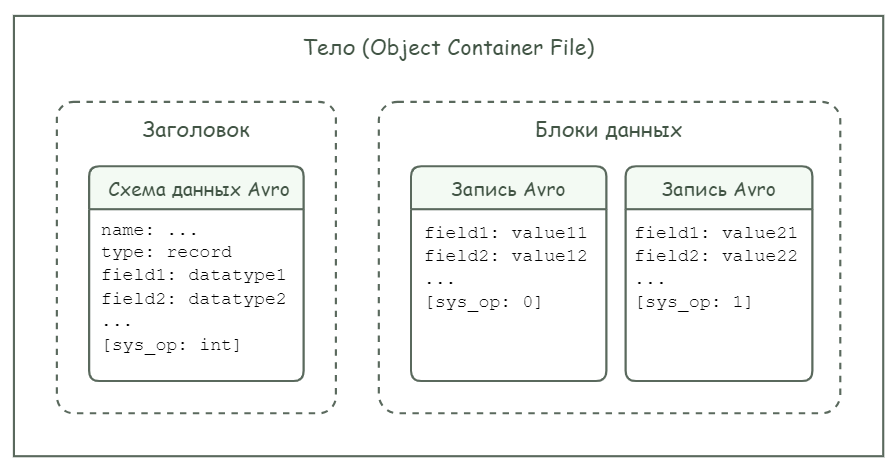
Рисунок - 4.9 Структура загружаемых сообщений
Для успешной загрузки данные должны соответствовать следующим условиям:
Тело сообщения представляет собой файл Avro (Object Container File), который состоит из заголовка и блоков данных.
Заголовок файла содержит схему данных Avro.
Схема данных содержит следующие элементы:
имя;
тип “record”;
перечень полей.
Последним полем схемы должно быть указано служебное поле
sys_opс типом данныхavro.int.Каждый блок данных содержит запись, представленную в бинарной кодировке.
Каждая запись содержит перечень полей и их значений.
Состав и порядок полей должны совпадать во всех следующих объектах:
в схеме данных заголовка файла Avro;
в наборе загружаемых записей;
во внешней таблице загрузки (поле
sys_opдолжно отсутствовать);в таблице-приемнике данных (поле
sys_opдолжно отсутствовать).
Более подробно про формат данных Avro описано в источнике: https://avro.apache.org/docs/1.10.2/spec.html#Object+Container+Files
Примечание
В загружаемой схеме данных Avro и записях Avro важны порядок и тип полей. Имена полей не сравниваются с именами полей внешней таблицы и таблицы-приемника.
Пример ниже содержит схему данных Avro, используемую для загрузки данных о сотрудниках в таблицу staff.
Для поля date_of_birth указан логический тип Avro, для поля middle_name — элемент union (поле является не обязательным
для заполнения, поэтому маркер null выведен в отдельный параметр).
Пример схемы данных Avro:
{
"name": "staff",
"type": "record",
"fields": [
{
"name": "id",
"type": "long"
},
{
"name": "firstname",
"type": "string"
},
{
"name": "lastname",
"type": "string"
},
{
"name": "middle_name",
"type": [
"null",
"string"
]
},
{
"name": "date_of_birth",
"type": {
"logicalType": "timestamp-micros",
"type": "long"
}
},
{
"name": "employee_position",
"type": "string"
},
{
"name": "department_category",
"type": "long"
},
{
"name": "sys_op",
"type": "int"
}
]
}
Пример ниже содержит набор записей о сотрудниках, загружаемых в таблицу staff.
Для наглядности примера бинарные данные представлены в JSON-формате.
[
{
"id": 1000111,
"firstname": "Елена",
"lastname": "Фролова",
"middle_name": "Андреевна",
"date_of_birth": 4641084000000000,
"employee_position": "Менеджер по подбору персонала",
"department_category": 1,
"description": "Сотрудники отдела кадров",
"sys_op": 0
},
{
"id": 1000005,
"firstname": "Пётр",
"lastname": "Платонов",
"middle_name": "",
"date_of_birth": 5639904000000000,
"employee_position": "Руководитель отдела кадров",
"department_category": 1,
"description": "Сотрудники отдела кадров",
"sys_op": 0
}
]
4.17.2.2. Особенности реализации ETL
Функциональные особенности реализованного ETL включают в себя следующие пункты:
Генерация первичных ключей записей, передаваемых для загрузки, производится на стороне источника.
Каждая Avro-структура должна содержать данные только для одной таблицы Витрины.
В Avro-структурах данных источник заполняет тип операции
sys_op:0 – для добавления новой или обновления существующей записи;
1 – для удаления существующей записи (см. пример записей Avro в Раздел 4.17.2.1).
ETL не выполняет преобразования данных, предназначенных для загрузки в Витрину данных.
При выполнении операций, требующих консистентности данных, в рамках одной дельты могут быть только операции одного типа: либо добавления/обновления, либо удаления. При этом в рамках одной дельты первичные ключи всех записей должны быть уникальны.
Не должно быть двух версий одной записи в рамках одной дельты.
Нельзя менять порядок атрибутов в avro-схеме, поскольку данные при загрузке в БД распределяются в соответствии с тем перечнем, который был указан в avro-схеме.
4.17.2.3. Получение токена Рroxy API
Этапы настройки Proxy API включают в себя следующие шаги:
Для начала необходимо пройти авторизацию в Datamart Studio. Сделать это можно, направив запрос ниже:
curl -X POST \
'http://<ip-studio>:8088/api/v1/auth_system' \
-d "username=<username>" \
-d "password=<password>" \
-d "organization_ogrn=<organization_ogrn>" \
-d "datamart_mnemonic=<datamart_mnemonic>"
где:
ip-studio— ip-адрес Datamart Studio;username— имя пользователя IAM;password— пароль пользователя IAM;organization_ogrn— ОГРН организации, в рамках которой развёрнута Витрина данных;datamart_mnemonic— мнемоника Витрины (пример: eduejd##, где ## – номер региона).
Примечание
Безопасность передачи данных по протоколу HTTP обеспечивается защищенной сетью. Требуется обращать внимание на протокол запроса. Если он будет некорректным (например, HTTPS вместо HTTP), то ответ сервера будет содержать ошибку с кодом 500 - InternalServerError.
Пример успешного ответа Datamart Studio на запрос токена представлен ниже:
{
"access_token": "eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICI5NGRuNzhOeVF2TjBhRG3NMcUdkc0tTOTNlTWxjNkRwRjZ5V1NXSUo4In0.eyJleHAiOjE2OTMzMTg0NzIsImlhdCI6MTY5MzMxNDg3MiwianRpIjoiYTJkNTQ5NDktZWYwZC00MzA1LWI5OTAtMDIxMTAyZDkzODU2IiwiaXNzIjoiaHR0cHM6Ly9rYy5kYXRhbWFydC5ydS9yZWFsbXMvc3R1ZGlvLWRldiIsInN1YiI6IjE1NjdkYWI3LTc1OTAtNGM0Zi1iNWNhLWYzMmFkOTU1NThjYyIsInR5cCI6IkJlYXJlciIsImF6cCI6InN0dWRpbyIsInNlc3Npb25fc3RhdGUiOiJlMGE0MjJlZC1hNDQxLTQzY2MtYTAxMS01MzNiY2RiNTc5OGQiLCJhY3IiOiIxIiwicmVhbG1fYWNjZXNzIjp7InJvbGVzIjpbInN1cGVyYWRtaW4iLCJhZG1pbiJdfSwic2NvcGUiOiJvcGVuaWQgZW1haWwiLCJzaWQiOiJlMGE0MjJlZC1hNDQxLTQzY2MtYTAxMS01MzNiY2RiNTc5OGQiLCJ1cG4iOiJhZG1pbiIsImVtYWlsX3ZlcmlmaWVkIjp0cnVlLCJhZGRyZXNzIjp7fSwibmFtZSI6ImFkbWluIGFkbWluIiwiZ3JvdXBzIjpbInN1cGVyYWRtaW4iLCJhZG1pbiJdLCJwcmVmZXJyZWRfdXNlcm5hbWUiOiJhZG1pbiIsImdpdmVuX25hbWUiOiJhZG1pbiIsIm9yZ2FuaXphdGlvbl9vZ3JuIjpbIjExMTIyMjMzMzQ0NCIsIjExMTEiXSwiZmFtaWx5X25hbWUiOiJhZG1pbiIsImVtYWlsIjoiYWRtaW5AYWRtaW4uYWRtaW4ifQ.BC3sREXC3nf2LNvBX8SiHKouVGqJVfUBokVJa-B-9YW0zLhnNTs7mGZVOnC-kM-5mWE6bz8du0lvxQqiGpi3HRlAv1eedcGMTf_2TmjhohAaz--zSCdLC5NSmI79r54XYTLORiWKXj5T_AY8efFwWnWgUJ1LEkd5BTQyGSTvaoJkMv7xextA_isx_WoReHC5_-3GznNtcf_hOd2J1CfMHUFjhqMRSxMkIQDPHnspgU6WUz9IeVA1VWKh1GcggqYDtrruigQcl4_f7XeJQKJ49NNVdhjHtywUVbTpEDKYh4FsgAbf3vIPYUVwGWFW0Qm7LgUCpB8UvMQfb4UYZMF4UA",
"expires_in": 3600,
"refresh_expires_in": 3600,
"refresh_token": "eyJhbGciOiJIUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICJmYmMzOWNmNi1kZTRkLTQ2YWEtYTAwZi1iZGU3ZmFkNTJmNTgifQ.eyJleHAiOjE2OTMzMTg0NzIsImlhdCI6MTY5MzMxNDg3MiwianRpIjoiYWIxN2M0MzQtZGI4Yi00N2QwLTkyM2YtMTFiYmM3NzBiNmE4IiwiaXNzIjoiaHR0cHM6Ly9rYy5kYXRhbWFydC5ydS9yZWFsbXMvc3R1ZGlvLWRldiIsImF1ZCI6Imh0dHBzOi8va2MuZGF0YW1hcnQucnUvcmVhbG1zL3N0dWRpby1kZXYiLCJzdWIiOiIxNTY3ZGFiNy03NTkwLTRjNGYtYjVjYS1mMzJhZDk1NTU4Y2MiLCJ0eXAiOiJSZWZyZXNoIiwiYXpwIjoic3R1ZGlvIiwic2Vzc2lvbl9zdGF0ZSI6ImUwYTQyMmVkLWE0NDEtNDNjYy1hMDExLTUzM2JjZGI1Nzk4ZCIsInNjb3BlIjoib3BlbmlkIGVtYWlsIiwic2lkIjoiZTBhNDIyZWQtYTQ0MS00M2NjLWEwMTEtNTMzYmNkYjU3OThkIn0.SI6Tb6CJ5HIHwzETOyJZ-2nTLibGNq7JEQwW07fY-2M",
"token_type": "Bearer",
"id_token": "eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6ICI5NGRuNzhOeVF2TjBhRGtvX3NMcUdkc0tTOTNlTWxjNkRwRjZ5V1NXSUo4In0.eyJleHAiOjE2OTMzMTg0NzIsImlhdCI6MTY5MzMxNDg3MiwiYXV0aF90aW1lIjowLCJqdGkiOiI5NDM1ZDE3NS00MzE2LTQyN2QtODlkYi1lYTJkOWJlZjJmNWIiLCJpc3MiOiJodHRwczovL2tjLmRhdGFtYXJ0LnJ1L3JlYWxtcy9zdHVkaW8tZGV2IiwiYXVkIjoic3R1ZGlvIiwic3ViIjoiMTU2N2RhYjctNzU5MC00YzRmLWI1Y2EtZjMyYWQ5NTU1OGNjIiwidHlwIjoiSUQiLCJhenAiOiJzdHVkaW8iLCJzZXNzaW9uX3N0YXRlIjoiZTBhNDIyZWQtYTQ0MS00M2NjLWEwMTEtNTMzYmNkYjU3OThkIiwiYXRfaGFzaCI6Ik9UZzZoUFQtWjhhWHR1Yjl1VV91LWciLCJhY3IiOiIxIiwic2lkIjoiZTBhNDIyZWQtYTQ0MS00M2NjLWEwMTEtNTMzYmNkYjU3OThkIiwidXBuIjoiYWRtaW4iLCJlbWFpbF92ZXJpZmllZCI6dHJ1ZSwiYWRkcmVzcyI6e30sIm5hbWUiOiJhZG1pbiBhZG1pbiIsImdyb3VwcyI6WyJzdXBlcmFkbWluIiwiYWRtaW4iXSwicHJlZmVycmVkX3VzZXJuYW1lIjoiYWRtaW4iLCJnaXZlbl9uYW1lIjoiYWRtaW4iLCJvcmdhbml6YXRpb25fb2dybiI6WyIxMTEyMjIzMzM0NDQiLCIxMTExIl0sImZhbWlseV9uYW1lIjoiYWRtaW4iLCJlbWFpbCI6ImFkbWluQGFkbWluLmFkbWluIn0.K372NBffA3xtsxyM3hixr5GF1ouHNdr8DFMBYnGQ-t-REbYcwOymvs-D-HYEsmaUhkCWjKSeLM9taLmAPloSt2hb8xN_VG4s-gc_yvGs_aHkUehTqddjGMislPyAlydzCaDVxQ5Px-TplsDzIAwm5P0V23LDU3qwnVxVR7P3Dbxi5YB84_38zjClNrDWt9YOxnPMCzDT4fnBjGXkDcQZoHo5jsbFP_K5ymugsYEumKIZyekbY_l_A-XkRcTM6SMTRhKLAvQ3lq2YguLm2LFF3e-PrGsaEymeS-Peuff5qJw5Vf9r3_nD3APCivVc0Kunl8miRpr3lsZgSAp-xi3Jow",
"not-before-policy": 0,
"session_state": "e0a422ed-a441-43cc-a011-533bcdb5798d",
"scope": "openidemail"
}
С полученным токеном послать запрос для подключения к API инсталляции приложения типового ПО Витрины данных для выбранной организации:
curl -X <method>
'http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/<request_path>' \
-H "Authorization: Bearer <access_token>" \
-H "<headers>" \
-d "<data>"
где:
ip-studio— ip-адрес Datamart Studio;organization_ogrn— ОГРН организации, в рамках которой развёрнута Витрина данных;datamart_mnemonic— мнемоника Витрины (пример: eduejd##, где ## – номер региона);installation_name— имя инсталляции в целевой Витрине;installation_id— идентификатор инсталляции (присутствует в её названии);request_path— URI оригинального API инсталляции;access_token— токен Proxy API;headers— заголовки запроса;data— данные запроса.
4.17.3. Загрузка / удаление данных
4.17.3.1. Загрузка/ удаление данных
Сначала источник данных формирует и передаёт файлы по REST API, которые накапливаются Компонентом ETL.
Далее данные загружаются и вставляются в Витрину данных через внешние таблицы, или удаляются. Статусы обработки каждой операции
необходимо отслеживать через Endpoint /status.
Информация о каждом шаге процесса содержится в подразделах ниже.
4.17.3.1.1. Начало операции загрузки / удаления согласованных данных (Endpoint – newDelta)
Под Endpoint’ом /newDelta регистрируется новая порция данных. Для того чтобы начать работу с данными, источнику данных
необходимо сгенерировать UUID (идентификатор для новой порции данных) и вставить его в запрос c Endpoint’ом /newDelta.
Согласованные данные – это данные для нескольких таблиц, которые должны попасть в Витрину данных за одну операцию вставки (то есть в одной дельте), а значит будут доступны для потребителя одномоментно (такой способ загрузки актуален, когда необходимо обновить данные).
Пример набора данных, который будет загружен или удален в рамках одной дельты представлен ниже:
{
"requestId": "6B29FC40-CA47-1067-B31D-00DD010662DA",
"dataSetName": ["product", "stock"]
}
где:
requestId— идентификатор порции изменений (дельты);dataSetName— массив имен набора данных (product и stock - имена таблиц).
Запрос с Endpoint’ом /newDelta будет иметь вид:
curl -X POST "http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/newDelta" -H "Authorization: Bearer <access_token>" -H 'Content-Type: application/json' -d '{"requestId": "6B29FC40-CA47-1067-B31D-00DD010662DA", "dataSetName": ["product", "stock"]}'
где:
requestId— идентификатор порции изменений (дельты), который был ранее сгенерирован;dataSetName— имя набора данных (имена таблиц).
Примечание
Данные для обновления/вставки и для удаления должны быть отдельно зарегистрированы в newDelta с разными requestId. Если требуется обновить/вставить данные, то сначала нужно зарегистрировать порцию данных через newDelta с requestId, затем прислать данные с зарегистрированным requestId через endpoint /partOfDelta (описан в Раздел 4.17.3.1.2). Допускается передача как в одном файле одним запросом, так и в двух файлах двумя запросами - это не имеет значения. Главное условие - нужно отправлять только данные на обновление и вставку, и они должны быть уникальны по первичному ключу. Также в них не должно быть одинаковых записей с одним первичным ключом. Пример: отправлены два обновления одной записи (с одинаковым первичным ключом). В этом случае в хранилище Prostore попадет только одна запись, и неизвестно какая, поэтому дублей по первичному ключу отправленных с одним requestId быть не должно!
Чтобы проверить статус выполнения запроса, необходимо направить запрос с Endpoint’ом /status
(пример запроса описан в Раздел 5.18.1)
Если обработка запроса завершится успешно, то Витрина данных вернёт JSON-ответ, содержащий статус-сообщение об успешной операции:
{
"requestId": "6B29FC40-CA47-1067-B31D-00DD010662DA",
"dataSets": [
"product",
"stock"
],
"inDeltaFlag": true,
"statusCode": "SUCCESS",
"statusMessage": "Загрузка порции данных успешно завершена"
"errors": []
}
где:
requestId— идентификатор порции изменений (дельты);statusCode— код возвращаемого статуса (SUCCESS – запрос выполнен успешно).
Пример JSON-ответа на проверку статуса, завершившегося ошибкой, приведен ниже:
{
"requestId": "6B29FC40-CA47-1067-B31D-00DD010662DA",
"statusCode": "REQUESTID_ALREADY_EXIST",
"statusMessage": "Дельта с requestId = 6B29FC40-CA47-1067-B31D-00DD010662DA уже существует. Статус загрузки дельты: SUCCESS"
}
где:
requestId— идентификатор порции изменений (дельты) который необходимо проверить;statusCode— код возвращаемого статуса (REQUESTID_ALREADY_EXIST – идентификатор уже существует в БД);statusMessage— сообщение с описанием кода ошибки.
Примечание
Для удаления записей необходимо зарегистрировать новую дельту во Endpoint’е /newDelta с новым requestId, и по зарегистрированному requestId должны быть присланы только данные на удаление.
4.17.3.1.2. Загрузка / удаление согласованных данных (Endpoint – partOfDelta)
На данном шаге выполняется накапливание порции данных, создаётся вставка в Витрину данных по Endpoint’у isLastChunk.
Примечание
Если в процессе загрузки вызван метод newDelta, то текущая загрузка будет прервана и порция не попадет в Витрину данных.
Чтобы отправить последнюю порцию данных для таблицы product, необходимо направить запрос с Endpoint’ом /partOfDelta с указанием
dataSetName=product и isLastChunk=true (что означает что данная порция данных - последняя). Обработка и загрузка данных
не начнётся, пока не будет направлен такой же запрос, но уже по таблице stock: dataSetName=stock, isLastChunk=true.
Пример запроса на загрузку данных под ранее созданный набор данных:
curl -X POST "http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/partOfDelta" -H "Authorization: Bearer <access_token>" -F upload=@"./product.avro" -F dataSetName=product -F chunkNumber=0 -F isLastChunk=false -F requestId=a6212a7d-4526-4e2d-89a7-9828f380c91d
где:
upload— загружаемый avro-файл (пример avro-файла с данными представлен в разделе 2);dataSetName— имя набора данных (имя таблицы);chunkNumber— номер порции dataSet в рамках дельты;isLastChunk— флаг последней порции dataSet;requestId— идентификатор порции изменений (дельты).
В результате успешной загрузки при проверке статуса requestId (пример запроса по Endpoint’у /status представлен в Раздел 5.18.1)
на запрос Витрина данных вернёт JSON-ответ, содержащий статус-сообщение об успешной операции.
Пример успешной загрузки:
{
"requestId": "f3947645-88c8-4044-bd8b-de273f8a8461",
"statusCode": "SUCCESS",
"statusMessage": "Порция получена."
}
где:
requestId— идентификатор порции изменений (дельты);statusCode— статус код результата запроса (SUCCESS - запрос выполнен успешно);statusMessage— описание статусного сообщения.
Если загрузка прервалась ошибкой, то при проверке статуса requestId (пример запроса по Endpoint’у /status
представлен в Раздел 5.18.1) на запрос Витрина данных вернёт JSON-ответ с описанием ошибки.
Пример загрузки, прерванной ошибкой:
{
"requestId": "aef2f195-b037-4aaa-b171-f2746511e7e2",
"dataSets": [
"stock"
],
"inDeltaFlag": true,
"statusCode": "ERROR",
"statusMessage": "Произошла ошибка"
"errors": [
{
"dataSet": "stock",
"errorType": "INSERT",
"message": "Ошибка вставки в таблицы: stock"
}
]
}
где:
requestId— идентификатор порции изменений (дельты);dataSets— массив имен набора данных (имен таблиц где была допущена ошибка);inDeltaFlag= true — загрузка согласованных данных производилась через endpoint /partOfDetla;status— статус код результата запроса (ERROR – внутренняя ошибка);statusMessage— описание статусного сообщения;errors— массив, ошибки загрузки или парсинга входящих данных;dataSet— название таблицы где допущена ошибка;errorType— тип ошибки;message— описание ошибки.
Примечание
Возможна ситуация, когда после падения ETL приходит запрос с requestId, который был до падения, в данном случае
Витрина данных возвращает ошибку со статусом NOT_FOUND. Необходимо снова направить запрос по Endpoint’у /newDelta с
новым requestId и начать процесс загрузки заново.
4.17.3.1.3. Загрузка / удаление несогласованных данных (Endpoint – data)
Для загрузки несогласованных данных поддерживается возможность накапливания данных, аналогично загрузке согласованных данных, описанной в Раздел 4.17.3.1.2.
Несогласованные данные – могут быть вставлены в разных дельтах и будут доступны потребителю постепенно по мере загрузки. Этот способ подходит для первоначальной загрузки, когда еще нет потребителей.
Вставка в Витрину данных выполнится после накопления порции или по флагу isLast, который используется для последней порции
данных. Флаг isLast подаёт сигнал для завершения формирования дельты, для того чтобы выполнить вставку накопленных данных и
закрыть транзакцию.
Пример запроса:
curl -X POST "http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/data" -H "Authorization: Bearer <access_token>" -F upload=@"./product.avro" -F dataSetName=product -F isLast=false -F requestId=a6212a7d-4526-4e2d-89a7-9828f380c91d
где:
upload— загружаемый avro-файл (пример avro-файла с данными представлен в Раздел 4.17.2.1);dataSetName— имя набора данных (имя таблицы);isLast— флаг последней порции данных (сигнал для завершения формирования дельты, для того чтобы выполнить вставку накопленных данных и закрыть транзакцию.);requestId— идентификатор порции изменений (дельты).
В результате успешной операции при проверке статуса запроса по Endpoint’у /status (пример запроса описан в Раздел 5.18.1)
Витрина данных вернёт JSON-ответ, содержащий статус-сообщение:
{
"requestId": "6B29FC40-CA47-1067-B31D-00DD010662DA",
"statusCode": "SUCCESS",
"statusMessage": "Порция получена."
}
где:
requestId— идентификатор порции изменений (дельты);statusCode— статус код результата запроса (SUCCESS - запрос выполнен успешно);statusMessage— описание статусного сообщения.
Если загрузка прервалась ошибкой, то при проверке requestId (пример запроса по Endpoint’у /status представлен
в Раздел 5.18.1) Витрина данных вернёт JSON-ответ с описанием ошибки.
Пример JSON-ответа:
{
"requestId": "6B29FC40-CA47-1067-B31D-00DD010662DA",
"statusCode": "NOT_FOUND",
"statusMessage": "Не найдена дельта с requestId = 6B29FC40-CA47-1067-B31D-00DD010662DA"
}
где:
requestId— идентификатор порции изменений (дельты);statusCode— статус код результата запроса (NOT_FOUND - данные по requestId были утеряны в результате остановки сервиса, необходимо зарегистрировать новую дельту и снова загрузить данные);statusMessage— описание статусного сообщения.
4.17.3.1.4. Описание возвращаемых кодов
Наименование |
Код |
Описание |
|---|---|---|
EMPTY_ATTACHMENT |
400 |
Нет файла вложения |
ERROR |
500 |
Внутренняя ошибка |
NOT_FOUND |
400 |
Данные не найдены, либо были утеряны в результате остановки сервиса |
PROCESSING |
400 |
Идет обработка данных |
REQUESTID_ALREADY_EXIST |
400 |
|
SUCCESS |
200 |
Успешное выполнение |
UNREGISTERED_DATASETNAME |
400 |
Незарегистрированный набор данных |
WRONG_ENDPOINT |
400 |
|
4.17.4. Проверка статусной информации по загрузке
4.17.5. Проверка статусной информации по загрузке / удалению данных (Endpoint – status)
В данном разделе производится проверка статусной информации из сервисных таблиц по requestId.
Пример запроса:
Curl -X GET "http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/status/<requestId>" -H "Authorization: Bearer <access_token>"
где:
requestId— UUID идентификатор порции изменений (дельты).
Пример ответа на такой запрос представлен ниже.
{
"requestId": "13f2475e-f3dc-4c9e-b2f6-3a98320261f1",
"inDeltaFlag": false,
"dataSets": [
"stock"
],
"status": "ERROR",
"statusMessage": "Произошла ошибка",
"errors": [
{
"dataSet": "stock",
"errorType": "PARCING",
"message": "Неверно указан тип поля count_pieces: LONG. Ожидается: INTEGER"
},
{
"dataSet": "stock",
"errorType": "PARCING",
"message": "Неверно указан тип поля product_id: LONG. Ожидается: INTEGER"
}
]
}
где:
requestId— UUID идентификатор порции изменений (дельты);inDeltaFlag = false— загрузка несогласованных данных производилась через endpoint /data;dataSets— массив имен набора данных (имен таблиц где была допущена ошибка);status— статус код результата запроса (NOT_FOUND, PROCESSING, ERROR, SUCCESS);statusMessage— описание статусного сообщения;errors— массив, ошибки загрузки или парсинга входящих данных;dataSet— название таблицы где допущена ошибка;errorType— тип ошибки;message— описание ошибки.
4.17.6. Работа с вложениями через S3
4.17.6.1. Работа с вложениями через S3
4.17.6.1.1. Загрузка данных в хранилище (Endpoint – uploadAttachment)
Перед загрузкой источнику данных необходимо сгенерировать UUID (идентификатор для новой порции данных) и вставить его в запрос с
Endpoint’ом /uploadAttachment. При совпадении имен вложений в хранилище, вложение перезаписывается. Пример запроса на загрузку
вложения в хранилище представлен ниже:
curl -X POST "http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/uploadAttachment" -H "Authorization: Bearer <access_token>" -F upload=@"document.pdf" -F requestId=13f2475e-f3dc-4c9e-b2f6-3a98320261f1 -F name=Doc_1
где:
upload— путь до загружаемого файла-вложения;requestId— UUID идентификатор запроса;name— уникальное имя вложения.
После успешной загрузки при проверке по Endpoint’у /status (пример запроса описан в Раздел 5.18.1) Витрина данных
вернёт JSON-ответ, содержащий статус-сообщение:
{
"requestId": "13f2475e-f3dc-4c9e-b2f6-3a98320261f1",
"statusCode": "UPDATED",
"statusMessage": "Файл Doc_1 успешно обновлен."
}
где:
requestId— UUID идентификатор запроса;statusCode— статус код результата запроса (SUCCESS - запрос выполнен успешно; UPDATED – данные обновлены);statusMessage— описание статусного сообщения.
Пример неуспешной загрузки после проверки по endpoint’у /status (пример запроса описан в Раздел 5.18.1) представлен ниже:
{
"requestId": "13f2475e-f3dc-4c9e-b2f6-3a98320261f1",
"statusCode": "ERROR",
"statusMessage": "Произошла ошибка"
}
где:
requestId— UUID идентификатор запроса;statusCode— статус код результата запроса (ERROR – запрос завершился ошибкой);statusMessage— описание статусного сообщения.
4.17.6.1.2. Удаление данных из хранилища (Endpoint – deleteAttachment)
Для того чтобы удалить вложения из хранилища S3 необходимо направить следующий запрос:
curl -X DELETE "http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/deleteAttachment/Doc_1/requestId/<requestId>" -H "Authorization: Bearer <access_token>"
где:
requestId— UUID идентификатор запроса.
В результате успешного удаления Витрина данных вернёт JSON-ответ, содержащий статус-сообщение:
{
"requestId": "13f2475e-f3dc-4c9e-b2f6-3a98320261f1",
"statusCode": "SUCCESS",
"statusMessage": "Файл Doc_1 успешно удален."
}
где:
requestId— UUID идентификатор запроса;statusCode— статус код результата запроса (SUCCESS - запрос выполнен успешно);statusMessage— описание статусного сообщения.
Если удаление завершилось ошибкой, то Витрина данных вернёт JSON-ответ c кодом ошибки:
{
"requestId": "13f2475e-f3dc-4c9e-b2f6-3a98320261f1",
"statusCode": "NOT_FOUND",
"statusMessage": "Файл Doc_1 не найден."
}
где:
requestId— UUID идентификатор запроса;statusCode— статус код результата запроса (NOT_FOUND);statusMessage— описание статусного сообщения.
4.17.6.1.3. Описание возвращаемых кодов
Наименование |
Код |
Описание |
|---|---|---|
EMPTY_ATTACHMENT |
400 |
нет файла вложения |
ERROR |
500 |
Внутренняя ошибка |
SUCCESS |
200 |
Успешное выполнение |
UPDATED |
200 |
данные обновлены |
4.17.7. Маппинг данных
4.17.7.1. Маппинг данных (Endpoint – generateMapping)
В данном разделе описывается генерация файла маппинга. Endpoint предназначен для первичной настройки, а также перенастройки сервиса в случае изменения модели данных Витрины.
Файл маппинга генерируется источником данных в формате Kotlin-script. В файле описана модель данных Витрины данных в виде
структуры объектов Kotlin (table, column). Объекты table описывают таблицы, каждый из них содержит имя таблицы и
список колонок в том порядке, в котором они созданы в Витрине. Объекты column описывают колонки, каждый из них содержит имя
колонки, тип данных, признак обязательности (nullable), признак первичного ключа.
Файл используется сервисом для описания модели данных и валидации входящих данных. Выполняются следующие проверки:
проверяется соответствие состава полей входящей avro-структуры составу полей, описанных в файле маппинга;
проверяется соответствие порядка полей входящей avro-структуры порядку полей, описанных в файле маппинга;
проверяется соответствие типов данных полей входящей avro-структуры типам полей, описанных в файле маппинга. Для полей с установленным признаком обязательности (nullable = false) выполняется проверка на null.
При вызове Endpoint’а /generateMapping сервис генерирует файл на основе информации о модели, полученной из развернутой Витрины
данных. Файл складывается сервисом на диск, а также возвращается в ответе на вызов.
Пример запроса на генерацию маппинга представлен ниже:
curl -X GET "http://<ip-studio>:8088/api/v1/secure/<organization_ogrn>/<datamart_mnemonic>/<installation_name>/<installation_id>/generateMapping/aef2f195-0001-4aaa-b171-f2746511e889" -H "Authorization: Bearer <access_token>"
Результат Витрина данных вернёт в формате Kotlin-script:
import ru.supercode.mapping.common.ColumnType.*
import ru.supercode.mapping.mapper.dsl.mappingAvro
mappingAvro {
table("product") {
column("id", INTEGER) { nullable = false; primary = true; }
column("name", STRING) { nullable = false; }
}
table("stock") {
column("product_id", INTEGER) { nullable = false; primary = true; }
column("count_pieces", INTEGER) { nullable = false; }
}
}
4.17.8. Валидация данных
4.17.8.1. Валидация данных
Валидация порции данных производится в момент обработки и вставки.
Примечание
Помимо валидации данных осуществляется валидация параметров запроса. Во всех Endpoint’ах requestId должен быть в формате UUID.
В случае ошибок при валидации результат будет возвращен при вызове Endpoint’а /status.
Ошибки, возникающие в процессе обработки Endpoint’а /newDelta:
отклоняются запросы, которые получены в момент обработки порции данных (
statusCode: PROCESSED);если пустой параметр
dataSetName;прислан запрос с уже зарегистрированным
requestIdиstatusCodeданногоrequestIdне равенNOT_FOUNDилиWAIT_DATA.
Ошибки, возникающие в процессе обработки Endpoint’а /partOfDelta:
прислан запрос с незарегистрированным
requestId;прислан запрос с уже зарегистрированным
requestIdиstatusCodeданногоrequestIdне равенNOT_FOUNDилиWAIT_DATA;прислан запрос с
requestIdзарегистрированным для Endpoint’а/data;прислан запрос с параметром
dataSetName, который не был зарегистрирован в Endpoint’е/newDelta;нет файла вложения в параметре
upload.
Ошибки, возникающие в процессе обработки Endpoint’а /data:
отклоняются запросы, которые получены в момент обработки порции данных (
statusCode: PROCESSED);прислан запрос с незарегистрированным
requestId;прислан запрос с уже зарегистрированным
requestIdиstatusCodeданногоrequestIdне равенNOT_FOUNDилиWAIT_DATA;прислан запрос с
requestIdзарегистрированным для Endpoint’а/partOfDelta;нет файла вложения в параметре
upload.
Ошибки, возникающие в процессе обработки Endpoint’а /uploadAttachment:
нет файла вложения в параметре
upload.
Ошибки, возникающие в процессе обработки Endpoint’а /generateMapping:
не созданы логические таблицы в схеме.
4.18. Установка Apache Airflow
4.18.1. Подготовка конфигурации
Клонировать репозиторий Apache Airflow из официального репозитория
git clone https://github.com/apache/airflow.git
Перейти в папку airflow
Создать в папке файл
Dockerfile.customсо следующим содержимым
FROM ${BASE_AIRFLOW_IMAGE}
SHELL ["/bin/bash", "-o", "pipefail", "-e", "-u", "-x", "-c"]
USER 0
# Install Java
RUN mkdir -pv /usr/share/man/man1 \\
&& mkdir -pv /usr/share/man/man7 \\
&& curl -fsSL
https://adoptopenjdk.jfrog.io/adoptopenjdk/api/gpg/key/public \|
apt-key add - \\
&& echo 'deb https://adoptopenjdk.jfrog.io/adoptopenjdk/deb/ buster
main' > \\
/etc/apt/sources.list.d/adoptopenjdk.list \\
&& apt-get update \\
&& apt-get install --no-install-recommends -y \\
adoptopenjdk-8-hotspot-jre \\
&& apt-get autoremove -yqq --purge \\
&& apt-get clean \\
&& rm -rf /var/lib/apt/lists/\*
# Установка JDR 1.8
ENV JAVA_HOME=/usr/lib/jvm/adoptopenjdk-8-hotspot-jre-amd64
USER ${AIRFLOW_UID}
# Установка компонента apache.spark
RUN pip install --upgrade pip \\
&& pip install --no-cache-dir --user 'apache-airflow[apache.spark]'
4.18.2. Установка Apache Airflow
Установка Apache Airflow выполняется с помощью Docker. Установка Docker описана в разделе Установка Arenadata Cluster Manager (ADCM).
Создайте новый образ в Docker, в той же директории, где расположен файл
Dockerfile.custom:
docker build . \\
--build-arg BASE_AIRFLOW_IMAGE="apache/airflow:2.0.1-python3.8" \\
-f Dockerfile.java8 \\
-t airflow:2.0.1-python3.8-custom
Скачать файл
docker-compose.yamlс официального сайта Airflow https://Airflow.apache.org/docs/apache-airflow/2.0.1/docker-compose.yamlУстановить
docker-compose.yamlчерез SSH-консоль технологического пользователя.
Выдать права на исполнение файла
sudo chmod +x /usr/local/bin/docker-compose
Запустить sudo
ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
Проверить корректность установки
$ docker-compose --version
docker-compose version 1.28.6, build 1110ad01
Перейти в директорию с файлом
docker-compose.yml:
cd ~/direct
Инициализировать компоненты
docker-compose up airflow-init
Запустить сервисы с новым образом
docker-compose up
AIRFLOW_IMAGE_NAME=apache/airflow:2.0.1-python3.8-custom
4.19. Установка Apache Spark
Установка Docker описана в разделе Установка Arenadata Cluster Manager (ADCM).
4.19.1. Подготовка конфигурации
Клонировать репозиторий Apache Airflow из официального репозитория:
git clone https://github.com/big-data-europe/docker-spark.git
Перейти в директорию
docker-spark:
cd ~/direct
Выполнить скрипт
./build.shили вручную последовательно запустить следующие команды
сборка базового образа
docker build -t bde2020/spark-base:3.1.1-hadoop3.2
сборка образа мастер
docker build -t bde2020/spark-master:3.1.1-hadoop3.2
сборка образа воркера
docker build -t bde2020/spark-worker:3.1.1-hadoop3.2
Проверить наличие собранных образов, выполнив команду docker:
REPOSITORY TAG IMAGE ID CREATED SIZE
bde2020/spark-worker 3.1.1-hadoop3.2 05c349b4646f 4 minutes ago 460MB
bde2020/spark-master 3.1.1-hadoop3.2 7918c5357d6d 4 minutes ago 460MB
bde2020/spark-base 3.1.1-hadoop3.2 5430434220d2 4 minutes ago 460MB
4.19.2. Установка
Перейти в директорию docker-spark, где располагается файл
docker-compose.yml:
cd ~/direct
Запустить Apache Spark командой:
docker-compose up
Проверить командой:
docker ps
В списке запущенных образов должны присутствовать spark-worker и spark-master.
4.20. Установка Apache Hadoop
Установка Docker описана в разделе Установка Arenadata Cluster Manager (ADCM).
4.20.1. Подготовка конфигурации
Клонировать репозиторий Apache Hadoop из официального репозитория
git clone https://github.com/big-data-europe/docker-hadoop.git
Перейти в папку docker-hadoop
cd ~/direct
Выполнить скрипт
make buildили вручную последовательно запустить следующие команды:
сборка базового образа
docker build -t bde2020/hadoop-base:master ./base
сборка остальных образов
docker build -t bde2020/hadoop-namenode:master ./namenode
docker build -t bde2020/hadoop-datanode:master ./datanode
docker build -t bde2020/hadoop-resourcemanager:master
./resourcemanager
docker build -t bde2020/hadoop-nodemanager:master ./nodemanager
docker build -t bde2020/hadoop-historyserver:master
./historyserver
docker build -t bde2020/hadoop-submit:master ./submit
Проверить наличие собранных образов:
Выполнить команду docker:
REPOSITORY TAG IMAGE ID CREATED SIZE
bde2020/hadoop-submit master 665a424edc23 9 minutes ago 1.37GB
bde2020/hadoop-historyserver master ff53bf6835e2 9 minutes ago 1.37GB
bde2020/hadoop-nodemanager master c48c47bc840f 9 minutes ago 1.37GB
bde2020/hadoop-resourcemanager master 74fc55d664d2 9 minutes ago 1.37GB
bde2020/hadoop-datanode master f69c6460a292 9 minutes ago 1.37GB
bde2020/hadoop-namenode master 7a8250da8510 9 minutes ago 1.37GB
bde2020/hadoop-base master aeb6500ab4b5 10 minutes ago 1.37GB
4.20.2. Процесс установки
Перейти в директорию docker-hadoop, где располагается файл
docker-compose.yml
cd ~/direct
Поднять Apache Hadoop командой
docker-compose up
Проверить командой
docker ps
В списке запущенных образов должны присутствовать hadoop-resourcemanager, hadoop-historyserver, hadoop-datanode,
hadoop-nodemanager, hadoop-namenode.
4.21. Установка Tarantool (Vinyl)
Установка Docker описана в разделе «Установка Arenadata Cluster Manager (ADCM).
4.21.1. Подготовка конфигурации
Клонировать репозиторий Tarantool из официального репозитория
git clone https://github.com/tarantool/docker.git
Выполнить сборку согласно инструкции: https://github.com/tarantool/docker#how-to-push-an-image-for-maintainers
Перейти в клонированную директорию docker
cd ~/direct
Выполнить сборку образа docker для Tarantool
export TAG=2
export OS=alpine DIST=3.9 VER=2.8.0
PORT=5200 make -f .gitlab.mk build
Проверить наличие собранных образов командой docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tarantool/tarantool 2 27f80564ecce 2 minutes ago 298MB
Создать в клонированной директории docker файл
docker-compose.ymlсо следующим содержимым:
version: "3"
services:
tarantool1:
image: tarantool/tarantool:2
container_name: tarantool1
restart: always
networks:
- tarantool_network
ports:
- "3301:3301"
volumes:
- tarantool1_volume:/opt/tarantool
environment:
# https://github.com/tarantool/docker#environment-variables
TARANTOOL_REPLICATION: "tarantool1,tarantool2"
tarantool2:
image: tarantool/tarantool:2
container_name: tarantool2
restart: always
networks:
- tarantool_network
ports:
- "3302:3301"
volumes:
- tarantool2_volume:/opt/tarantool
environment:
TARANTOOL_REPLICATION: "tarantool1,tarantool2"
volumes:
tarantool1_volume:
tarantool2_volume:
networks:
tarantool_network:
driver: bridge
4.21.2. Процесс установки
Перейти в директорию docker, где располагается файл
docker-compose.yml
cd ~/direct
Пример запуска мастер-мастер репликации:
https://github.com/tarantool/docker#start-a-master-master-replica-set
Поднять Tarantool командой
docker-compose up
Проверить командой
docker ps
В списке запущенных образов должны присутствовать tarantool1 и tarantool2.
4.22. Установка CSV-Uploader
Описание настроек модуля приведено в «Руководстве администратора».
4.22.1. Процесс установки CSV-uploader
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.22.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в разделе
Конфигурация CSV-uploader (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.22.1.2. Загрузка JAR-файла на сервер
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.23. Установка REST-адаптера
Установка сервисов и необходимых сервисных баз данных.
Внимание
Установка данных сервисов выполняется после выполнения действий, описанных в разделе Предварительные действия.
Действия по установке выполняются на сервере ADCM через SSH-консоль технологического пользователя.
4.23.1. Установка docker-образов
Установка Docker описана в разделе Установка Arenadata Cluster Manager (ADCM).
Далее необходимо установить образ REST-адаптера, при этом файл образа .tar должен быть загружен через Docker из
дистрибутива программы.
Пример команды для установки:
docker image load -i <image_file>
4.23.2. Подготовка конфигурации
Для подготовки скриптов необходимо выполнить следующие действия:
Отредактировать переменные в файле
application.ymlдля рабочей среды. Отредактированный файл необходимо поместить в директориюconfig:
указать корректный путь до целевой БД. Переменная
jdbc_url.
Например:
jdbc:{drv_name}://{IP_Host}:{Port}/{db_name}
, где:
drv_name- имя драйвера , берется из описания драйвера базыIP_Host- ip или имя хоста с базой;Port- порт, на котором будет слушать сервис . По умолчанию 8080;db_name- имя базы данных.указать
driver-class-name- имя класса , берется из описания драйвера базы;указать переменную
file_path- наименование файла с описанием запросов, по умолчаниюsample.yaml;Указать переменные
execquery- сопоставление operationId из файла с описанием запросов c файлом обработчиком, по умолчаниюsample.peb.
4.23.3. Процесс установки
Для установки необходимо выполнить следующие действия:
Перейти в директорию с файлом
docker-compose.yml:
cd ~/direct
Поднять сервис конечных точек командой:
docker-compose up -d
Проверить установку следующей командой:
docker ps
В списке запущенных образов должен присутствовать rest-adapter.
4.24. Установка Counter-provider
Описание настроек модуля приведено в «Руководстве администратора».
4.24.1. Процесс установки
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
4.24.1.1. Настройка конфигурации
Настройка конфигурации выполняется путем редактирования параметров файла конфигурации application.yml.
Пример файла application.yml и возможные настройки конфигурации модуля см. в
разделе Конфигурация модуля Counter-Provider (application.yml) Руководства администратора ПО «Витрина данных НСУД».
4.24.1.2. Загрузка JAR-файла на сервер
Для загрузки файла на сервер выполните команду
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.25. Установка коннектора Kafka-Postgres
Из полученного дистрибутива ПО скопировать и загрузить в папку kafka-postgres-connector файлы:
kafka-postgres-writer-0.3.0.jar,kafka-postgres-reader-0.3.0.jar,kafka-postgres-avro-0.3.0.jar.
Скопировать конфигурационные файлы KAFKA-POSTGRES-WRITER
application.yamlи KAFKA-POSTGRES-READERapplication.yamlв папку kafka-postgres-connector/config.
Конфигурационный файл KAFKA-POSTGRES-WRITER application.yaml:
logging:
level:
ru.datamart.kafka: ${LOG_LEVEL:DEBUG}
org.apache.kafka: ${KAFKA_LOG_LEVEL:INFO}
http:
port: ${SERVER_PORT:8096}
vertx:
pools:
eventLoopPoolSize: ${VERTX_EVENT_LOOP_SIZE:12}
workersPoolSize: ${VERTX_WORKERS_POOL_SIZE:32}
verticle:
query:
instances: ${QUERY_VERTICLE_INSTANCES:12}
insert:
poolSize: ${INSERT_WORKER_POOL_SIZE:32}
insertPeriodMs: ${INSERT_PERIOD_MS:1000}
batchSize: ${INSERT_BATCH_SIZE:500}
consumer:
poolSize: ${KAFKA_CONSUMER_WORKER_POOL_SIZE:32}
maxFetchSize: ${KAFKA_CONSUMER_MAX_FETCH_SIZE:10000}
commit:
poolSize: ${KAFKA_COMMIT_WORKER_POOL_SIZE:1}
commitPeriodMs: ${KAFKA_COMMIT_WORKER_COMMIT_PERIOD_MS:1000}
client:
kafka:
consumer:
checkingTimeoutMs: ${KAFKA_CHECKING_TIMEOUT_MS:10000}
responseTimeoutMs: ${KAFKA_RESPONSE_TIMEOUT_MS:10000}
consumerSize: ${KAFKA_CONSUMER_SIZE:10}
closeConsumersTimeout: ${KAFKA_CLOSE_CONSUMER_TIMEOUT:15000}
property:
bootstrap.servers: ${KAFKA_BOOTSTRAP_SERVERS:kafka.host:9092}
group.id: ${KAFKA_CONSUMER_GROUP_ID:postgres-query-execution}
auto.offset.reset: ${KAFKA_AUTO_OFFSET_RESET:earliest}
enable.auto.commit: ${KAFKA_AUTO_COMMIT:false}
auto.commit.interval.ms: ${KAFKA_AUTO_INTERVAL_MS:1000}
datasource:
postgres:
database: ${POSTGRES_DB_NAME:test}
user: ${POSTGRES_USERNAME:dtm}
password: ${POSTGRES_PASS:dtm}
hosts: ${POSTGRES_HOSTS:localhost:5432}
poolSize: ${POSTGRES_POOLSIZE:10}
preparedStatementsCacheMaxSize: ${POSTGRES_CACHE_MAX_SIZE:256}
preparedStatementsCacheSqlLimit: ${POSTGRES_CACHE_SQL_LIMIT:2048}
preparedStatementsCache: ${POSTGRES_CACHE:true}
Конфигурационный файл KAFKA-POSTGRES-READER application.yaml:
logging:
level:
ru.datamart.kafka: ${LOG_LEVEL:DEBUG}
org.apache.kafka: ${KAFKA_LOG_LEVEL:INFO}
http:
port: ${SERVER_PORT:8094}
vertx:
pools:
eventLoopPoolSize: ${VERTX_EVENT_LOOP_SIZE:12}
workersPoolSize: ${VERTX_WORKERS_POOL_SIZE:32}
verticle:
query:
instances: ${QUERY_VERTICLE_INSTANCES:12}
datasource:
postgres:
database: ${POSTGRES_DB_NAME:test}
user: ${POSTGRES_USERNAME:dtm}
password: ${POSTGRES_PASS:dtm}
hosts: ${POSTGRES_HOSTS:localhost:5432}
poolSize: ${POSTGRES_POOLSIZE:10}
preparedStatementsCacheMaxSize: ${POSTGRES_CACHE_MAX_SIZE:256}
preparedStatementsCacheSqlLimit: ${POSTGRES_CACHE_SQL_LIMIT:2048}
preparedStatementsCache: ${POSTGRES_CACHE:true}
fetchSize: ${POSTGRES_FETCH_SIZE:1000}
kafka:
client:
property:
key.serializer: org.apache.kafka.common.serialization.ByteArraySerializer
value.serializer: org.apache.kafka.common.serialization.ByteArraySerializer
4.26. Установка Arenadata Cluster Manager (ADCM)
Внимание
При условии установки CentOS 7.9
ADCM – сервер, с которого будет централизованно производиться установка почти всех компонентов программы. Данный компонент обязателен для установки.
ADCM поставляется в docker-контейнерах, поэтому чтобы установить ADCM на сервере должен быть установлен Docker или совместимое программное обеспечение для работы с контейнерами. Текущая версия программного обеспечения несовместима с SELinux.
Подробная инструкция по установке ADCM приведена в официальной документации разработчика: https://docs.arenadata.io/adcm/user/install.html.
Установка ADCM осуществляется пользователем согласно следующим этапам:
Выключить
selinux. Для этого в файле/etc/selinux/configустановите значениеSELINUX=disabledи перезапустить сервер командойreboot now.Установите Docker для этого используйте следующие команды
yum-config-manager --add-repo
https://download.docker.com/linux/centos/docker-ce.repo
yum install -y containerd.io
yum install -y docker-ce-3:18.09.1-3.el7
systemctl enable docker
systemctl start docker
Установить ADCM в Docker. Для этого используйте следующие команды
docker pull arenadata/adcm:latest
docker create --name adcm -p 8000:8000 -v /opt/adcm:/adcm/data
arenadata/adcm:latest
Запустите ADCM командой
docker start adcm
Убедитесь, что ADCM установлен корректно, для этого перейдите в браузере по адресу
http://<ip_of_your_server>.
В случае корректной установки откроется окно «Авторизация» (см. Рисунок - 4.10).
Рисунок - 4.10 Окно «Авторизация»
Для авторизации используйте следующие данные:
пользователь -
admin;пароль -
admin.
После завершения процедуры авторизации откроется главное окно программы Arenadata Cluster Manager (см. Рисунок - 4.11).
Рисунок - 4.11 Главное окно программы «Arenadata Cluster Manager»
4.27. Установка Arenadata Streaming (ADS)
Внимание
При условии установки CentOS 7.9
ADS устанавливается на кластере с помощью ADCM из загруженного установочного пакета (бандла).
Скачать установочный пакет (версия: ads_v1.6.0.0-1) можно с сайта разработчика:
https://store.arenadata.io/#products/arenadata_streaming.
Подробная инструкция по установке ADS приведена в официальной документации разработчика:
В данной инструкции описывается установка кластера Kafka и импорт уже установленного кластера Zookeeper.
Для создания кластера необходимо иметь предварительно загруженный бандл (версия: ads_v1.6.0.0-1). В графическом интерфейсе ADCM перейти в раздел CLUSTERS -> Create cluster. Создать кластер (см. Рисунок - 4.12).
Рисунок - 4.12 Создание кластера ADS через графический интерфейс ADCM
В разделе Services графического интерфейса ADCM необходимо добавить сервисы в созданный кластер (см. Рисунок - 4.13). Версии сервисов могут отличаться от указанных на рисунке.
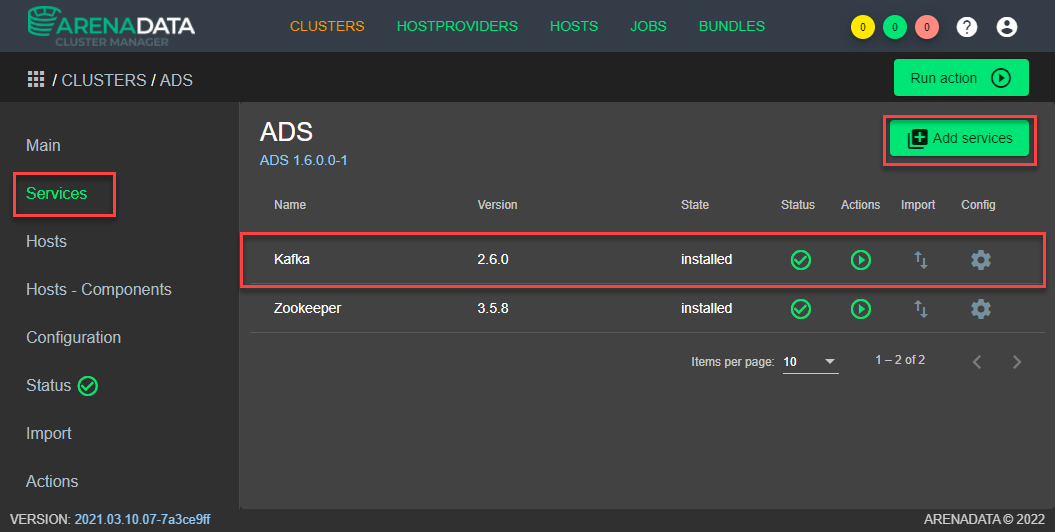
Рисунок - 4.13 Добавление через графический интерфейс ADCM сервисов в созданный кластер
В случае, если Kafka и Zookeeper разворачивается в одном кластере, необходимо добавить сервис Zookeeper.
В разделе Hosts графического интерфейса ADCM указать серверы созданного кластера, на которых будет развёрнуто ПО ADS (см. Рисунок - 4.14).
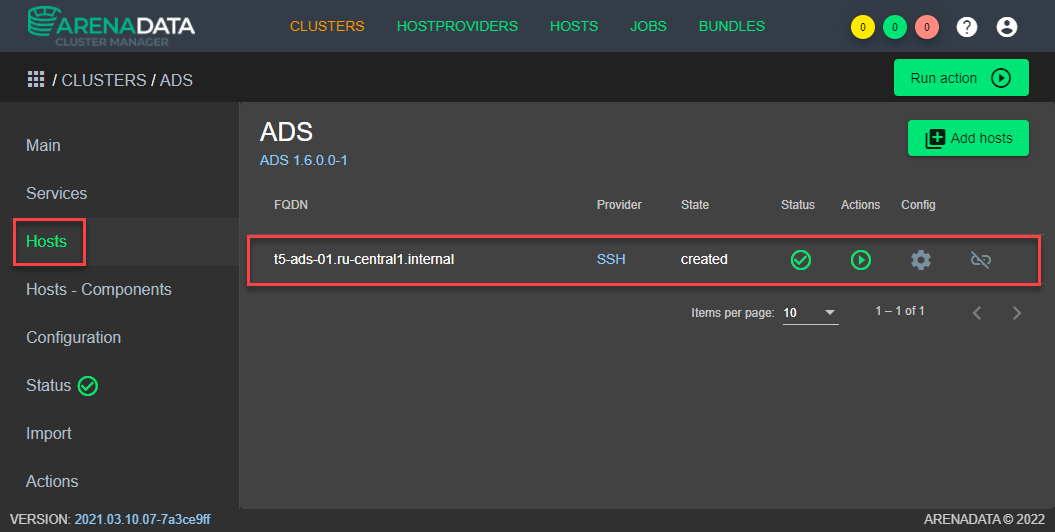
Рисунок - 4.14 Выбор через графический интерфейс ADCM серверов для развёртывания кластера ADS
В разделе Hosts - Components указать три узла (ноды) Kafka (см Рисунок - 4.15).
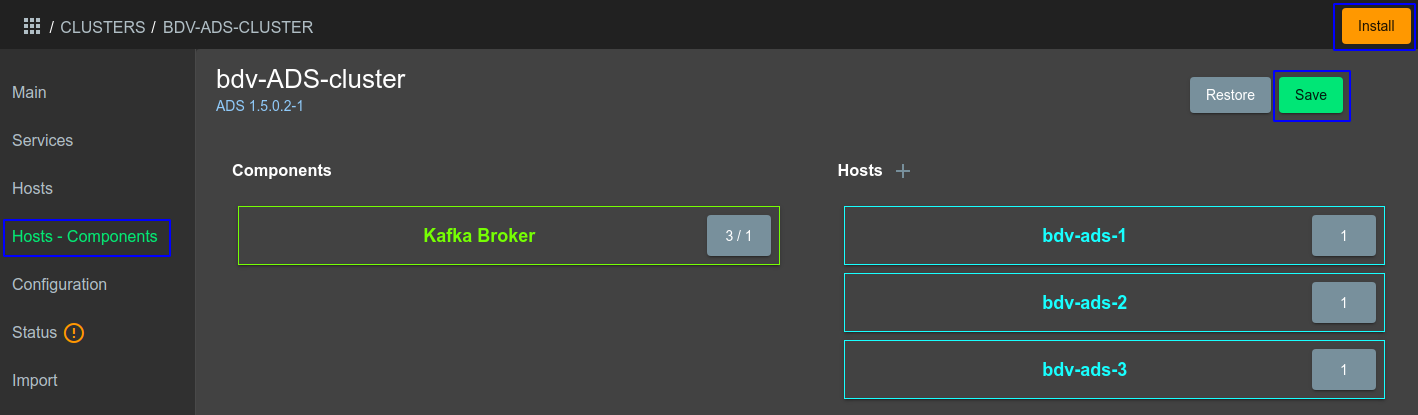
Рисунок - 4.15 Выбор через графический интерфейс ADCM узлов Kafka
Указать кластер Zookeeper в разделе Import, в случае если Zookeeper находится на другом кластере (см Рисунок - 4.16).
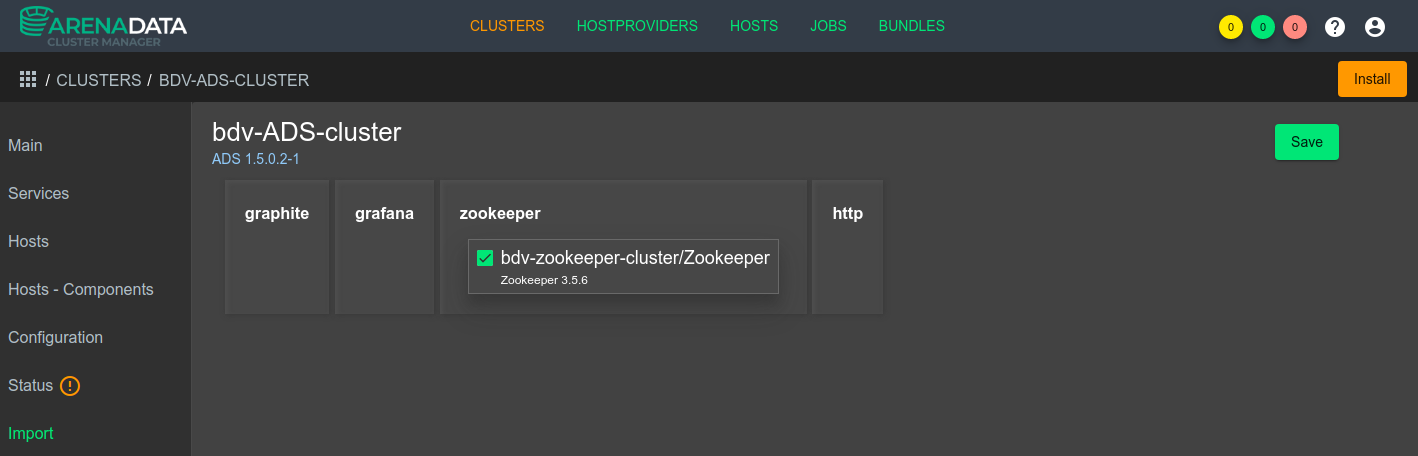
Рисунок - 4.16 Выбор через графический интерфейс ADCM кластера Zookeeper для импорта
Нажмите кнопку Install, чтобы запустить процесс установки. В окне «Дополнительные параметры» нажмите кнопку Run, чтобы выполнить установку (см Рисунок - 4.17).
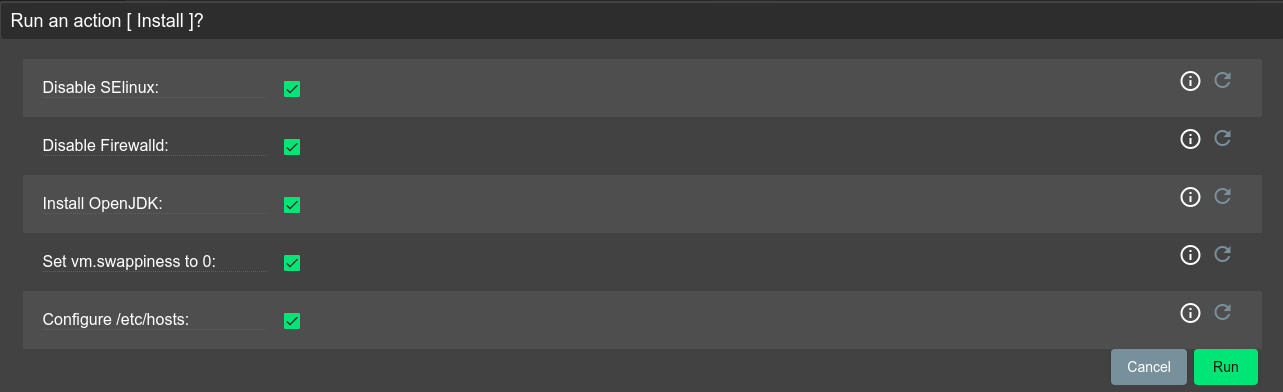
Рисунок - 4.17 Запуск через графический интерфейс ADCM процесса установки
Проверьте, что установка завершена, для этого:
Проверьте лог-файлы Zookeeper по относительному пути:
/var/log/zookeeper/
Проверьте лог-файл Kafka по относительному пути:
/var/log/kafka/
Проверьте настройки подключения к кластеру Zookeeper с помощью сторонней утилиты KafkaTool (см Рисунок - 4.18).
Проверьте корректность разрешения имен серверов для автоматического определения bootstrap-серверов Kafka. При отсутствии DNS-севера добавьте в локальный
hostsадреса Kafka.Определите путь
chroot path, для этого выполните на любом сервере Zookeeper команду:
/usr/lib/zookeeper/bin/zkCli.sh
Далее, выполните команду:
ls /arenadata/cluster
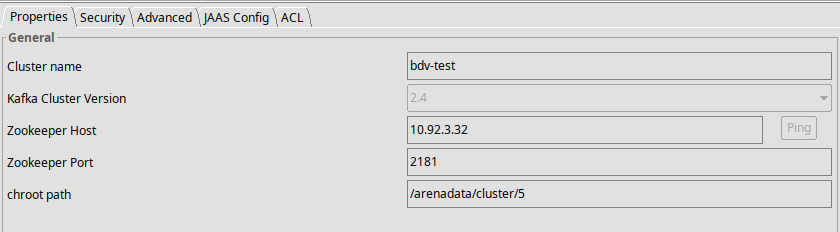
Рисунок - 4.18 Проверка через графический интерфейс ADCM настроек подключения к кластеру Zookeeper
При проверке, в данном руководстве, использовался графический интерфейс приложения Offset Explorer 2.1 (https://www.kafkatool.com/download.html).