4. Установка программы
Установка витрины данных производится без необходимости доступа к сети «Интернет» для скачивания компонент.
4.1. Порядок установки
Проверить соответствие серверов техническим характеристикам (см. раздел «Настройка на состав технических средств»).
Выполнить предварительные действия перед установкой программы (см. раздел «Предварительные действия»).
Установить на серверы, в соответствующем порядке, следующее программное обеспечение:
Arenadata Cluster Manager (ADCM) - при условии использвания CentOS 7.9;
Arenadata Streaming (ADS) - при условии использвания CentOS 7.9;
коннектор Kafka-Postgres;
ProStore;
СМЭВ QL Сервер;
СМЭВ3-адаптер;
ПОДД-адаптера - Модуль исполнения запросов;
ПОДД-адаптер – Модуль MPPR;
ПОДД-адаптер – Модуль MPPW;
ПОДД-адаптер – Модуль импорта данных табличных параметров;
ПОДД-адаптер – Модуль группировки данных табличных параметров;
ПОДД-адаптер – ПОДД-адаптер – Wrapper;
Data-uploader – Модуль исполнения асинхронных заданий;
REST-uploader – Модуль асинхронной загрузки данных из сторонних источников;
ПОДД-адаптер – Модуль подписки;
BLOB-адаптер;
Сервис формирования документов;
ETL;
CSV-uploader;
REST-адаптер;
Counter-provider.
Проверить работу всех компонентов программы (см. раздел «Проверка программы»).
Версии компонентов Типового ПО «Витрина данных» конфигурации Стандарт представлены в таблице ниже (см Таблица 4.5)
Наименование компонента |
Версия |
Техническое наименование |
|---|---|---|
ПОДД Агент |
3.8.0 |
ПОДД-Агент:3.8.0 |
СМЭВ3-адаптер |
1.11.1 |
smev3-adapter:1.11.1 |
printable-form-service |
1.11.1 |
printable-form-service:1.11.1 |
rest-adapter |
1.11.1 |
rest-adapter:1.11.1 |
rest-uploader |
1.11.1 |
rest-uploader:1.11.1 |
data-uploader |
1.11.1 |
data-uploader:1.11.1 |
blob-adapter |
1.11.1 |
blob-adapter:1.11.1 |
podd-adapter-query |
1.11.1 |
podd-adapter-query:1.11.1 |
podd-adapter-replicator |
1.11.1 |
podd-adapter-replicator:1.11.1 |
podd-adapter-group-repl |
1.11.1 |
podd-adapter-group-repl:1.11.1 |
podd-adapter-mppr |
1.11.1 |
podd-adapter-mppr:1.11.1 |
podd-adapter-mppw |
1.11.1 |
podd-adapter-mppw:1.11.1 |
podd-adapter-group-tp |
1.11.1 |
podd-adapter-group-tp:1.11.1 |
podd-adapter-import-tp |
1.11.1 |
podd-adapter-import-tp:1.11.1 |
podd-avro-defragmentator |
1.11.1 |
podd-avro-defragmentator:1.11.1 |
smevql-server |
1.11.1 |
smevql-server:1.11.1 |
csv-uploader |
1.11.1 |
csv-uploader:1.11.1 |
counter-provider |
1.11.1 |
counter-provider:1.11.1 |
backup-manager |
1.11.1 |
backup-manager:1.11.1 |
query-execution |
6.5.0 |
query-execution:6.5.0 |
status-monitor |
6.5.0 |
status-monitor:6.5.0 |
kafka |
2.6.0 |
kafka:2.6.0 |
zookeeper |
3.5.7 |
zookeeper:3.5.7 |
redis |
7.0.11 |
redis:7.0.11 |
fdw |
0.10.2 |
fdw:0.10.2 |
pxf |
1.0 |
pxf:1.0 |
4.2. Установка ПО ProStore
Установка ProStore должна осуществляться после установки СУБД и брокера сообщений.
ПО ProStore поставляется в виде дистрибутива с компонентами в jar-файлах.
Процесс установки состоит из следующих действий:
запуск службы dtm-status-monitor;
запуск службы Prostore-query-execution-core.
4.2.1. Запуск службы dtm-status-monitor
# создание символической ссылки на файл конфигурации dtm-status-monitor
sudo ln -s ~/prostore/dtm-status-monitor/src/main/resources/application.yml ~/prostore/dtm-status-monitor/target/application.yml
# запуск dtm-status-monitor в отдельном окне терминала с указанием порта, заданного в конфигурации Prostore (core:kafka:statusMonitor)
cd ~/prostore/dtm-status-monitor/target
java -Dserver.port=9095 -jar dtm-status-monitor-<version>.jar
Внимание
Запуск службы dtm-status-monitor без указания порта -Dserver.port приведёт к конкуренции с сервисом Prostore за порт 8080, используемый по умолчанию.
4.2.2. Запуск службы Prostore-query-execution-core
Создать на сервере директорию для загрузки дистрибутива.
Загрузить файлы дистрибутива в созданную директорию.
Настроить конфигурационный файл Prostore application.yaml.
Запустить jar-файлы со значением номера порта, указанным в конфигурации Prostore (по умолчанию — 8080):
# запуск файла dtm-query-execution-core-<version>.jar (например, dtm-query-execution-core-5.8.0.jar)
cd ~/prostore/dtm-query-execution-core/target
java -jar dtm-query-execution-core-<version>.jar
Примечание
Чтобы запустить ProStore с другим номером порта, задайте нужное значение с помощью параметра server:port в конфигурации Prostore или с помощью переменной окружения DTM_METRICS_PORT. Подробнее о параметрах конфигурации и способах их переопределения см. в разделе Конфигурация системы.
Проверить корректность функционирования ProStore.
Конфигурационный файл Prostore application.yaml
#
# Copyright © 2021 ProStore
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
logging:
level:
ru.datamart.prostore.query.execution: ${DTM_LOGGING_LEVEL:TRACE}
server:
port: ${DTM_METRICS_PORT:8080}
management:
endpoints:
enabled-by-default: ${DTM_METRICS_ENABLED:true}
web:
exposure:
include: ${DTM_METRICS_SCOPE:info, health}
core:
plugins:
active: ${CORE_PLUGINS_ACTIVE:ADP}
http:
port: ${DTM_CORE_HTTP_PORT:9090}
tcpNoDelay: ${DTM_CORE_HTTP_TCP_NO_DELAY:true}
tcpFastOpen: ${DTM_CORE_HTTP_TCP_FAST_OPEN:true}
tcpQuickAck: ${DTM_CORE_HTTP_TCP_QUICK_ACK:true}
env:
name: ${DTM_NAME:test}
restoration:
autoRestoreState: ${AUTO_RESTORE_STATE:true}
matviewsync:
periodMs: ${MATERIALIZED_VIEWS_SYNC_PERIOD_MS:5000}
retryCount: ${MATERIALIZED_VIEWS_RETRY_COUNT:10}
maxConcurrent: ${MATERIALIZED_VIEWS_CONCURRENT:2}
ddlqueue:
enabled: ${CORE_DDL_QUEUE_ENABLED:true}
datasource:
edml:
defaultChunkSize: ${EDML_DEFAULT_CHUNK_SIZE:1000}
pluginStatusCheckPeriodMs: ${EDML_STATUS_CHECK_PERIOD_MS:1000}
firstOffsetTimeoutMs: ${EDML_FIRST_OFFSET_TIMEOUT_MS:15000}
changeOffsetTimeoutMs: ${EDML_CHANGE_OFFSET_TIMEOUT_MS:10000}
zookeeper:
connection-string: ${ZOOKEEPER_DS_ADDRESS:localhost}
connection-timeout-ms: ${ZOOKEEPER_DS_CONNECTION_TIMEOUT_MS:30000}
session-timeout-ms: ${ZOOKEEPER_DS_SESSION_TIMEOUT_MS:86400000}
chroot: ${ZOOKEEPER_DS_CHROOT:/adtm}
kafka:
producer:
property:
key.serializer: org.apache.kafka.common.serialization.StringSerializer
value.serializer: org.apache.kafka.common.serialization.StringSerializer
cluster:
zookeeper:
connection-string: ${ZOOKEEPER_KAFKA_ADDRESS:localhost}
connection-timeout-ms: ${ZOOKEEPER_KAFKA_CONNECTION_TIMEOUT_MS:30000}
session-timeout-ms: ${ZOOKEEPER_KAFKA_SESSION_TIMEOUT_MS:86400000}
chroot: ${ZOOKEEPER_KAFKA_CHROOT:}
admin:
inputStreamTimeoutMs: ${KAFKA_INPUT_STREAM_TIMEOUT_MS:2000}
status.event.publish:
enabled: ${KAFKA_STATUS_EVENT_ENABLED:false}
statusMonitor:
statusUrl: ${STATUS_MONITOR_URL:http://localhost:9095/status}
versionUrl: ${STATUS_MONITOR_VERSION_URL:http://localhost:9095/versions}
vertx:
blocking-stacktrace-time: ${DTM_VERTX_BLOCKING_STACKTRACE_TIME:1}
pool:
worker-pool: ${DTM_CORE_WORKER_POOL_SIZE:20}
event-loop-pool: ${DTM_CORE_EVENT_LOOP_POOL_SIZE:20}
task-pool: ${DTM_CORE_TASK_POOL_SIZE:20}
task-timeout: ${DTM_CORE_TASK_TIMEOUT:86400000}
cache:
initialCapacity: ${CACHE_INITIAL_CAPACITY:100000}
maximumSize: ${CACHE_MAXIMUM_SIZE:100000}
expireAfterAccessMinutes: ${CACHE_EXPIRE_AFTER_ACCESS_MINUTES:99960}
delta:
rollback-status-calls-ms: ${DELTA_ROLLBACK_STATUS_CALLS_MS:2000}
statistics:
enabled: ${CORE_STATISTICS_ENABLED:true}
threadsCount: ${CORE_STATISTICS_THREADS_COUNT:2}
adp:
datasource:
user: ${ADP_USERNAME:dtm}
password: ${ADP_PASS:dtm}
host: ${ADP_HOST:localhost}
port: ${ADP_PORT:5432}
poolSize: ${ADP_MAX_POOL_SIZE:3}
executorsCount: ${ADP_EXECUTORS_COUNT:3}
fetchSize: ${ADP_FETCH_SIZE:1000}
poolRequestTimeout: ${ADP_POOL_REQUEST_TIMEOUT:0}
preparedStatementsCacheMaxSize: ${ADP_PREPARED_CACHE_MAX_SIZE:256}
preparedStatementsCacheSqlLimit: ${ADP_PREPARED_CACHE_SQL_LIMIT:2048}
preparedStatementsCache: ${ADP_PREPARED_CACHE:true}
mppw:
restStartLoadUrl: ${ADP_REST_START_LOAD_URL:http://localhost:8096/newdata/start}
restStopLoadUrl: ${ADP_REST_STOP_LOAD_URL:http://localhost:8096/newdata/stop}
restVersionUrl: ${ADP_MPPW_CONNECTOR_VERSION_URL:http://localhost:8096/versions}
kafkaConsumerGroup: ${ADP_KAFKA_CONSUMER_GROUP:adp-load}
mppr:
restLoadUrl: ${ADP_MPPR_QUERY_URL:http://localhost:8094/query}
restVersionUrl: ${ADP_MPPR_CONNECTOR_VERSION_URL:http://localhost:8094/versions}
4.3. Установка СМЭВ QL Сервера
Создать новое приложение СМЭВ QL Сервера командой:
java -jar smevql-server-all.jar new <new-app-name>
Данная команда создаст структуру папок сервера внутри <new-app-name> и исполняемый файл smevql.
4.4. Установка СМЭВ3-адаптера
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Установка СМЭВ3-адаптера возможна, только если были добавлены ключи провайдера электронной подписи (например, КриптоПро).
Установка СМЭВ3-адаптер возможна, только если были добавлены ключи (контейнер закрытого ключа) для сервиса КриптоПро.
В случае использования для электронной подписи сервиса КриптоПро, необходимо предварительно скачать:
КриптоПро JCP (https://www.cryptopro.ru/download?pid=129) для Java JDK на сервер, где будет установлен СМЭВ3–адаптер.
Установить загруженное ПО, следуя инструкции и документации на официальном сайте.
Получить сертификат для установки от уполномоченных лиц и установить его в КриптоПро.
Модуль СМЭВ3-адаптер поставляется в виде JAR-файла. В поставку также входят следующие файлы:
файл настроек конфигурации модуля СМЭВ3-адаптер
application.yml;файлы для подключения к ProStore: JDBC–драйвер (
dtm-jdbc-driver-*.*.*.jar) иcommons-lang3-3.12.0.jar;сконфигурированные pebble-шаблоны.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить JAR-файл модуля.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе в разделе Конфигурация СМЭВ3-адаптер (application.yml) Руководства администратора.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/smev3-adapter.
В случае, если ранее была установлена старая версия СМЭВ3-адаптера, сделайте его резервную копию.
Загрузите в созданную на предыдущем шаге папку:
JAR-файл модуля;
файл настроек конфигурации модуля СМЭВ3-адаптер (
application.yml);файлы JDBC-драйвер (
dtm-jdbc-driver-*.*.*.jar) иcommons-lang3-3.12.0.jarдля подключения к ProStore;сконфигурированные pebble-шаблоны.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.5. Установка ПОДД-адаптера - Модуль исполнения запросов
Описание настроек модуля приведено в «Руководстве администратора».
Внимание
Данное руководство описывает процесс установки ПОДД-адаптера - Модуль исполнения запросов в «Витрину данных НСУД», для «Витрины данных Лайт» модуль будет добавлен автоматически при первоначальной установке программы.
Общий процесс установки состоит из следующих действий:
Настройка конфигурации ПОДД-адаптера - Модуль исполнения запросов в файле
application.yml.Запуск модуля согласно инструкции см Запуск ПОДД-адаптера - Модуль исполнения запросов.
Установка сервисов и необходимых сервисных баз данных.
Внимание
Установка данных сервисов выполняется после установки «Core Services».
Действия по установке ПОДД-адаптера - Модуль исполнения запросов выполняются через SSH-консоль технологического пользователя.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml для ПОДД-адаптера - Модуль исполнения запросов см. в разделе Конфигурация ПОДД-адаптера - Модуль исполнения запросов (application.yml) Руководства администратора.
Примечание
Значения настроек MYSQL_USER для MariaDB и SUBSCR_DB_USER для ПОДД-адаптера - Модуль исполнения запросов, а также MYSQL_PASSWORD и SUBSCR_DB_PASS, должны совпадать.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.6. Установка ПОДД-адаптер – Модуль MPPR
Описание настроек модуля приведено в «Руководстве администратора».
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml, пример которого и возможные настройки конфигурации модуля см. в разделе Конфигурация ПОДД-адаптера - Модуль MPPR (application.yml) Руководства администратора.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название jar-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.7. Установка ПОДД-адаптер-Модуль MPPW
Описание настроек модуля приведено в «Руководстве администратора».
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml, пример которого и возможные настройки конфигурации модуля см. в разделе см. Конфигурация модуля ПОДД-адаптер - Модуль MPPW (application.yml) Руководства администратора.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-mppw.
В случае, если ранее была установлена старая версия модуля ПОДД-адаптер – Модуль MPPW, сделайте его резервную копию.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/opt/podd-adapter-mppw
где,
file.jar- название jar-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-mppw- директория на сервере, в которую будет загружен файл.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.8. Установка ПОДД-адаптер – Модуль импорта данных табличных параметров
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля ПОДД-адаптер - Модуль импорта данных табличных параметров (application.yml) Руководства администратора.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-import-tp.
В случае, если ранее была установлена старая версия модуля ПОДД-адаптер - Модуль импорта данных табличных параметров, сделайте его резервную копию.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/podd-adapter-import-tp
где,
file.jar- название jar-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-import-tp- директория на сервере, в которую будет загружен файл.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.9. Установка ПОДД-адаптер – Модуль группировки данных табличных параметров
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля ПОДД-адаптер - Модуль импорта данных табличных параметров (application.yml) Руководства администратора.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-import-tp.
В случае, если ранее была установлена старая версия модуля ПОДД-адаптер - Модуль импорта данных табличных параметров, сделайте его резервную копию.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/podd-adapter-import-tp
где,
file.jar- название jar-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-import-tp- директория на сервере, в которую будет загружен файл.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.10. Установка ПОДД-адаптер – Wrapper
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля ПОДД-адаптер - Wrapper (application.yml) Руководства администратора.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-avro-defragmentator.
В случае, если ранее была установлена старая версия модуля ПОДД-адаптер - Wrapper, сделайте его резервную копию.
Загрузите в созданную на предыдущем шаге папку:
JAR-файл модуля;
файл настроек конфигурации модуля ПОДД-адаптер - Wrapper (application.yml);
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/opt/podd-avro-defragmentator
где,
file.jar- название JAR-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-avro-defragmentator- директория на сервере, в которую будет загружен файл.
4.11. Установка модуля группировки чанков репликации
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml, пример которого и возможные настройки конфигурации модуля см. в разделе Конфигурация Модуля группировки чанков репликации (application.yml) Руководства администратора.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название jar-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.12. Установка DATA-uploder – Модуль исполнения асинхронных заданий
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля DATA-Uploader (application.yml) Руководства администратора.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.13. Установка REST-uploader – Модуль асинхронной загрузки данных из сторонних источников
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля REST-Uploader (application.yml) Руководства администратора.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.14. Установка ПОДД-адаптер – Модуль подписки
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля ПОДД-адаптер - Модуль подписок (application.yml) Руководства администратора.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/podd-adapter-replicator.
В случае, если ранее была установлена старая версия ПОДД-адаптера – Модуль подписки, сделайте его резервную копию.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/opt/podd-adapter-replicator
где,
file.jar- название JAR-файла модуля;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/opt/podd-adapter-replicator- директория на сервере, в которую будет загружен файл.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.15. Установка BLOB-адаптер
Описание настроек модуля приведено в «Руководстве администратора».
Модуль BLOB-адаптер поставляется в виде jar-файла. В поставку также входит файл настроек конфигурации модуля BLOB-адаптер (application.yml);
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить jar-файл модуля.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. :ref:`blob_adapter_config.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/blob-adapter.
В случае, если ранее была установлена старая версия модуля BLOB-адаптер, сделайте его резервную копию.
Загрузите в созданную на предыдущем шаге папку:
jar-файл модуля;
файл настроек конфигурации модуля BLOB-адаптер (
application.yml).
4.16. Установка Сервиса формирования документов
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Модуль Сервис формирования документов поставляется в виде JAR-файла. В поставку также входят следующие файлы:
файл настроек конфигурации модуля Сервис формирования документов (
application.yml);файлы для подключения к Prostore: JDBC-драйвер (
dtm-jdbc-driver-*.*.*.jarиcommons-lang3-3.12.0.jar).
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить JAR-файл модуля.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация Сервиса Формирования документов (application.yml) Руководства администратора.
Создайте на сервере папку, в которую будут загружены файлы модуля, например, /opt/printable-form-service.
В случае, если ранее была установлена старая версия модуля Сервис формирования документов, сделайте его резервную копию.
Загрузите в созданную на предыдущем шаге папку:
JAR-файл модуля;
файл настроек конфигурации модуля Сервис формирования документов (
application.yml);файлы JDBC-драйвер (
dtm-jdbc-driver-*.*.*.jar) иcommons-lang3-3.12.0.jarдля подключения к Prostore.
Кластеризация модуля достигается путем запуска копии экземпляра данного модуля. Оптимальным вариантом является использование оркестраторов, например:
Kubernetes;
Openshift;
Docker-swarm;
Nomad.
4.17. Установка ETL
4.17.1. Установка Apache Airflow
4.17.1.1. Подготовка конфигурации
Клонировать репозиторий Apache Airflow из официального репозитория:
git clone https://github.com/apache/airflow.git
Перейти в папку airflow
Создать в папке файл
Dockerfile.customсо следующим содержимым:FROM ${BASE_AIRFLOW_IMAGE} SHELL ["/bin/bash", "-o", "pipefail", "-e", "-u", "-x", "-c"] USER 0 # Install Java RUN mkdir -pv /usr/share/man/man1 \\ && mkdir -pv /usr/share/man/man7 \\ && curl -fsSL https://adoptopenjdk.jfrog.io/adoptopenjdk/api/gpg/key/public \| apt-key add - \\ && echo 'deb https://adoptopenjdk.jfrog.io/adoptopenjdk/deb/ buster main' > \\ /etc/apt/sources.list.d/adoptopenjdk.list \\ && apt-get update \\ && apt-get install --no-install-recommends -y \\ adoptopenjdk-8-hotspot-jre \\ && apt-get autoremove -yqq --purge \\ && apt-get clean \\ && rm -rf /var/lib/apt/lists/\* # Установка JDR 1.8 ENV JAVA_HOME=/usr/lib/jvm/adoptopenjdk-8-hotspot-jre-amd64 USER ${AIRFLOW_UID} # Установка компонента apache.spark RUN pip install --upgrade pip \\ && pip install --no-cache-dir --user 'apache-airflow[apache.spark]'
4.17.1.2. Установка Apache Airflow
Установка Apache Airflow выполняется с помощью Docker. Установка Docker описана в разделе «Установка Arenadata Cluster Manager (ADCM)» Установка Arenadata Cluster Manager (ADCM).
Создайте новый образ в Docker, в той же директории, где расположен файл
Dockerfile.custom.
Пример:
docker build . \\
--build-arg BASE_AIRFLOW_IMAGE="apache/airflow:2.0.1-python3.8" \\
-f Dockerfile.java8 \\
-t airflow:2.0.1-python3.8-custom
Скачать файл
docker-compose.yamlс официального сайта Airflow https://Airflow.apache.org/docs/apache-airflow/2.0.1/docker-compose.yamlУстановить
docker-compose.yamlчерез SSH-консоль технологического пользователя.
Выдать права на исполнение файла:
sudo chmod +x /usr/local/bin/docker-compose
Запустить sudo:
ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
Проверить корректность установки:
$ docker-compose --version docker-compose version 1.28.6, build 1110ad01
Перейти в директорию с файлом
docker-compose.yml
Например:
cd ~/direct
Инициализировать компоненты:
docker-compose up airflow-init
Запустить сервисы с новым образом:
docker-compose up AIRFLOW_IMAGE_NAME=apache/airflow:2.0.1-python3.8-custom
4.17.2. Установка Apache Spark
Установка Docker описана в разделе «Установка Arenadata Cluster Manager (ADCM)».
4.17.2.1. Подготовка конфигурации
Клонировать репозиторий Apache Airflow из официального репозитория
git clone https://github.com/big-data-europe/docker-spark.git
Перейти в директорию docker-spark
Пример:
cd ~/direct
Выполнить скрипт ./build.sh или вручную последовательно запустить следующие команды:
сборка базового образа
docker build -t bde2020/spark-base:3.1.1-hadoop3.2
- сборка образа мастер
docker build -t bde2020/spark-master:3.1.1-hadoop3.2
- сборка образа воркера
docker build -t bde2020/spark-worker:3.1.1-hadoop3.2
Проверить наличие собранных образов:
Выполнить команду docker images:
REPOSITORY TAG IMAGE ID CREATED SIZE
bde2020/spark-worker 3.1.1-hadoop3.2 05c349b4646f 4 minutes ago 460MB
bde2020/spark-master 3.1.1-hadoop3.2 7918c5357d6d 4 minutes ago 460MB
bde2020/spark-base 3.1.1-hadoop3.2 5430434220d2 4 minutes ago 460MB
4.17.2.2. Установка
Перейти в директорию docker-spark, где располагается файл
docker-compose.yml
Пример:
cd ~/direct
Запустить Apache Spark командой:
docker-compose up
Проверить командой:
- ::
docker ps
В списке запущенных образов должны присутствовать spark-worker и spark-master.
4.17.3. Установка Apache Hadoop
Установка Docker описана в разделе «Установка Arenadata Cluster Manager (ADCM)».
4.17.3.1. Подготовка конфигурации
Клонировать репозиторий Apache Hadoop из официального репозитория:
git clone https://github.com/big-data-europe/docker-hadoop.git
Перейти в папку docker-hadoop
Например:
cd ~/direct
Выполнить скрипт
make buildили вручную последовательно запустить следующие команды:
сборка базового образа:
docker build -t bde2020/hadoop-base:master ./base
сборка остальных образов:
docker build -t bde2020/hadoop-namenode:master ./namenode docker build -t bde2020/hadoop-datanode:master ./datanode docker build -t bde2020/hadoop-resourcemanager:master ./resourcemanager docker build -t bde2020/hadoop-nodemanager:master ./nodemanager docker build -t bde2020/hadoop-historyserver:master ./historyserver docker build -t bde2020/hadoop-submit:master ./submit
Проверить наличие собранных образов:
Выполнить команду docker images:
REPOSITORY TAG IMAGE ID CREATED SIZE
bde2020/hadoop-submit master 665a424edc23 9 minutes ago 1.37GB
bde2020/hadoop-historyserver master ff53bf6835e2 9 minutes ago 1.37GB
bde2020/hadoop-nodemanager master c48c47bc840f 9 minutes ago 1.37GB
bde2020/hadoop-resourcemanager master 74fc55d664d2 9 minutes ago 1.37GB
bde2020/hadoop-datanode master f69c6460a292 9 minutes ago 1.37GB
bde2020/hadoop-namenode master 7a8250da8510 9 minutes ago 1.37GB
bde2020/hadoop-base master aeb6500ab4b5 10 minutes ago 1.37GB
4.17.3.2. Процесс установки
Перейти в директорию docker-hadoop, где располагается файл
docker-compose.yml
Например:
cd ~/direct
Поднять Apache Hadoop командой:
docker-compose up
Проверить командой:
docker ps
В списке запущенных образов должны присутствовать hadoop-resourcemanager, hadoop-historyserver, hadoop-datanode, hadoop-nodemanager, hadoop-namenode
4.17.4. Установка Tarantool(Vinyl)
Установка docker описана в разделе 3.3.2. Установка Менеджера кластера ADCM.
4.17.4.1. Подготовка конфигурации
Клонировать репозиторий Tarantool из официального репозитория:
git clone https://github.com/tarantool/docker.git
Выполнить сборку согласно инструкции: https://github.com/tarantool/docker#how-to-push-an-image-for-maintainers
Перейти в клонированную директорию docker
Например:
cd ~/direct
Выполнить сборку образа docker для Tarantool
export TAG=2
export OS=alpine DIST=3.9 VER=2.8.0
PORT=5200 make -f .gitlab.mk build
Проверить наличие собранных образов командой docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
tarantool/tarantool 2 27f80564ecce 2 minutes ago 298MB
Создать в клонированной директории docker файл
docker-compose.ymlсо следующим содержимым:
version: "3"
services:
tarantool1:
image: tarantool/tarantool:2
container_name: tarantool1
restart: always
networks:
- tarantool_network
ports:
- "3301:3301"
volumes:
- tarantool1_volume:/opt/tarantool
environment:
# https://github.com/tarantool/docker#environment-variables
TARANTOOL_REPLICATION: "tarantool1,tarantool2"
tarantool2:
image: tarantool/tarantool:2
container_name: tarantool2
restart: always
networks:
- tarantool_network
ports:
- "3302:3301"
volumes:
- tarantool2_volume:/opt/tarantool
environment:
TARANTOOL_REPLICATION: "tarantool1,tarantool2"
volumes:
tarantool1_volume:
tarantool2_volume:
networks:
tarantool_network:
driver: bridge
4.17.4.2. Процесс установки
Перейти в директорию docker, где располагается файл
docker-compose.yml
Например:
cd ~/direct
Пример запуска мастер-мастер репликации:
https://github.com/tarantool/docker#start-a-master-master-replica-set
Поднять Tarantool командой:
docker-compose up
Проверить командой:
docker ps
В списке запущенных образов должны присутствовать tarantool1 и tarantool2
4.18. Установка CSV-Uploader
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация CSV-uploader (application.yml) Руководства администратора.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.19. Установка REST-адаптера
Установка сервисов и необходимых сервисных баз данных.
Внимание
Установка данных сервисов выполняется после установки «Core Services».
Действия по установке выполняются на сервере ADCM через SSH-консоль технологического пользователя.
4.19.1. Установка docker-образов
Установка Docker описана в разделе «Установка Arenadata Cluster Manager (ADCM)» Установка Arenadata Cluster Manager (ADCM). Установить образ REST-адаптера, при этом файл образа .tar должен быть загружен через Docker из дистрибутива программы.
Пример команды для установки:
docker image load -i <image_file>
4.19.2. Подготовка конфигурации
Для подготовки скриптов необходимо выполнить следующие действия:
Отредактировать переменные в файле
application.ymlдля рабочей среды. Файл необходимо поместить в директорию config:
Указать корректный путь до целевой БД. Переменная
jdbc_url.
Например:
jdbc:{drv_name}://{IP_Host}:{Port}/{db_name}
, где:
drv_name- имя драйвера , берется из описания драйвера базыIP_Host- ip или имя хоста с базой;Port- порт, на котором будет слушать сервис . По умолчанию 8080;db_name- имя базы данных.Указать
driver-class-name- имя класса , берется из описания драйвера базыУказать переменную
file_path- наименование файла с описанием запросов, по умолчаниюsample.yaml.Указать переменные
execquery- сопоставление operationId из файла с описанием запросов c файлом обработчиком, по умолчаниюsample.peb.
4.19.3. Процесс установки
Для установки необходимо выполнить следующие действия:
Перейти в директорию с файлом
docker-compose.yml
Например:
cd ~/direct
Поднять сервис конечных точек командой:
docker-compose up -d
Проверить установку следующей командой:
docker ps
В списке запущенных образов должен присутствовать rest-adapter
4.20. Установка Counter-provider
Описание настроек модуля приведено в «Руководстве администратора».
Действия по установке выполняются через SSH консоль технологического пользователя.
Общий процесс установки состоит из следующих действий:
Настроить конфигурацию модуля.
Создать на сервере директорию для загрузки файлов модуля.
Загрузить файлы модуля в созданную директорию.
Запустить модуль.
Проверить установку модуля.
Настройка конфигурации выполняется путем редактирования параметров файла application.yml. Пример конфигурации файла application.yml и возможные настройки конфигурации модуля см. в разделе Конфигурация модуля Counter-Provider (application.yml) Руководства администратора.
Для загрузки файла на сервер выполните команду:
scp file.jar user_name@IP:/home/dir
где,
file.jar- название JAR-файла;user_name- имя пользователя, например,sudoилиroot;IP- адрес сервера;/home/dir- директория на сервере, в которую будет загружен файл.
4.21. Установка коннектора Kafka-Postgres
Скопировать файлы:
kafka-postgres-writer-0.3.0.jar,
kafka-postgres-reader-0.3.0.jar,
kafka-postgres-avro-0.3.0.jar
из дистрибутива и загрузить в папку kafka-postgres-connector.
Скопировать конфигурационные файлы KAFKA-POSTGRES-WRITER application.yaml и KAFKA-POSTGRES-READER application.yaml в папку kafka-postgres-connector/config
Конфигурационный файл KAFKA-POSTGRES-WRITER application.yaml:
logging:
level:
ru.datamart.kafka: ${LOG_LEVEL:DEBUG}
org.apache.kafka: ${KAFKA_LOG_LEVEL:INFO}
http:
port: ${SERVER_PORT:8096}
vertx:
pools:
eventLoopPoolSize: ${VERTX_EVENT_LOOP_SIZE:12}
workersPoolSize: ${VERTX_WORKERS_POOL_SIZE:32}
verticle:
query:
instances: ${QUERY_VERTICLE_INSTANCES:12}
insert:
poolSize: ${INSERT_WORKER_POOL_SIZE:32}
insertPeriodMs: ${INSERT_PERIOD_MS:1000}
batchSize: ${INSERT_BATCH_SIZE:500}
consumer:
poolSize: ${KAFKA_CONSUMER_WORKER_POOL_SIZE:32}
maxFetchSize: ${KAFKA_CONSUMER_MAX_FETCH_SIZE:10000}
commit:
poolSize: ${KAFKA_COMMIT_WORKER_POOL_SIZE:1}
commitPeriodMs: ${KAFKA_COMMIT_WORKER_COMMIT_PERIOD_MS:1000}
client:
kafka:
consumer:
checkingTimeoutMs: ${KAFKA_CHECKING_TIMEOUT_MS:10000}
responseTimeoutMs: ${KAFKA_RESPONSE_TIMEOUT_MS:10000}
consumerSize: ${KAFKA_CONSUMER_SIZE:10}
closeConsumersTimeout: ${KAFKA_CLOSE_CONSUMER_TIMEOUT:15000}
property:
bootstrap.servers: ${KAFKA_BOOTSTRAP_SERVERS:kafka.host:9092}
group.id: ${KAFKA_CONSUMER_GROUP_ID:postgres-query-execution}
auto.offset.reset: ${KAFKA_AUTO_OFFSET_RESET:earliest}
enable.auto.commit: ${KAFKA_AUTO_COMMIT:false}
auto.commit.interval.ms: ${KAFKA_AUTO_INTERVAL_MS:1000}
datasource:
postgres:
database: ${POSTGRES_DB_NAME:test}
user: ${POSTGRES_USERNAME:dtm}
password: ${POSTGRES_PASS:dtm}
hosts: ${POSTGRES_HOSTS:localhost:5432}
poolSize: ${POSTGRES_POOLSIZE:10}
preparedStatementsCacheMaxSize: ${POSTGRES_CACHE_MAX_SIZE:256}
preparedStatementsCacheSqlLimit: ${POSTGRES_CACHE_SQL_LIMIT:2048}
preparedStatementsCache: ${POSTGRES_CACHE:true}
Конфигурационный файл KAFKA-POSTGRES-READER application.yaml:
logging:
level:
ru.datamart.kafka: ${LOG_LEVEL:DEBUG}
org.apache.kafka: ${KAFKA_LOG_LEVEL:INFO}
http:
port: ${SERVER_PORT:8094}
vertx:
pools:
eventLoopPoolSize: ${VERTX_EVENT_LOOP_SIZE:12}
workersPoolSize: ${VERTX_WORKERS_POOL_SIZE:32}
verticle:
query:
instances: ${QUERY_VERTICLE_INSTANCES:12}
datasource:
postgres:
database: ${POSTGRES_DB_NAME:test}
user: ${POSTGRES_USERNAME:dtm}
password: ${POSTGRES_PASS:dtm}
hosts: ${POSTGRES_HOSTS:localhost:5432}
poolSize: ${POSTGRES_POOLSIZE:10}
preparedStatementsCacheMaxSize: ${POSTGRES_CACHE_MAX_SIZE:256}
preparedStatementsCacheSqlLimit: ${POSTGRES_CACHE_SQL_LIMIT:2048}
preparedStatementsCache: ${POSTGRES_CACHE:true}
fetchSize: ${POSTGRES_FETCH_SIZE:1000}
kafka:
client:
property:
key.serializer: org.apache.kafka.common.serialization.ByteArraySerializer
value.serializer: org.apache.kafka.common.serialization.ByteArraySerializer
4.22. Установка Arenadata Cluster Manager (ADCM)
Внимание
При условии установки CentOS 7.9
Arenadata Cluster Manager (ADCM) – сервер, с которого будет централизованно производиться установка почти всех компонентов программы. Данный компонент обязателен для установки.
Arenadata Cluster Manager (ADCM) поставляется в docker-контейнерах, поэтому чтобы установить ADCM на сервере должен быть установлен Docker или совместимое программное обеспечение для работы с контейнерами. Текущая версия программного обеспечения несовместима с SELinux.
Подробная инструкция по установке Arenadata Cluster Manager (ADCM) приведена в официальной документации разработчика (https://docs.arenadata.io/adcm/user/install.html ).
Установка Arenadata Cluster Manager (ADCM) осуществляется пользователем согласно следующим этапам:
Выключить
selinux. Для этого в файле/etc/selinux/configустановите значениеSELINUX=disabledи перезапустить сервер командойreboot now.Установите Docker для этого используйте следующие команды:
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo yum install -y containerd.io yum install -y docker-ce-3:18.09.1-3.el7 systemctl enable docker systemctl start docker
Установить ADCM в Docker. Для этого используйте следующие команды:
docker pull arenadata/adcm:latest docker create --name adcm -p 8000:8000 -v /opt/adcm:/adcm/data arenadata/adcm:latest
Запустите ADCM командой:
docker start adcm
Убедитесь, что ADCM установлен корректно, для этого перейдите в браузере по адресу http: // <ip_of_your_server>.
В случае корректной установки откроется окно «Авторизация» (см. Рисунок - 4.8 ).
Рисунок - 4.8 Окно «Авторизация»
Для авторизации используйте следующие данные:
пользователь -
admin;пароль -
admin.
После завершения процедуры авторизации откроется главное окно программы Arenadata Cluster Manager (см. Рисунок - 4.9).
Рисунок - 4.9 Главное окно программы «Arenadata Cluster Manager»
4.23. Установка Arenadata Streaming (ADS)
Внимание
При условии установки CentOS 7.9
Arenadata Streaming (ADS) устанавливается на кластере с помощью ADCM из загруженного установочного пакета (бандла).
Скачать установочный пакет (версия: ads_v1.6.0.0-1) можно с сайта разработчика: https://store.arenadata.io/#products/arenadata_streaming.
Подробная инструкция по установке Arenadata Streaming (ADS) приведена в официальной документации разработчика (https://docs.arenadata.io/DTM/Install/ADS.html , https://docs.arenadata.io/ads/Install/index.html ). В данной инструкции описывается установка кластера Kafka и импорт уже установленного кластера Zookeeper. Установка Zookeeper на кластер приведена в инструкции по установке ADQM.
Для создания кластера необходимо иметь предварительно загруженный бандл (версия: ads_v1.6.0.0-1). В графическом интерфейсе ADCM перейти в раздел CLUSTERS -> Create cluster. Создать кластер (см. Рисунок - 4.10).
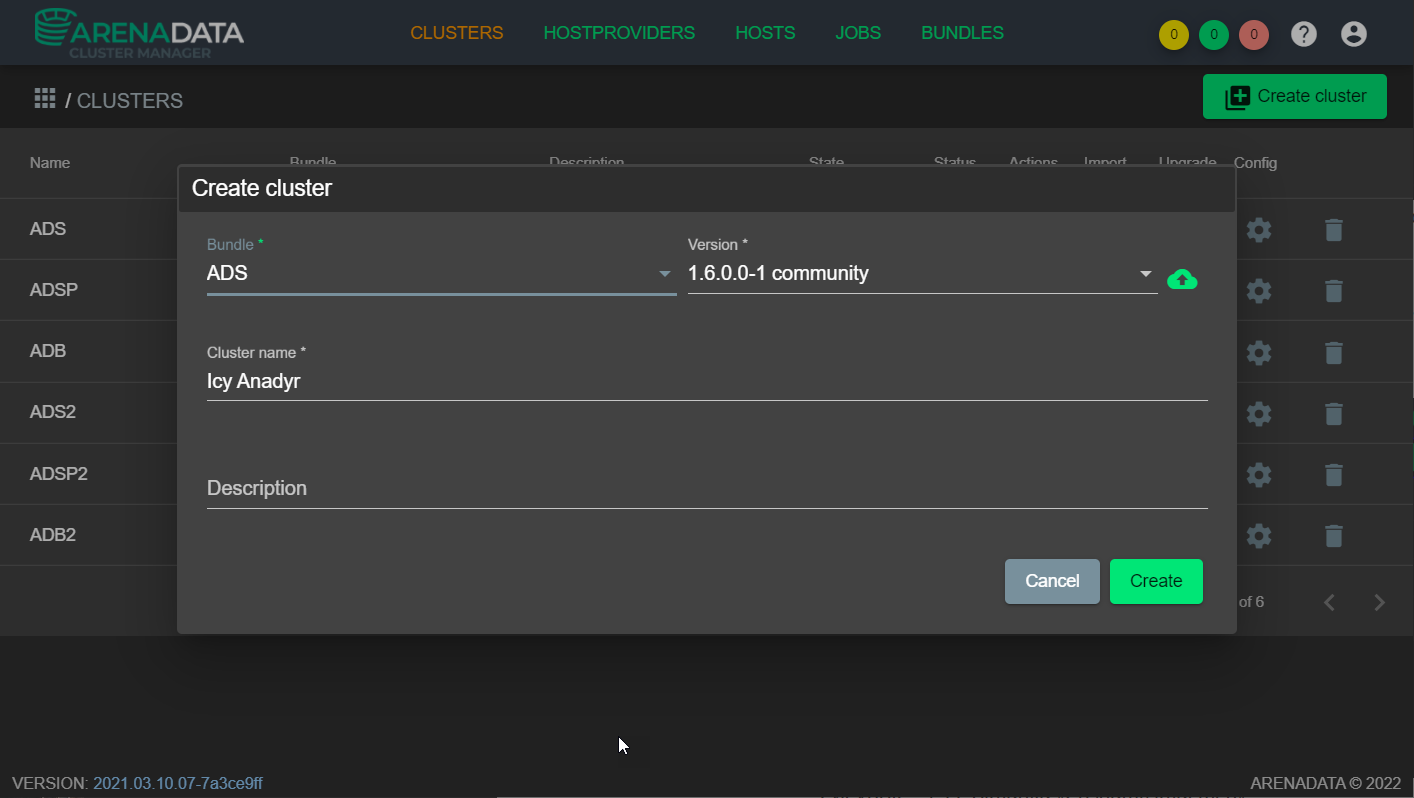
Рисунок - 4.10 Создание кластера ADS через графический интерфейс ADCM
В разделе Services графического интерфейса ADCM необходимо добавить сервисы в созданный кластер (см. Рисунок - 4.11). Версии сервисов могут отличаться от указанных на рисунке.
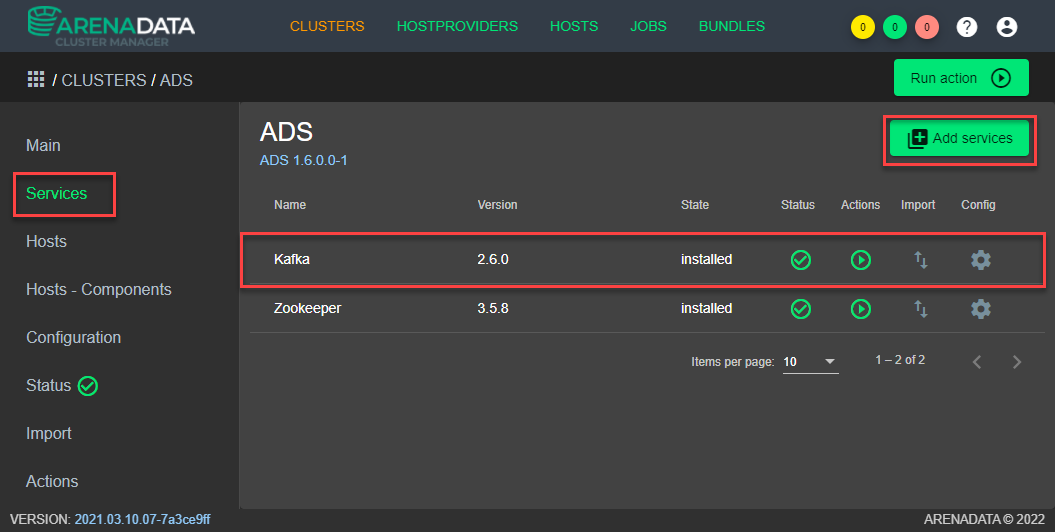
Рисунок - 4.11 Добавление через графический интерфейс ADCM сервисов в созданный кластер
В случае, если Kafka и Zookeeper разворачивается в одном кластере, необходимо добавить сервис Zookeeper.
В разделе Hosts графического интерфейса ADCM указать серверы созданного кластера, на которых будет развёрнуто ПО Arenadata Streaming (ADS) (см. Рисунок - 4.12).
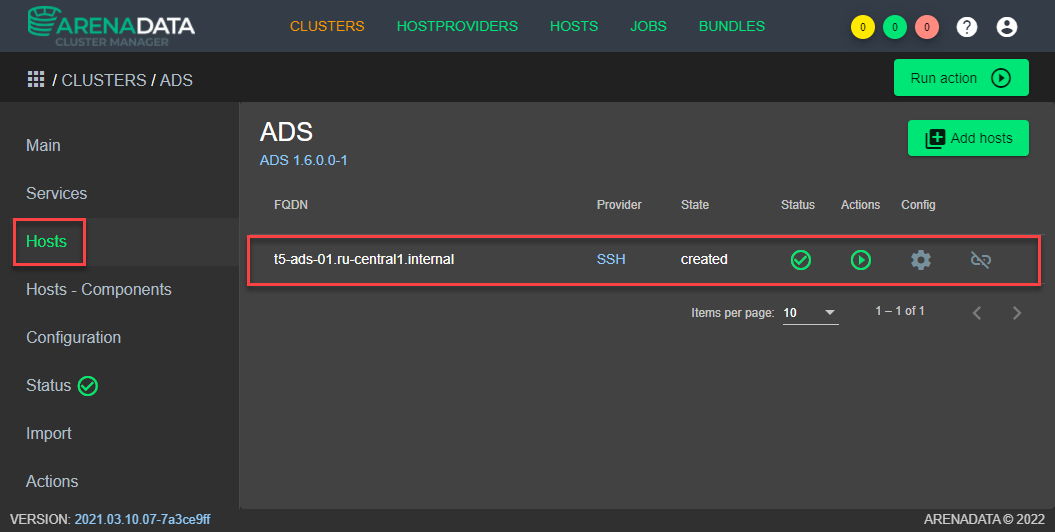
Рисунок - 4.12 Выбор через графический интерфейс ADCM серверов для развёртывания кластера ADS
В разделе Hosts - Components указать три узла (ноды) Kafka (см Рисунок - 4.13).
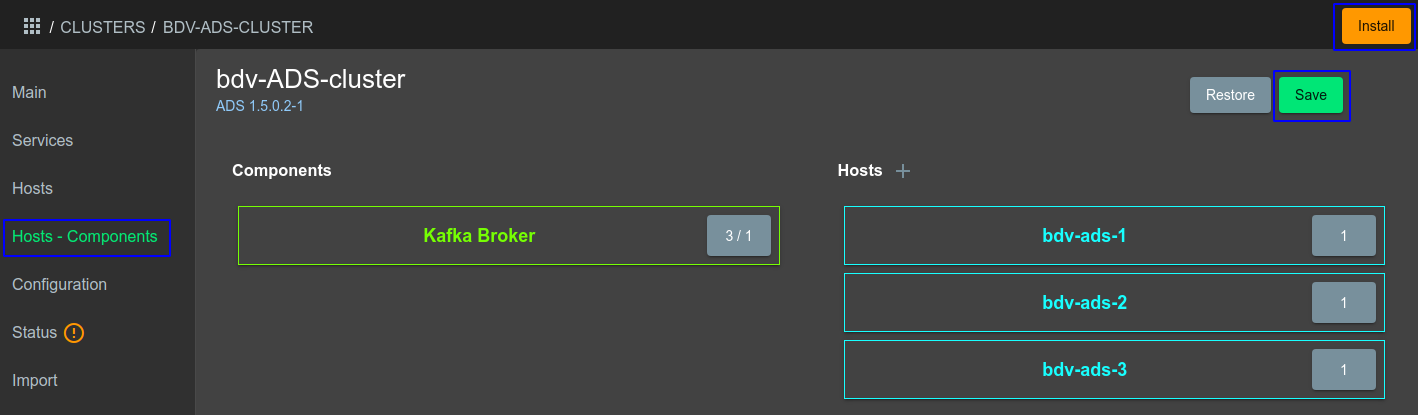
Рисунок - 4.13 Выбор через графический интерфейс ADCM узлов Kafka
Указать кластер Zookeeper в разделе Import, в случае если Zookeeper находится на другом кластере (см Рисунок - 4.14).
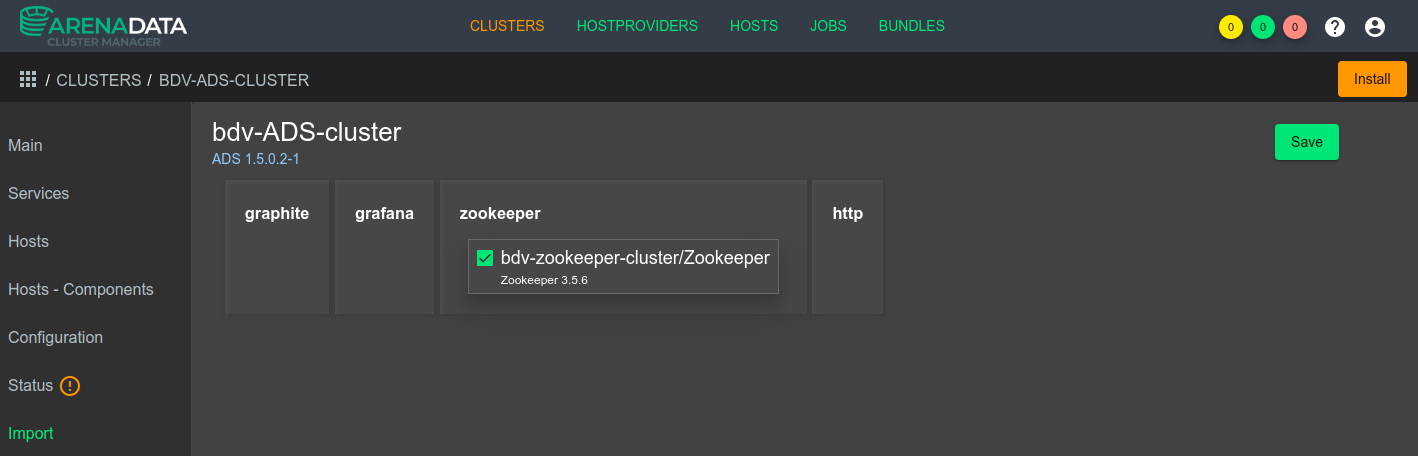
Рисунок - 4.14 Выбор через графический интерфейс ADCM кластера Zookeeper для импорта
Нажмите кнопку InstalL, чтобы запустить процесс установки. В окне «Дополнительные параметры» нажмите кнопку Run, чтобы выполнить установку (см Рисунок - 4.15).
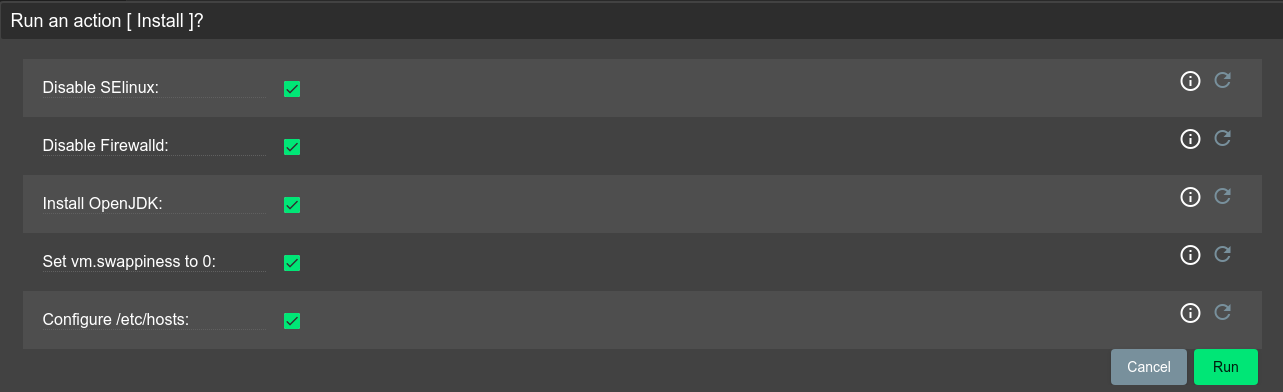
Рисунок - 4.15 Запуск через графический интерфейс ADCM процесса установки
Проверьте, что установка завершена, для этого:
Проверьте лог-файлы Zookeeper по относительному пути
/var/log/zookeeper/.
Проверьте лог-файл Kafka по относительному пути
/var/log/kafka/.
Проверьте настройки подключения к кластеру Zookeeper с помощью сторонней утилиты KafkaTool (см Рисунок - 4.16).
Проверьте корректность разрешения имен серверов для автоматического определения bootstrap-серверов Kafka. При отсутствии DNS-севера добавьте в локальный
hostsадреса Kafka.Определите путь
chroot path, для этого выполните на любом сервере Zookeeper команду:/usr/lib/zookeeper/bin/zkCli.sh
Далее, выполните команду:
ls /arenadata/cluster.
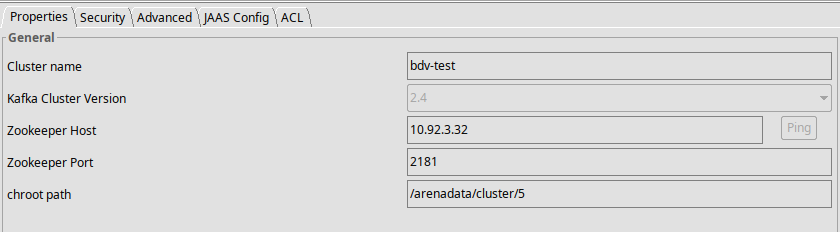
Рисунок - 4.16 Проверка через графический интерфейс ADCM настроек подключения к кластеру Zookeeper
При проверке, в данном руководстве, использовался графический интерфейс приложения Offset Explorer 2.1 (https://www.kafkatool.com/download.html).