1. Общее описание
Внимание
С версии 2.6.0 для хранения метаданных загрузчика требуется Prostore версии 7.6 и выше, хотя бы с одним ADP (для обеспечения высокой доступности персистентных данных модуля необходимо использование больше одного датасорса ADP). При использовании более ранней версии Prostore или отсутствии ADP невозможна работа загрузчика версии 2.6.0 и выше. Действия по выполнению миграции приведены в Раздел 3.1.7.1.1.
1.1. Назначение
Стандартный загрузчик (Standard-loader) - модуль управления данными (загрузка и/или удаление) в Витрине данных, формирования количественных оценок качества данных Витрины в части соответствия источнику данных.
Основные решаемые проблемы:
загрузка и удаление данных в Витрине (Раздел 2.3.6.3.1);
сверка данных ИС Источника и Витрины, в том числе автоматическая корректировка данных в Витрине (Раздел 2.3.6.3.2).
1.2. Термины и определения
В Таблица 2.19 приведено описание специфичных терминов стандартного загрузчика.
Термин |
Сокращение |
Определение |
|---|---|---|
Задание на загрузку |
Задание на загрузку данных из Источника в Витрину, в котором определяется каким запросом запрашивается информация, и в какие Витрины и таблицы загружаются данные. |
|
Задание сверки |
Задание для сверки данных между Источником и Витриной, в котором определяется Источники данных, запросы на получение контрольных сумм записей (хэшей), запросы на получение данных для корректирующей загрузки. |
|
Информационная система |
ИС |
Совокупность данных в базах, а также информационных технологий и технических средств, обеспечивающих их обработку и функционирование как единого целого для решения определенных задач. Отражается в метаданных Стандартного загрузчика, для группировки Источников данных. |
Исключение из корректировки |
Набор первичных ключей данных, по которым были попытки корректировки, но при повторной сверке остались Расхождения. |
|
Источник |
Конкретный источник данных для загрузки, в рамках ИС Источника. |
|
Корректирующая загрузка |
Загрузка данных из Источника в Витрину для устранения устойчивых, в том числе добавления и удаления записей. |
|
Модульный монолит |
Модулит |
Архитектурный подход, при котором приложение формируется из независимых компонентов, взаимодействующих между собой через определенные интерфейсы, а не напрямую. |
Попытка корректировки |
Набор первичных ключей данных, для которых инициирована корректирующая загрузка: Устойчивые расхождения текущего Сеанса сверки за вычетом справочника исключений из корректировки |
|
Расписание загрузки |
Расписание, задающее периодичность создания Сеансов загрузки данных в режиме Pull. |
|
Расписание сверки |
Расписание, задающее периодичность создания Сеансов сверки. |
|
Результат сравнения |
Расхождение |
Первичные найденные расхождения между данными Источника и Витрины на основании единичного Сеанса сверки. |
Сверка |
Совокупность действий по:
|
|
Сеанс загрузки |
Информация о факте и результатах загрузки данных. Может создаваться при:
|
|
Сеанс сверки |
Информация о факте и результатах сверки данных. |
|
Сервис Стандартного загрузчика |
Сервис |
Обособленная функциональная часть Стандартного загрузчика, способная запускаться и работать как на отдельной, так и вместе с другими компонентами на общей виртуальной машине Java |
Сервис чтения данных |
Reader (Ридер) |
Сервис Стандартного загрузчика, обеспечивающий чтение или прием данных из ИС Источника. |
Событие |
Запись о факте выполнения важных действий одним из сервисов стандартного загрузчика. |
|
Устойчивое расхождение |
Расхождения, сохраняющиеся длительное время и не спровоцированные изменениями данных в Источнике. Вычисляются на основании Расхождений двух идущих подряд Сеансов сверки. |
|
Форматно-логический контроль |
ФЛК |
Процесс проверки данных на соответствие заданным форматам и логическим правилам. |
Pull |
Режим работы при котором инициализация загрузки производится со стороны Reader. |
|
Push |
Режим работы, при котором инициализация загрузки производится ИС Источника или Оператором. При этом производится обращение к интерфейсу одного из Reader. При этом производится обращение к интерфейсу одного из Reader. |
1.3. Схема взаимодействия
Приложение реализовано в виде модулита:
в рамках одной JVM могут запускаться как несколько, так и один сервис;
часть ридеров при необходимости можно вынести в отдельное независимое приложение и разместить на стороне ИС Источника (load-manager-reader). В этом случае для управления развертыванием удаленных ридеров используется специальный компонент - Deployer;
Реализованные сервисы модулита:
Manager - основной управляющий сервис, выполняющий функции:
конфигурирования удаленных ридеров;
создания Сеансов загрузки данных;
назначения сеансов для выполнения на других компонентах.
Deployer - сервис, управляющий развертыванием Reader, в том числе удаленных, развернутых на отдельной JVM по конфигурации, полученной от Manager.
Comparator - сервис, осуществляющий функцию Сверки.
Reader - сервис, обеспечивающий чтение или прием из ИС Источника, преобразование к формату avro (при необходимости) и передачу данных в Buffer. В зависимости от своих настроек может подключаться к одному из видов Источников для чтения данных в рамках Сеанса загрузки (режим pull) или ждать обращения ИС Источника (режим push).
Сервис Reader поддерживает следующие сочетания типов Источника и режимов работы:
JDBC: Pull;
REST: Pull, Push;
Folder: Pull.
FLK - сервис осуществляющий форматно-логический контроль данных перед загрузкой.
Buffer - сервис, отвечающий за запись, изменение и удаление данных во временном хранилище по запросам от других компонентов.
Uploader - сервис загрузки готовых данных из временного хранилища в Витрину.
Наиболее простой вариант размещения Загрузчика, ИС Источника и Витрины в одном ЦОД приведен на Рисунок - 2.27, стрелками обозначено основное направление передачи данных.
Данный вариант подходит для небольших Витрин данных, где важна простота настройки и экономия ресурсов.
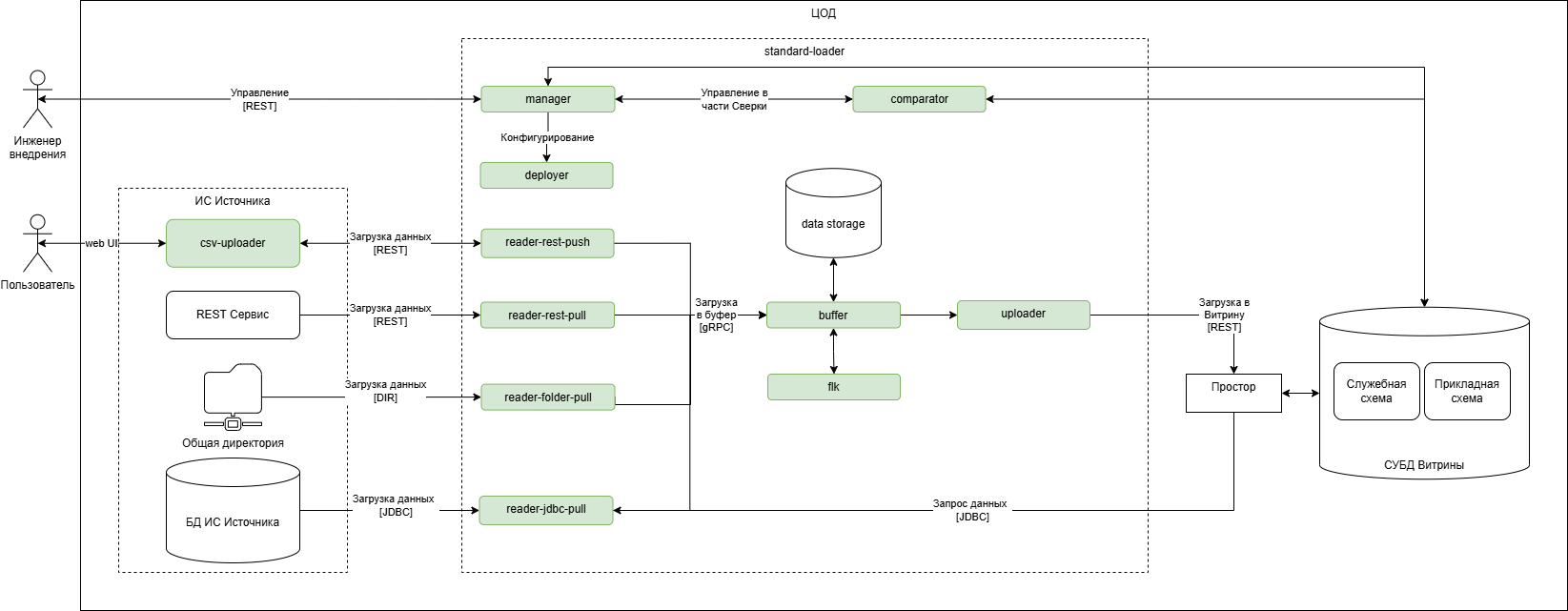
Рисунок - 1.4 Вариант развертывания стандартного загрузчика в одном ЦОД
Рисунок - 2.28 отображает вариант с размещением Витрины и ИС Источников в разных ЦОД (стрелками обозначено основное направление передачи данных). В данном случае на стороне ИС Источника разворачивается дополнительный экземпляр Стандартного загрузчика для чтения данных.
Данный вариант является основным для Витрин данных, развернутых на Гостех.
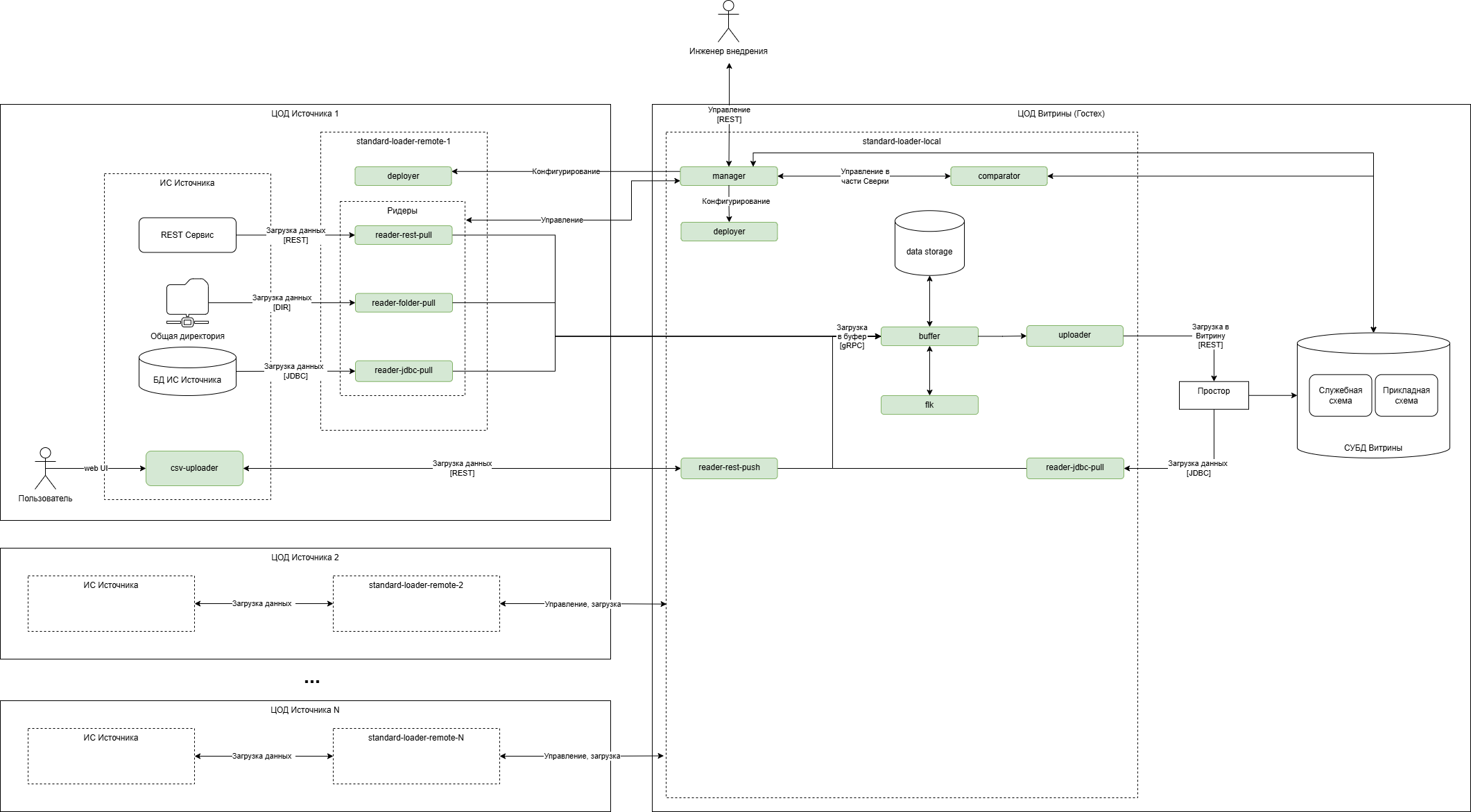
Рисунок - 1.5 Вариант развертывания стандартного загрузчика с дополнительным экземпляром
1.4. Ограничения и особенности работы
Поддерживается загрузка только плоских данных (нет вложенных объектов), без необходимости трансформации, т.е. структура данных, получаемая от Источника должна полностью соответствовать структуре данных в Витрине.
Примечание
В случае JDBC-Источника доступна трансформация данных Источника к виду, требуемому для Витрины, SQL-запросом.
Связь между основной частью Стандартного загрузчика и вынесенными Компонентами для чтения данных может быть только односторонней: Reader → основной частью Стандартного загрузчика (для возможности использования приложения в Гостех).
Функционал сверки поддерживается только для загрузки данных из ИС Источника по протоколу JDBC, при наличии доступа к полному набору данных.
Удаленные ридеры могут работать в различных часовых поясах. Для согласованности времен, при записи данных в служебную БД, временные отметки приводятся к единому часовому поясу, который можно настроить через параметр конфигурации (Раздел 2.2.7.1).
Аутентификация клиента на Компоненте чтения данных не реализована. При необходимости аутентификация должна выполняться внешними сервисами.
При переключении между загрузчиками рекомендуется удалять локальную БД CSV-Uploader для исключения недостижимых идентификаторов.
Примечание
Начиная с версии 2.6.0 в поставку стандартного загрузчика входит драйвер Prostore.
2. Метаданные стандартного загрузчика
Начиная с версии 2.6.0 хранение данных персистентности модуля осуществляется в снапшот-таблицах Prostore. Пересоздание таблиц нужного типа и миграция данных выполняется автоматически при старте модуля.
Миграции подлежат данные только таблиц, предназначенных для хранения статической информации:
information_system;
source;
pull_task;
schedule;
deployer;
reader;
config;
flk_conditions;
session_status_dictionary;
compare_task;
compare_schedule.
2.1. Объекты конфигурации компонентов
2.1.1. information_system
Назначение: хранение данных об ИС Источников.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника ИС Источника |
EGD777 |
description |
varchar |
Человекочитаемое название ИС Источника |
ЭЖД региона 777 |
2.1.2. deployer
Назначение: хранение данных о сервисах Deployer, связанных с определенной Информационной системой.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника Deployer |
deployer_egd |
|
true |
is_mnemonic |
varchar |
true |
Ссылка на мнемонику ИС Источника (Information_system), для которой разворачивается Deployer |
EGD777 |
|
enabled |
boolean |
true |
Флаг активности Deployer. При необходимости можно отключить целый Deployer без его удаления из БД. |
true |
2.1.3. reader
Назначение: хранение данных о Reader’ах, необходимых для запуска определенным Deployer.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника сервиса |
reader_jdbc_1 |
|
true |
deployer_mnemonic |
varchar |
true |
Cсылка на мнемонику Deployer, который должен развернуть сервис |
deployer_egd |
|
data_flow_type |
varchar |
Тип потока данных, с которым работает сервис |
pull |
|||
source_type |
varchar |
Тип источника, который поддерживает сервис. Заполняется только для Reader типа
|
jdbc |
|||
enabled |
boolean |
true |
Флаг активности Deployer. При необходимости можно отключить целый Deployer без его удаления из БД. |
true |
||
true |
config_mnemonic |
varchar |
true |
Ссылка на специфичную конфигурацию сервиса |
reader_config |
2.1.4. config
Назначение: хранение данных о конфигурации Reader’ов.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника конфигурации |
reader_config |
|
config |
varchar |
true |
Конфигурация компонента в формате YAML (соответствуют секции readers.[].config общего файла настройки, без элемента config |
2.2. Объекты загрузки
2.2.1. source
Назначение: хранение данных об Источниках данных.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника Источника данных |
DB_EGD |
|
description |
varchar |
Человекочитаемое название Источника данных |
База данных ЭЖД |
|||
true |
is_mnemonic |
varchar |
true |
Cсылка на мнемонику ИС Источника |
EGD777 |
|
type |
varchar |
true |
Тип источника: |
jdbc |
||
source_connect |
varchar |
true |
Параметры подключения к источнику в формате JSON |
{
"connect_jdbc": {
"url": "jdbc:postgresql://localhost:5432/postgres",
"user": "postgres",
"password": "postgres"
}
}
или
{
"connect_jdbc": {
"url": "jdbc:prostore://localhost:9090"
}
}
или
{
"connect_rest": {
"protocol": "http",
"host": "localhost",
"port": 9098,
"baseUrl": "/api/v1",
"auth": {
"basic": {
"user": "{USER.ENV}",
"password": "{PASS.ENV}"
}
}
}
}
или
{
"connect_folder": {
"_comment_input_path": "директория с файлами для загрузки",
"input_path": "/data/input",
"_comment_process_path": "директория для загружаемых файлов",
"process_path": "/data/process",
"_comment_limit_files": "максимальное число файлов, загружаемых в одном сеансе",
"limit_files": 10,
"_comment_sort": "используемая сортировка, допустимые значения: name or created",
"sort": "name",
"_comment_when_complete": "действие при успешном чтении файла, допустимые значения: move_to or delete",
"when_complete": {
"move_to": {
"path": "/data/readed_success"
}
},
"_comment_exceptionally": "действие при ошибке чтения файла, допустимые значения: move_to or delete",
"exceptionally": {
"move_to": {
"path": "/data/readed_fail"
}
}
}
}
|
2.2.2. pull_task
Назначение: хранение данных о Задания на загрузку данных в режиме Pull.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника Задания на загрузку |
upload_students |
|
action |
varchar |
true |
Тип операции |
upsert |
||
true |
source_mnemonic |
varchar |
true |
Внешний ключ, ссылка на мнемонику источника (Source) |
pgEGD777 |
|
request |
json |
true |
Запрос к источнику в формате JSON |
{ request_sql:
{query: "select * from a" }
}
или
{ request_rest:
{method: "GET",
path: "/student/:id",
body: null,
parameters: { id: "12345"}
}
}
или
пустая строка для folder reader |
||
target_type |
varchar |
true |
Тип целевой базы. Enum: application-database (загрузка данных в Витрину, в т.ч. выравнивающая загрузка), service-database (загрузка хэшей в сервисную БД для Сверки) |
application-database |
||
target_datamart |
varchar |
true |
Целевая витрина данных |
demo_dev |
||
target_table |
varchar |
true |
Целевая таблица |
students |
||
description |
varchar |
Человекочитаемое описание задачи |
Выгрузка учеников |
2.2.3. schedule
Назначение: хранение данных о Расписаниях загрузки данных.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника расписания |
upload_students_hourly |
|
description |
varchar |
Описание расписания |
Выгрузка студентов каждый час |
|||
enabled |
boolean |
true |
Флаг активности расписания |
true |
||
true |
task_mnemonic |
varchar |
true |
Cсылка на Задания на загрузку (PullTask) |
upload_students |
|
cron |
varchar |
true |
Выражение CRON для периодического запуска |
1 * * * * |
||
one_time |
boolean |
Флаг для однократного выполнения |
false |
|||
overlap-mode |
varchar |
true |
Режим обработки пересекающихся запусков
Для one_time расписаний применимо только
|
skip |
2.2.4. session
Назначение: хранение информации о созданных Сеансах загрузки.
Жизненный цикл: создается и очищается приложением через конфигурироемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор сессии. Формируется при создании записи, линейно нарастает, используется для обеспечиения FIFO в рамках таблицы |
1025 |
|
source_mnemonic |
varchar |
Мнемоника источника |
abs5 |
|||
action |
varchar |
true |
Выполняемое действие: |
upsert |
||
flk_mode |
varchar |
true |
Режим ФЛК для данного Сеанса. Заполняется менеджером при создании сеанса, используется чтобы передать в сервис FLK нужный режим |
warning |
||
component_mnemonic |
varchar |
Мнемоника сервиса, обрабатывающего Сеанс в данный момент времени |
reader_jdbc_1 |
|||
component_instance_id |
varchar (UUID) |
Идентификатор экземпляра сервиса |
019b0713-0ff5-7935-8578-37af8636e928 |
|||
target_datamart |
varchar |
true |
Целевая витрина данных |
demo_dev |
||
target_table |
varchar |
true |
Целевая таблица |
students |
||
source_connect |
json |
Параметры подключения к источнику. При |
||||
schedule_mnemonic |
varchar |
Ссылка на расписание, которое создало сеанс, при push-инициализации сеанса = null |
upload_students_hourly |
|||
file_sz |
int |
true |
Размер файла в байтах |
1532 |
||
offset |
bigint |
Смещение для чтения данных |
1 |
|||
status_code |
int |
true |
Текущий статус сессии |
300 |
||
error_code |
integer |
Код ошибки в случае неудачи |
5001 |
|||
error_message |
text |
Текстовое описание ошибки |
Ошибка подключения к источнику |
|||
create_ts |
timestamp |
true |
Время создания сессии |
2025-08-27 10:00:00 |
||
finish_ts |
timestamp |
Время завершения сессии |
2025-08-27 10:05:00 |
|||
for_system_time |
timestamp |
true |
Метка времени для удаления истории операций. Применимо только для action truncate. |
2019-12-23 15:15:14.736193 |
||
compare_session_id |
bigint |
Cсылка на идентификатор Сеанса сверки (СompareSession), в рамках которого создан Сеанс загрузки |
12345 |
|||
is_file_deleted |
boolean |
true |
Признак удаления файла из буфера,
значение по умолчанию |
true |
||
source_fields_metadata |
varchar |
Информация о типах полей в источнике данных в виде json (ключ - имя поля, значение - тип данных prostore). Данное поле не используется в REST API Данное поле не используется в REST API |
{
"name": "VARCHAR",
"code": "BIGINT"
}
|
2.2.5. event
Назначение: хранение информации о созданных Событиях загрузки.
Жизненный цикл: создается и очищается приложением через конфигурироемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор события. Генерируется на БД поэтому в составе события не передается. |
50178 |
|
code |
int |
true |
Код события |
5001 |
||
true |
session_id |
bigint |
Cсылка на идентификатор Сеанса (Session), в рамках которого произошло событие. |
upsert |
||
true |
component_mnemonic |
varchar |
true |
Cсылка на сервис (Component), создавший событие. |
reader_jdbc_1 |
|
component_instance_id |
varchar |
true |
Идентификатор экземпляра |
019b0713-0ff5-7935-8578-37af8636e928 |
||
event_ts |
timestamp |
true |
Временная метка события |
2025-08-27 10:01:00 |
||
message |
varchar |
true |
Сообщение события |
«Компонент назначен» |
||
error_code |
integer |
Код ошибки в случае неудачи |
||||
error_message |
varchar |
Дополнительные данные в формате JSON или YAML |
||||
status_code_from |
int |
Статус, в котором был сеанс до события |
100 |
|||
status_code_to |
int |
Статус, в который перешел сеанс после события |
101 |
|||
payload |
varchar |
Прикладные данные для Менеджера |
{"action":"upsert",
"datamart":"univer",
"table":"students",
"forSystemTime":null}
|
2.3. Объекты ФЛК
2.3.1. flk_conditions
Назначение: хранение проверок для целевых датамартов и таблиц.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API ФЛК.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
datamart |
varchar |
true |
Датамарт, в рамках которого применяются проверки. |
demo_dev |
|
true |
table |
varchar |
true |
Таблица, в рамках которой применяются проверки. |
students |
|
condidtions |
varchar |
true |
YAML представление условий |
fields:
birthday:
uniq: true
uniq-with:
- "code"
- "passport"
match: "(\\d{4})\\-(\\d{2})\\-(\\d{2})"
code:
in:
- "1"
- "2"
- "3"
- "4"
- "5"
- "6"
- "7"
- "8"
- "9"
- "10"
uniq: true
|
2.3.2. validation_error
Назначение: хранение информации о найденных в ходе проведения ФЛК ошибках.
Жизненный цикл: создается и очищается приложением через конфигурироемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор ошибки |
1 |
|
true |
session_id |
bigint |
true |
Ссылка на Сеанс, в рамках которого найдена ошибка |
1025 |
|
line |
integer |
true |
Номер строки в данных, где произошла ошибка |
154 |
||
field |
varchar |
true |
Имя поля с ошибкой |
age |
||
code |
varchar |
true |
Код ошибки ФЛК |
INVALID_FORMAT |
||
value |
text |
Значение, которое вызвало ошибку |
«abc» |
|||
message |
text |
true |
Описание ошибки |
Недопустимый формат числа |
2.4. Объекты сверки
2.4.1. compare_task
Назначение: хранение данных о Задания на сверку.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника задачи |
Compare1 |
|
true |
original_source_mnemonic |
varchar |
true |
Мнемоника источника мастер данных |
EGD777 |
|
true |
datamart_source_mnemonic |
varchar |
true |
Мнемоника источника витрины данных |
datamart_EGD777 |
|
original_request |
varchar |
true |
Запрос к источнику мастер данных в формате JSON для получения хешей (контрольных сумм) |
{ request_sql:
{query: "select id::VARCHAR as pk_cortege, ('x'||md5(row(name,age)::VARCHAR))::bit(64)::bigint as hash_value from foo.cat1" }
}
|
||
datamart_request |
varchar |
true |
Запрос к витрине данных в формате JSON, запрос для получения хешей (контрольных сумм) |
{ request_sql:
{query: "select id::VARCHAR as pk_cortege, ('x'||md5(row(name,age)::VARCHAR))::bit(64)::bigint as hash_value from foo.cat1" }
}
|
||
сorrection_load_request |
varchar |
true |
Запрос корректирующей загрузки для обновления и добавления записей, задается если нужна корректирующая нужна |
{ request_sql:
{query: "select a, b, c from aaa.fff where a in(: pk_keys) " }
}
|
||
сorrection_delete_request |
varchar |
false |
Запрос корректирующей загрузки для удаления записей, задается если нужна корректирующая загрузка |
{ request_sql:
{query: "select unnest(STRING_TO_ARRAY(:pk_keys,',')) pkfield " }
}
|
||
target_datamart |
varchar |
true |
Целевой датамарт для выравнивания |
|||
target_table |
varchar |
true |
Целевая таблица для выравнивания |
|||
description |
varchar |
true |
Описание сверки заполняется опционально, позволяет указать кто создал сверку и для каких целей |
Сверка важных атрибутов, создал Петров Петр Петрович 1 октября 2025 года, чтобы спать спокойно |
Примечание
Чтобы разложить наборы первичных ключей из склейки на ПГ можно пользоваться конструкцией:
select split_part(unnest(STRING_TO_ARRAY('1_2,15_17',',')),'_',1) a, split_part(unnest(STRING_TO_ARRAY('1_2,15_17',',')),'_',2) b
В Prostore данная функция отсутствует.
2.4.2. compare_schedule
Назначение: хранение данных о Расписании сверки.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника расписания сверки |
CompareScheduler1 |
|
true |
compare_task_mnemonic |
varchar |
true |
Мнемоника задачи сверки |
Compare1 |
|
cron |
varchar |
true |
CRON-выражение для расписания |
0 0 1 * * ? |
||
enabled |
boolean |
true |
Признак активности расписания |
true |
||
one_time |
boolean |
true |
Признак однократного запуска |
false |
||
description |
varchar |
Комментарий к расписанию |
Ежедневная сверка |
2.4.3. compare_session
Назначение: хранение данных о Сеансах сверки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Идентификатор сессии |
12345 |
|
true |
compare_schedule_mnemonic |
varchar |
true |
Мнемоника расписания сверки |
CompareScheduler1 |
|
create_ts |
timestamp |
true |
Дата и время начала сессии |
2025-09-30 15:00:05.000 |
||
component_mnemonic |
varchar |
true |
Мнемоника компаратора, исполняющего сверку |
comparator |
||
component_instance_id |
varchar |
true |
Идентификатор компаратора исполняющего сверку |
019b0713-0ff5-7935-8578-37af8636e928 |
||
finish_ts |
timestamp |
Дата и время окончания сессии |
2025-09-30 15:55:00.000 |
|||
status_code |
int |
true |
Статус сессии |
350 |
||
error_code |
integer |
Код ошибки в случае неудачи |
||||
error_message |
text |
Текстовое описание ошибки |
2.4.4. compare_event
Назначение: хранение данных о Событиях сверки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор события |
50178 |
|
code |
int |
true |
Код события |
5001 |
||
true |
compare_session_id |
bigint |
Cсылка на идентификатор Сеанса сверки (СompareSession), в рамках которого произошло событие. |
1234 |
||
true |
component_mnemonic |
varchar |
true |
Cсылка на сервис (Component), создавший событие. |
reader_jdbc_1 |
|
component_instance_id |
varchar |
true |
Идентификатор экземпляра |
019b0713-0ff5-7935-8578-37af8636e928 |
||
event_ts |
timestamp |
true |
Временная метка события |
2025-08-27 10:01:00 |
||
message |
varchar |
true |
Сообщение события |
«Компонент назначен» |
||
error_code |
integer |
Код ошибки в случае неудачи |
||||
error_message |
varchar |
Дополнительные данные в формате JSON или YAML |
||||
status_code_from |
int |
Статус, в котором был сеанс до события. |
200 |
|||
status_code_to |
int |
Статус, в который перешел сеанс после события. |
201 |
|||
payload |
varchar |
Прикладные данные для Менеджера |
2.4.5. compare_result
Назначение: хранение данных о Результатах сверки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
id |
bigint |
true |
Идентификатор записи |
1000 |
||
pk_cortege |
varchar |
true |
Кортеж PK прикладной записи, сериализованный в строку через разделитель |
019b0713-0ff5-7935-8578-37af8636e928 |
||
true |
compare_session_id |
bigint |
true |
Идентификатор сессии сравнения |
12345 |
|
difference_type |
int |
true |
Код различия, ENUM 1 - различные хеш суммы; 2 - данных нет в витрине; 3 - данных нет в источнике. |
1 |
||
hash_original |
bigint |
хеш мастер-записи, null в случае если difference_type = 3 (данных нет в источнике) |
3e968837-add7-4a59-9e65-293c6325b32c |
2.4.6. stable_difference
Назначение: хранение данных об Устойчивых расхождениях.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
true |
compare_session_id |
bigint |
true |
Идентификатор сессии сверки |
300 |
true |
true |
compare_session_prev_id |
bigint |
true |
Идентификатор предыдущей сессии сверки |
299 |
true |
pk_cortege |
varchar |
true |
Кортеж первичных ключей |
019b0713-0ff5-7935-8578-37af8636e928 |
|
difference_type |
int |
true |
Код различия, ENUM 1 - различные хеш суммы; 2 - данных нет в витрине; 3 - данных нет в источнике. |
1 |
||
true |
compare_task_mnemonic |
varchar |
true |
Мнемоника задания сверки |
Compare1 |
2.4.7. correction_attempt
Назначение: хранение данных о Попытках корректировки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
id |
bigint |
true |
Идентификатор попытки исправления |
12345 |
||
true |
compare_session_id |
bigint |
true |
Идентификатор Сеанса сверки |
300 |
|
true |
pk_cortege |
varchar |
true |
Кортеж первичных ключей |
019b0713-0ff5-7935-8578-37af8636e928 |
|
create_ts |
timestamp |
true |
Дата и время создания записи |
2025-09-30 15:00:05.000 |
||
true |
session_id |
bigint |
true |
Идентификатор Сеанса загрузки, в рамках которого корректировался кортеж первичных ключей |
654 |
|
true |
difference_type |
int |
true |
Тип различия |
1 |
2.4.8. correction_exception
Назначение: хранение данных об Исключениях из корректировки.
Жизненный цикл: создается приложением, предназначены для ручного разбора и удаления Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
id |
bigint |
true |
Идентификатор исключения |
4f968837-add7-4a59-9e65-293c6325b32d |
||
pk_cortege |
varchar |
true |
Кортеж первичного ключа исключения |
019b0713-0ff5-7935-8578-37af8636e928 |
||
original_source_mnemonic |
varchar |
true |
Мнемоника источника мастер данных |
EGD777 |
||
compare_session_id |
bigint |
true |
Идентификатор сеанса сверки в рамках которого выявлено исключение |
1001 |
||
true |
compare_task_mnemonic |
varchar |
true |
Мнемоника задания сверки |
Compare1 |
3. Функции стандартного загрузчика
3.1. Загрузка данных
В Таблица 2.39 приведен перечень операций, выполняемых стандартным загрузчиком с данными Витрины.
Операция |
Описание операций |
Поддерживаемые режимы для типов таблиц |
|||
|---|---|---|---|---|---|
Логическая |
proxy |
standalone |
spapshot |
||
upsert без sys_op |
Загрузка или обновление данных для переданного набора первичных ключей |
llw, stream |
llw, stream |
llw, stream |
llw, stream |
delete без sys_op |
Удаление данных по переданному набору первичных ключей |
llw, stream |
llw |
llw |
llw, stream |
truncate без sys_op |
Удаление данных, включая исторические |
llw [с for_system_time] |
llw |
llw |
llw [с for_system_time] |
modify с sys_op |
Cовмещение загрузки и логического удаления в одной операции. |
stream |
не поддерживается |
не поддерживается |
stream |
Примечание
Для управления прикладными данными в снапшот-таблицах требуется обновление загрузчика до версии 2.6.0 и выше. Все изменения данных снапшот-таблиц выполняются в операциях записи, но вне механизма дельт. Т.е. при открытой дельте данные не изолируются (запишутся/удалятся сразу, не дожидаясь закрытия дельты) и не откатываются при выполнении rollback delta.
Операции с данными могут быть инициализированы:
со стороны Витрины данных (
pull):однократно;
по расписанию.
ИС Источника (
push).
Для инициализации загрузки со стороны Стандартного загрузчика (режим pull) пользователю необходимо с помощью REST-API Стандартного загрузчика (см. раздел с API) или с
помощью прямых SQL-запросов к служебной БД (при наличии доступа) создать объекты:
Информационная система;
Источник нужного типа (source) с привязкой к нужной Информационной системе;
Задание на загрузку (pull_task) для созданного Источника;
Расписание (schedule) срабатывания для созданного Задания на загрузку.
После создания данных объектов нужно развернуть Reader с типом потока данных
pull, того же Типа источника и связанный с той же Информационной системой.Расписание (schedule) срабатывания для созданного Задания на загрузку.
Пример настроек для pull режима загрузки данных:
REST
-- Создание информационной системы
POST /api/v1/information-systems
{
"description": "Моя информационная система",
"mnemonic": "my_information_system"
}
-- Создание Источника с типом folder. JSON-объект в поле source_connect должен передаваться в виде строки,
-- для этого необходимо добавить escape символы
POST /api/v1/sources
{
"description": "Мой Источник",
"is_mnemonic": "my_information_system",
"type": "folder",
"source_connect": "\n{\n \"connect_folder\": {\n \"_comment_input_path\": \"директория с файлами для загрузки\",\n \"input_path\": \"/upload/input\",\n \"_comment_process_path\": \"директория для загружаемых файлов\",\n \"process_path\": \"/upload/process\",\n \"_comment_limit_files\": \"максимальное число файлов, загружаемых в одном сеансе\",\n \"limit_files\": 10,\n \"_comment_sort\": \"используемая сортировка, допустимые значения: name or created\",\n \"sort\": \"name\",\n \"_comment_when_complete\": \"действие при успешном чтении файла, допустимые значения: move_to or delete\",\n \"when_complete\": {\n \"move_to\": {\n \"path\": \"/upload/read_success\"\n }\n },\n \"_comment_exceptionally\": \"действие при ошибке чтения файла, допустимые значения: move_to or delete\",\n \"exceptionally\": {\n \"move_to\": {\n \"path\": \"/data/read_fail\"\n }\n }\n }\n}\n",
"mnemonic": "my_source"
}
-- Создание Задания на загрузку
POST /api/v1/pull-tasks
{
"action": "upsert",
"source_mnemonic": "my_source",
"request": "",
"target_type": "application-database",
"target_datamart": "foo",
"target_table": "cat1",
"description": "Мое задание на загрузку",
"mnemonic": "my_task"
}
-- Создание Расписания
POST /api/v1/schedules
{
"description": "Мое расписание",
"enabled": true,
"task_mnemonic": "my_task",
"cron": "*/5 * * * * *",
"one_time": true,
"overlap_mode": "skip",
"mnemonic": "my_schedule"
}
SQL
-- Создание Задания на загрузку
POST /api/v1/pull-tasks
{
"action": "upsert",
"source_mnemonic": "my_source",
"request": "",
"target_type": "application-database",
"target_datamart": "foo",
"target_table": "cat1",
"description": "Мое задание на загрузку",
"mnemonic": "my_task"
}
-- Создание Расписания
POST /api/v1/schedules
{
"description": "Мое расписание",
"enabled": true,
"task_mnemonic": "my_task",
"cron": "*/5 * * * * *",
"one_time": true,
"overlap_mode": "skip",
"mnemonic": "my_schedule"
}
-- Загрузка SQL --
-- Создание информационной системы
insert into persistence.information_system (mnemonic, description)
values ('my_information_system','Моя информационная система');
-- Создание Источника с типом folder
insert into persistence."source" (mnemonic, description, is_mnemonic, type, source_connect)
values('my_source','Мой Источник','my_information_system','folder',
'{
"connect_folder": {
"_comment_input_path": "директория с файлами для загрузки",
"input_path": "/upload/input",
"_comment_process_path": "директория для загружаемых файлов",
"process_path": "/upload/process",
"_comment_limit_files": "максимальное число файлов, загружаемых в одном сеансе",
"limit_files": 10,
"_comment_sort": "используемая сортировка, допустимые значения: name or created",
"sort": "name",
"_comment_when_complete": "действие при успешном чтении файла, допустимые значения: move_to or delete",
"when_complete": {
"move_to": {
"path": "/upload/read_success"
}
},
"_comment_exceptionally": "действие при ошибке чтения файла, допустимые значения: move_to or delete",
"exceptionally": {
"move_to": {
"path": "/data/read_fail"
}
}
}
}'
);
Для инициализации загрузки со стороны Источника (push) необходимо:
развернуть Reader с типом потока данных push;
обратиться к одному из методов API данного сервиса.
Описание объектов приведено в Раздел 2.3.6.2.
Reader может быть развернут и сконфигурирован:
средствами конфигурационного файла - для связывания c Информационной системой необходимо добавить ее мнемонику в настройках Reader в общем конфигурационном файле приложения;
Пример конфигурации:
readers:
- mnemonic: push-reader # Уникальный идентификатор в рамках manager
enabled: true
data-flow-type: push
source-type: rest
is-mnemonic: my_information_system
config:
file-size:
restriction: ${SEND_FILE_SIZE_RESTRICTION:512MB}
rest-timeout: ${REST_TIMEOUT:60s} # Таймаут обработки запроса. 0 - таймаут отключен
stream:
avro-codec: zstd # zstd/none
validation:
charset-check-enabled: true # признак выполнения проверки кодировки
valid-charsets: [ UTF-8, US-ASCII, TIS-620 ] # допустимые кодировки для механизма автоопределения
# Предельный размер отчета синхронной проверки, ограничение нужно чтобы не выйти за ограничение heap
# при формировании отчета в памяти. При срабатывании предела в лог приложения выдается предупреждение.
# Получив отчет лимитированной длины, клиент должен понимать что получил не весь отчет об ошибках. При увеличении
# этого параметра необходимо внимательно следить за утилизацией памяти приложения. Размер отчета считается в числе
# записей, значение <=0 означает неограниченный отчет, такая настройка опасна падением приложения по OutOfMemory.
report-max-length: 10_000
csv-parser:
# Символ разделителя значений
separator: ${CSV_PARSER_SEPARATOR:;}
# Символ кавычки
quote-char: ${CSV_PARSER_QUOTE_CHAR:"}
# Символ экранирования значений
escape-char: ${CSV_PARSER_ESCAPE_CHAR:'}
# Настройка интерпретации значений как null. Допустимые значения:
# - EMPTY_SEPARATORS - пустое значение между двумя разделителями, например ;;
# - EMPTY_QUOTES - пустые кавычки, например ;"";
# - BOTH - оба варианта
# - NEITHER - никогда. Пустая строка всегда определяется как пустая строка
field-as-null: ${CSV_PARSER_FIELD_AS_NULL:EMPTY_SEPARATORS}
средствами служебной Базы данных - для связывания c Информационной системой необходимо создать согласованные между собой объекты метаданных Deployer (1), Config (2) и Reader (3).
Внимание
Порядок создания данных объектов важен!
Пример создания с использованием REST-API
-- Создание Deployer
POST /api/v1/deployers
{
"is_mnemonic": "my_information_system",
"enabled": true,
"mnemonic": "my_deployer"
}
-- Создание конфигурации Reader
POST /api/v1/configs
{
"config": "\nfile-size:\n restriction: ${SEND_FILE_SIZE_RESTRICTION:512MB}\nrest-timeout: ${REST_TIMEOUT:60s} # Таймаут обработки запроса. 0 - таймаут отключен\nstream:\n avro-codec: zstd # zstd/none\nvalidation:\n charset-check-enabled: true # признак выполнения проверки кодировки\n valid-charsets: [ UTF-8, US-ASCII, TIS-620 ] # допустимые кодировки для механизма автоопределения\n# Предельный размер отчета синхронной проверки, ограничение нужно чтобы не выйти за ограничение heap\n# при формировании отчета в памяти. При срабатывании предела в лог приложения выдается предупреждение.\n# Получив отчет лимитированной длины, клиент должен понимать что получил не весь отчет об ошибках. При увеличении\n# этого параметра необходимо внимательно следить за утилизацией памяти приложения. Размер отчета считается в числе\n# записей, значение <=0 означает неограниченный отчет, такая настройка опасна падением приложения по OutOfMemory.\nreport-max-length: 10_000\ncsv-parser:\n separator: ${CSV_PARSER_SEPARATOR:;} # Символ разделителя значений\n quote-char: ${CSV_PARSER_QUOTE_CHAR:\"} # Символ кавычки\n escape-char: ${CSV_PARSER_ESCAPE_CHAR:'} # Символ экранирования значений\n # Настройка интерпретации значений как null. Допустимые значения:\n # - EMPTY_SEPARATORS - пустое значение между двумя разделителями, например ;;\n # - EMPTY_QUOTES - пустые кавычки, например ;\"\";\n # - BOTH - оба варианта\n # - NEITHER - никогда. Пустая строка всегда определяется как пустая строка\n field-as-null: ${CSV_PARSER_FIELD_AS_NULL:EMPTY_SEPARATORS}\n",
"mnemonic": "reader_folder_pull"
}
-- Создание Reader
POST /api/v1/readers
{
"deployer_mnemonic": "my_deployer",
"data_flow_type": "pull",
"source_type": "folder",
"enabled": true,
"config_mnemonic": "reader_folder_pull",
"mnemonic": "reader_folder_pull"
}
Пример создания с использованием SQL
-- Создание Deployer
insert into persistence.deployer (mnemonic, is_mnemonic, enabled)
values('my_deployer', 'my_information_system', true);
-- Создание конфигурации Reader
insert into persistence.config (mnemonic, config)
values('reader_folder_pull', '
file-size:
restriction: \${SEND_FILE_SIZE_RESTRICTION:512MB}
rest-timeout: \${REST_TIMEOUT:60s} # Таймаут обработки запроса. 0 - таймаут отключен
stream:
avro-codec: zstd # zstd/none
validation:
charset-check-enabled: true # признак выполнения проверки кодировки
valid-charsets: [ UTF-8, US-ASCII, TIS-620 ] # допустимые кодировки для механизма автоопределения
# Предельный размер отчета синхронной проверки, ограничение нужно чтобы не выйти за ограничение heap
# при формировании отчета в памяти. При срабатывании предела в лог приложения выдается предупреждение.
# Получив отчет лимитированной длины, клиент должен понимать что получил не весь отчет об ошибках. При увеличении
# этого параметра необходимо внимательно следить за утилизацией памяти приложения. Размер отчета считается в числе
# записей, значение <=0 означает неограниченный отчет, такая настройка опасна падением приложения по OutOfMemory.
report-max-length: 10_000
csv-parser:
separator: \${CSV_PARSER_SEPARATOR:;} # Символ разделителя значений
quote-char: \${CSV_PARSER_QUOTE_CHAR:"} # Символ кавычки
escape-char: \${CSV_PARSER_ESCAPE_CHAR:\'} # Символ экранирования значений
# Настройка интерпретации значений как null. Допустимые значения:
# - EMPTY_SEPARATORS - пустое значение между двумя разделителями, например ;;
# - EMPTY_QUOTES - пустые кавычки, например ;"";
# - BOTH - оба варианта
# - NEITHER - никогда. Пустая строка всегда определяется как пустая строка
field-as-null: \${CSV_PARSER_FIELD_AS_NULL:EMPTY_SEPARATORS}
');
-- Создание Reader
insert into persistence.component (mnemonic, deployer_mnemonic, data_flow_type, source_type, enabled, config_mnemonic)
values('reader_folder_pull', 'my_deployer', 'pull', 'folder', true, 'reader_folder_pull');
Варианты конфигурирования Reader описаны в Раздел 2.2.7.1.
В результате инициализации создается Сеанс загрузки.
Жизненный цикл Сеанса загрузки представлен в разделе Статусная модель сеанса загрузки.
В процессе обработки Сеанса загрузки создаются События загрузки (Event), которые позволяют детально отследить этапы загрузки данных, возникающие ошибки и замедление. Описание событий представлено в разделе События модуля.
3.1.1. Алгоритм загрузки
Рисунок - 2.29 содержит диаграмму последовательности загрузки данных.
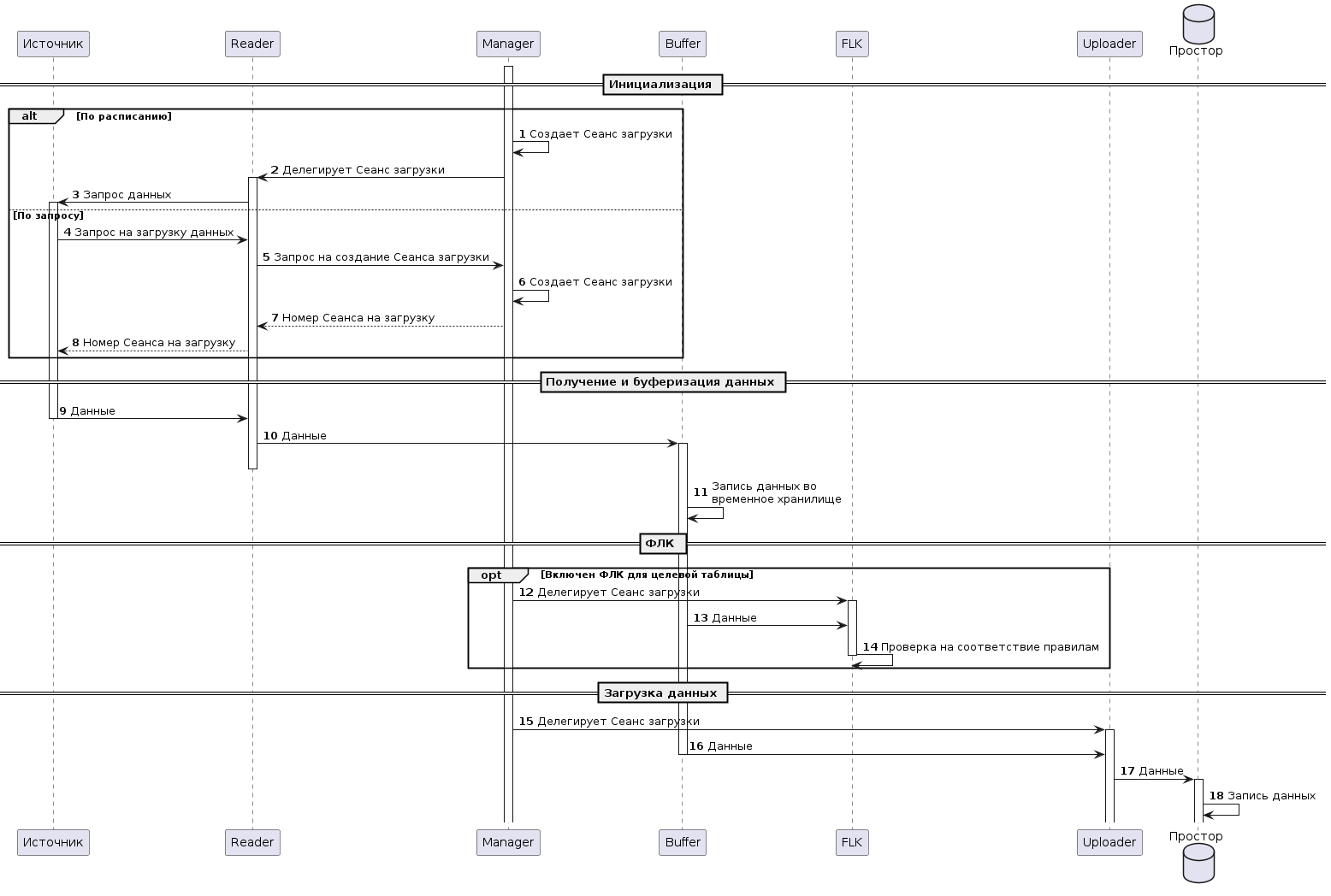
Рисунок - 3.9 Диаграмма последовательности загрузки данных
Инициализация.
а) По расписанию:
Manager создает сеанс загрузки согласно установленному Расписанию;
Manager делегирует сеанс загрузки в Reader;
Reader запрашивает данные в Источнике;
б) По запросу:
Источник данных инициирует запрос на загрузку данных к Reader;
Reader перенаправляет запрос на создание Сеанса загрузки в Manager;
Manager создает сеанс загрузки;
Manager возвращает в Reader номер сеанса загрузки и другую служебную информацию;
Reader передает номер сеанса загрузки Источнику.
Получение и буферизация данных.
а) Источник передает запрошенные данные в Reader;
б) Reader конвертирует в avro и перенаправляет полученные данные в Buffer;
в) Buffer сохраняет данные во временное хранилище.
ФЛК (опционально).
а) Manager делегирует сеанс загрузки модулю ФЛК;
б) Buffer передает данные модулю ФЛК;
в) Модуль ФЛК выполняет проверку данных на соответствие установленным правилам (подробная информация о режимах ФЛК и правилах представлена в Раздел 2.3.6.3.1.3).
Загрузка данных.
а) Manager делегирует Сеанс загрузки к Uploader;
б) Buffer передает данные Сеанса загрузки в Uploader;
в) Uploader выполняет передачу данных в Prostore;
г) Prostore осуществляет требуемые действия с данными.
3.1.2. Статусная модель сеанса загрузки
Рисунок - 2.30 содержит диаграмму статусной модели сеанса загрузки.
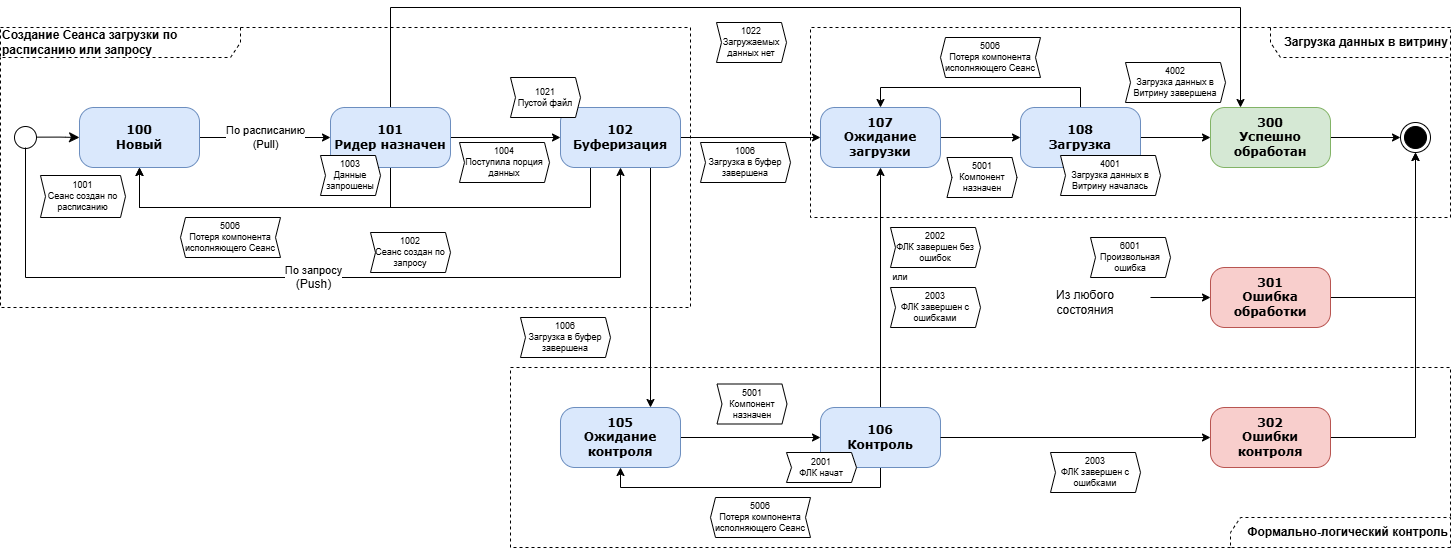
Рисунок - 3.10 Диаграмма статусной модели сеанса загрузки
Статусная модель сеанса загрузки приведена в Таблица 2.40
Код |
code (Deprecated) для совместимости |
Название |
Описание |
Финальный статус |
Действия при получении данного статуса |
|---|---|---|---|---|---|
0 |
5 |
Идентификатор запроса не обнаружен |
Технический статус, например сеанс уже удалили или запросили по ошибочному идентификатору |
Да |
Использовать действующий номер Сеанса |
100 |
100 |
Новый |
Создан новый сеанс загрузки данных, ожидается назначение сеанса для Reader, который будет выгружать данные |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
101 |
101 |
Reader назначен |
Сеанс загрузки данных назначен для Reader, ожидается получение данных от Reader |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
102 |
-1 |
Буферизация |
Reader получает данные от источника и начал передачу данных в Buffer |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
105 |
105 |
Ожидание контроля |
Переход в этот статус выполняется после окончания буферизации или трансформации, в случае, если ФЛК для данного сеанса включен. Ожидается назначение компонента ФЛК, который будет выполнять проверки поступающих в витрину данных. |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
106 |
106 |
Контроль (ФЛК) |
Выполняется ФЛК |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
107 |
0 |
Ожидание загрузки |
Ожидается назначение загружающего компонента Uploader |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
108 |
2 |
Загрузка |
Uploader назначен, выполняется загрузка данных в витрину |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
300 |
3 |
Успешно обработан |
Конечный статус успешной обработки задания (в том числе если были пропущены строки не соответствующие ФЛК) |
Да |
Если установлен режим ФЛК При наличии пропущенных при загрузке строк проанализировать и устранить выявленные недочеты в загружаемых данных или скорректировать проверки ФЛК. В других случаях действия не требуются. |
301 |
4 |
Ошибка обработки |
Ошибка обработки сеанса, файл не загружен |
Да |
Необходимо: изучить содержимое вернувшегося поля
|
302 |
7 |
Ошибка контроля |
Ошибки ФЛК, файл не загружен |
Да |
В процессе ФЛК выявлены ошибки, необходимо
запросить отчет ФЛК, обратившись к
standard-loader c компонентом ФЛК запросом
Далее проанализировать и устранить выявленные недочеты в загружаемых данных или скорректировать проверки ФЛК. |
3.1.3. Форматно-догический контроль
Для включения ФЛК пользователю необходимо:
настроить режим ФЛК в конфигурации модуля (Раздел Раздел 2.2.7.1.1):
указать flk: enabled = true;
задать manager → flk → mode;
добавить правила ФЛК (FLKCondition) для целевой Витрины и таблицы при помощи API Стандартного загрузчика (Раздел Раздел 2.3.6.5).
Правила ФЛК задаются в разрезе целевой Витрины и таблицы, для которых можно задать следующие проверки:
проверка уникальности полей:
по сочетанию атрибутов (для комплексных ключей);
по заданному атрибуту;
сравнение значения с константой;
соответствие регулярному выражению.
Для одного поля возможно создать не более одной проверки одного типа, при этом у каждого поля может быть несколько проверок разных типов.
3.1.3.1. Режимы ФЛК
Для настройки mode реализованы режимы:
skip_string- пропускаются строки не прошедшие ФЛК;warning- строки не прошедшие ФЛК выводятся в лог приложения, а также добавляются в Журнал ФЛК;skip_file- Сеанс загрузки отменяется если найдена хотя бы одна строка не прошедшая ФЛК, при этом ФЛК с формированием Журнала проводится для всего объема данных;skip_on_first_error- Сеанс загрузки отменяется если найдена хотя бы одна строка не прошедшая ФЛК, при этом ФЛК с формированием Журнала завершаются на первой встреченной ошибке;skip_string_except_last- пропускаются строки не прошедшие ФЛК по уникальности кроме последней.
3.1.3.2. Проверка уникальности по одному или по сочетанию полей
Пример запроса для проверки уникальности по группе файлов:
fields:
--проверка уникальности по одному полю
snils:
uniq: true
--проверка по сочетанию полей
id:
uniq: true
uniq-with: [type,region]
3.1.3.3. Проверка сравнения значения с константой
Проверка осуществляется для значений каждого поля в соответствии с заданным правилом, которое включает в себя проверку сравнения с константой (>, <, >=, <=, =, !=).
fields:
# условие или
type:
in: ["1","2","3"]
# условие больше и меньше
age:
">": 6
"<": 19
# условие равенства
subject:
"=": "math"
# условие не равно
mark:
'!=": null
3.1.3.4. Проверка соответствия регулярному выражению
Проверка соответствия регулярному выражению должна выполняется на основе Java Util Regexp (https://docs.oracle.com/javase/7/docs/api/java/util/regex/package-summary.html)
fields:
birthday:
# ограничение на формат даты ГГГГ-ММ-ДД: 4 цифры года, 2 цифры месяца и 2 цифры дня
match: "(\\d{4})\\-(\\d{2})\\-(\\d{2})"
3.1.4. Режим совместимости
В целях облегчения перевода процесса загрузки данных в Витрину с модуля Rest-uploader на Стандартный загрузчик реализован режим обратной совместимости.
Данный режим может быть установлен для Reader с data-flow-type: push и source-type: rest в его настройках.
Режим обратной совместимости позволяет:
возращать идентификаторы Сеансов загрузки в формате Rest-uploader (UUID) вместо integer:
readers.[].config.use-deprecated-session-id: true;возращать коды статусов Сеансов загрузки в формате Rest-uploader (Таблица 2.40): настройка
readers.[].config.use-deprecated-status-code: true.
Внимание
Представленные настройки по умолчанию отсутствуют в конфигурационном файле, для включения режима совместимости их нужно явно добавить.
3.2. Сверка данных
Стандартный загрузчик позволяет выполнять сверку части или всех данных между Источником и Витриной с точностью до конкретной записи, без остановки текущей загрузки данных и возможностью автоматической корректировкой отличающихся данных.
Примечание
Функция сверки доступна только для источников с типом JDBC
Для инициализации сверки пользователю (с помощью API Стандартного загрузчика (Раздел 2.3.6.5) или с помощью прямых запросов к служебной БД (при наличии доступа) необходимо создать следующие объекты:
Информационные системы:
Источника;
Витрины данных;
Источники (source) типа JDBC с привязкой к соответствующим Информационным системам:
для подключения к СУБД Источника;
для подключения к Витрине данных.
Задание на сверку (compare_task) со ссылками на созданные Источники.
Расписание (compare_schedule) срабатывания для созданного Задания на сверку.
После создания объектов необходимо развернуть сервисы чтения данных по аналогии с загрузкой данных (Раздел 2.3.6.3.1).
Пример настроек для сверки данных:
REST
-- Создание информационных систем
POST /api/v1/information-systems
{
"description": "Информационная система Источника",
"mnemonic": "original_information_system"
},
{
"description": "Информационная система Витрины",
"mnemonic": "datamart_information_system"
}
-- Создание Источников с типом jdbc. JSON-объект в поле source_connect должен передаваться в виде строки,
-- для этого необходимо добавить escape символы
POST /api/v1/sources
{
"description": "Мой источник",
"is_mnemonic": "original_information_system",
"type": "jdbc",
"source_connect": "\n{\n \"connect_jdbc\": {\n \"url\": \"jdbc:postgresql://postgres:5432/test1\",\n \"user\": \"dtm\",\n \"password\": \"dtm\"\n }\n}\n",
"mnemonic": "original_source"
},
{
"description": "Источник Витрина данных",
"is_mnemonic": "datamart_information_system",
"type": "jdbc",
"source_connect": "\n{\n \"connect_jdbc\": {\n \"url\": \"jdbc:prostore://prostore:9090\"\n }\n}\n",
"mnemonic": "datamart_source"
}
-- Создание Задания на сверку. JSON-объект в полях original_request, datamart_request, correction_delete_request, correction_load_request
-- должен передаваться в виде строки, для этого необходимо добавить escape символы
POST /api/v1/compare-tasks
{
"original_source_mnemonic": "original_source",
"datamart_source_mnemonic": "datamart_source",
"original_request": "\n{\n \"request_sql\": {\n \"query\": \"SELECT id::VARCHAR as pk_cortege, ('x'||md5(row(lastname,firstname,patronymic,birthdate)::VARCHAR))::bit(64)::bigint as hash_value FROM standard_loader.students_college_actual WHERE active = true\"\n }\n}\n",
"datamart_request": "\n{\n \"request_sql\": {\n \"query\": \"SELECT CAST(id AS VARCHAR) as pk_cortege, CHECK_SUM_INT64(ROW(lastname, firstname, patronymic, CAST(birthdate AS VARCHAR))) as hash_value FROM receiver.students_college WHERE active = true\"\n }\n}\n",
"target_datamart": "receiver",
"target_table": "students_college",
"correction_delete_request": "\n{\n \"request_sql\": {\n \"query\": \"SELECT id as pkfield FROM receiver.students_college WHERE id in(:pk_keys)\"\n }\n}\n",
"correction_load_request": "\n{\n \"request_sql\": {\n \"query\": \"SELECT * FROM standard_loader.students_college_actual WHERE id in(:pk_keys)\"\n }\n}\n",
"description": "Моя сверка",
"mnemonic": "my_compare"
}
-- Создание Расписания сверки
POST /api/v1/compare-schedules
{
"compare_task_mnemonic": "my_compare",
"cron": "*/5 * * * * *",
"description": "Мое расписание сверки",
"enabled": true,
"mnemonic": "my_compare_schedule",
"one_time": false
}
SQL
-- Создание информационных систем
insert into persistence.information_system (mnemonic, description)
values
('original_information_system','Информационная система Источника'),
('datamart_information_system','Информационная система Витрины');
-- Создание Источников с типом jdbc
insert into persistence."source" (mnemonic, description, is_mnemonic, type, source_connect)
values
('original_source', 'Мой источник', 'source_information_system', 'jdbc', '
{
"connect_jdbc": {
"url": "jdbc:postgresql://postgres:5432/test1",
"user": "dtm",
"password": "dtm"
}
}
'),
('datamart_source', 'Источник Витрина данных', 'datamart_information_system', 'jdbc', '
{
"jdbc": {
"url": "jdbc:prostore://prostore:9090"
}
}
');
-- Создание Задания на сверку
insert into compare_task
(mnemonic, original_source_mnemonic, datamart_source_mnemonic, original_request, datamart_request, correction_load_request, correction_delete_request, target_datamart, target_table, description)
values('my_compare', 'original_source', 'datamart_source', '
{
"sql": {
"query": "SELECT id::VARCHAR as pk_cortege, ('x'||md5(row(lastname,firstname,patronymic,birthdate)::VARCHAR))::bit(64)::bigint as hash_value FROM standard_loader.students_college_actual WHERE active = true"
}
}
','
{
"sql": {
"query": "SELECT CAST(id AS VARCHAR) as pk_cortege, CHECK_SUM_INT64(ROW(lastname, firstname, patronymic, CAST(birthdate AS VARCHAR))) as hash_value FROM receiver.students_college WHERE active = true"
}
}
', '
{
"sql": {
"query": "SELECT * FROM standard_loader.students_college_actual WHERE id in(:pk_keys)"
}
}
', '
{
"sql": {
"query": "SELECT id FROM receiver.students_college WHERE id in(:pk_keys)"
}
}
', 'receiver', 'students_college', 'Моя сверка');
-- Создание Расписания сверки
insert into compare_schedule
(mnemonic, compare_task_mnemonic, cron, enabled, one_time, description)
values('my_compare_schedule', 'my_compare', '*/5 * * * * *', true, false, 'Мое расписание сверки');
В результате инициализации по заданному расписанию создаются Сеансы сверки. Жизненный цикл Сеанса загрузки представлен в разделе Раздел 2.3.6.3.2.2.
В процессе обработки каждого Сеанса сверки создаются:
события сверки (compare_event), которые позволяют детально отследить этапы выполнения сверки. Описание событий представлено в разделе Раздел 2.3.6.4.
журнал Результатов сверки (compare_result), в котором содержатся все выявленные расхождения между данными Источника и Витрины;
журнал Устойчивых расхождений (stable_difference), в котором содержатся расхождения, сохраняющиеся на протяжении двух последовательных сеансов сверки, при условии неизменности оригинальных данных в Источнике.
Также, в случае включения автоматической корректировки, создаются:
журнал Попыток корректировки (correction_attempt), в котором содержатся первичные ключи записей и ссылки на Сеансы корректирующей загрузки, в рамках которых данные записи корректировались;
журнал Исключений из корректировки (correction_exception), в котором содержатся первичные ключи записей, которые не удалось автоматически скорректировать. Данные записи предназначены для ручного разбора и будут исключены из дальнейшей автоматической корректировки.
Описание объектов приведено в разделе Раздел 2.3.6.2.
3.2.1. Алгоритм сверки
Рисунок - 2.31 содержит диаграмму последовательности обработки Сеанса сверки.
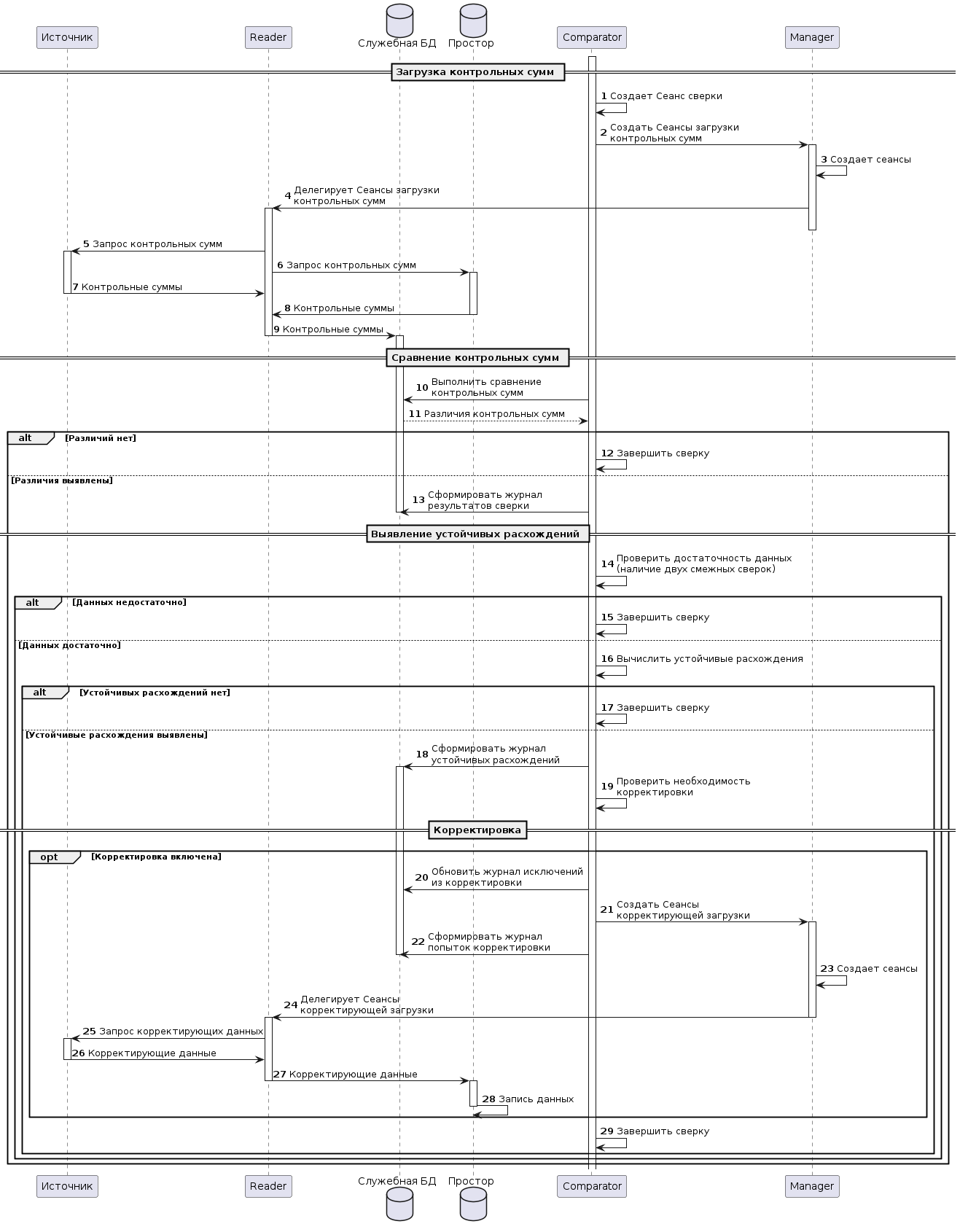
Рисунок - 3.11 Диаграмма последовательности обработки Сеанса сверки
Инициализация и загрузка контрольных сумм:
а) Comparator создает Сеанс сверки;
б) Comparator делегирует Manager создание Сеансов загрузки контрольных сумм;
в) Manager создает Сеансы загрузки из Источника и Витрины;
г) Manager делигирует выполнение Сеансов загрузки подходящим Reader’ам;
д) Reader’ы получают Сеансы загрузки и инициируют запросы к Источнику и Витрине данных для получения контрольных сумм;
е) Источник и Витрина данных вычисляют и передают контрольные суммы Reader;
ж) Reader загружает контрольные суммы в служебную базу данных (при этом используется штатный механизм загрузки).
Сравнение контрольных сумм:
а) Comparator отправляет запрос к Служебной БД на сравнение контрольных сумм;
б) Служебная БД выполняет сравнение и возвращает выявленные расхождения;
в) Если расхождения не обнаружены, Comparator завершает процесс сверки;
г) Если расхожнения обнаружены, Comparator формирует журнал Результатов сверки в Служебной БД и переходит к вычислению Устойчивых расхождений.
Вычисление устойчивых расхождений:
а) Comparator проверяет наличие данных минимум двух смежных сверок;
б) Если данных недостаточно, Comparator завершает процесс сверки;
в) Если данных достаточно, Comparator выполняет вычисление устойчивых расхождений;
г) Если Устойчивые расхождения не выявлены, Comparator завершает процесс сверки;
д) Если Устойчивые расхождения выявлены, Comparator формирует журнал Устойчивых расхождений;
е) Comparator проверяет необходимость корректировки.
Фаза корректировки данных:
а) Если корректировка включена, Comparator обновляет журнал Исключений из корректировки;
б) Comparator делегирует Manager создание Сеансов корректирующей загрузки для всех Устойчивых расхождений, за вычетом Исключений из корректировки;
в) Comparator Формирует журнал Попыток корректировки;
г) Manager создает Сеансы корректирующей загрузки;
д) Manager делегирует сеансы корректирующей загрузки подходящему Reader’у;
е) Ридер получает делегированные Сеансы корректирующей загрузки и запрашивает данные в Источнике;
ж) Источник возвращает Reader’у запрошенные данные;
з) Reader передает корректирующие данные в Витрину (при этом используется штатный механизм загрузки);
и) Витрина загружает данные в целевую таблицу.
3.2.2. Статусная модель Сеанса сверки
Сверка может включать лишь одну пару загрузок хешей и их сравнение, либо может так же включать дополнительные действия по выявлению устойчивых расхождений данных, или даже серию загрузок ключей и их сравнений.
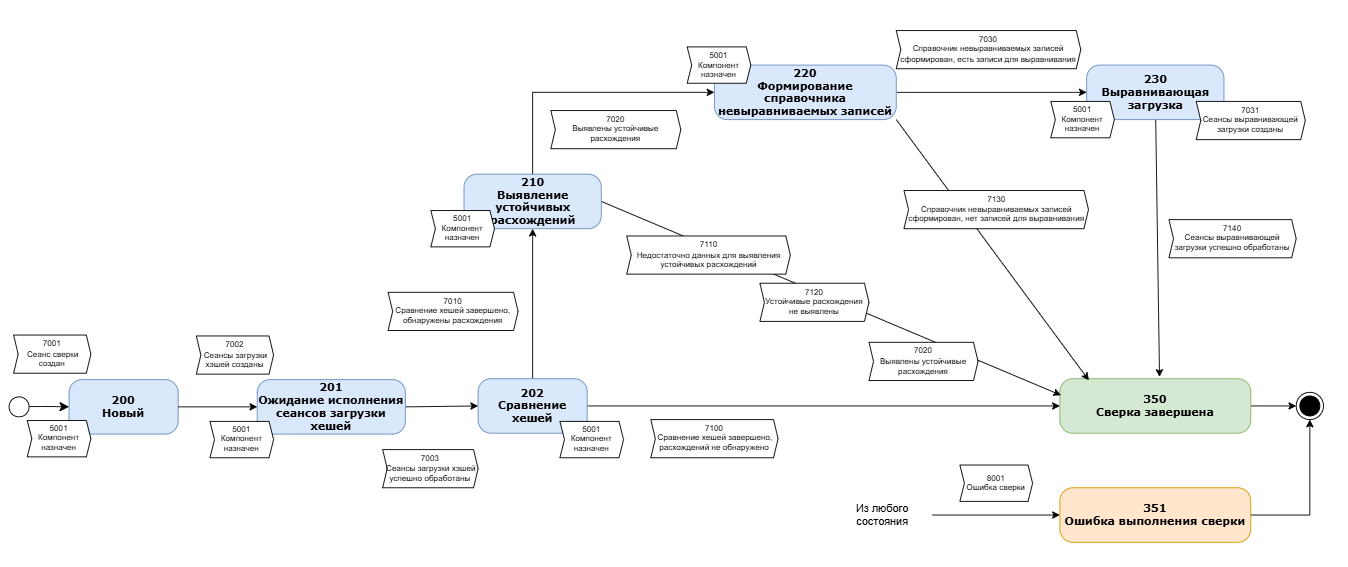
Рисунок - 3.12 Статусная модель Сеанса сверки
Статусная модель сеанса сверки приведена в Таблица 2.41
Код |
Название |
Описание |
Финальный статус |
Действия при получении данного статуса |
|---|---|---|---|---|
200 |
Новый |
Создан новый сеанс Сверки, ожидается назначение Компаратору, который будет выгружать данные |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
201 |
Ожидание исполнение сеансов загрузки хешей |
Созданы сеансы загрузки контрольных сумм, ожидается их исполнение |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
202 |
Сравнение хешей |
Контрольные суммы данных Источника и Витрины загружены в служебную БД, выполняется их сравнение |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
210 |
Выявление устойчивых расхождений |
Выявлены расхождения между данными Источника и Витрины, выполняется сравнение расхождений с предыдущим Сеансом Сверки для выявления устойчивых расхождений |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
211 |
Формирование справочника невыравниваемых записей |
Выявлены устойчивые расхождения, выполняется анализ результатов прошлой корректирующей загрузки для выявления записей не поддающихся автоматической корректировке |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
230 |
Выравнивающая загрузка |
В Задании сверки настроена автоматическая корректировка, а так же найдены записи для которых она возможна. Сеансы корректирующей загрузки созданы, ожидается их исполнение |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
350 |
Сверка завершена |
Конечный статус успешной обработки задания |
Да |
Необходимо изучить результаты проведенной Сверки:
При наличии Устойчивых расхождений и включенном механизме автоматической корректировки данных, изучить также:
|
351 |
Ошибка выполнения сверки |
Ошибка обработки сеанса, сверка не произведена |
Да |
Необходимо
|
4. События модуля
Код события |
Источник |
Сообщение |
Перевод из статуса (status_from) |
Перевод в статус (status_to) |
Прикладные данных (payload) |
Примечание |
|---|---|---|---|---|---|---|
События создания сеансов (таблица БД: event) |
||||||
1001 |
Manager |
Сеанс создан по расписанию |
100 Новый |
|||
1002 |
Reader |
Сеанс создан по запросу |
100 Новый |
session |
||
1003 |
Reader |
Данные запрошены |
||||
1004 |
Buffer |
Поступила порция данных |
100 Новый 101 Reader назначен |
102Буферизация |
chunk_num |
|
1006 |
Buffer |
Загрузка в буфер завершена |
102 Буферизация |
105 Ожидание контроля 107 Ожидание загрузки |
file_sz |
|
1007 |
Manager |
Неудачная попытка создания Сеанса. skip |
||||
1008 |
Manager |
Неудачная попытка создания Сеанса. wait |
||||
1020 |
Reader |
Обработка нового файла |
file_name |
|||
1021 |
Reader |
Пустой файл, прикладные данные отсутствуют |
file_name |
Применимо только для reader folder pull, сообщает о факте обработки пустого файла, но при этом в сеансе могут быть и другие файлы |
||
1022 |
Reader |
Загружаемых данных нет |
Reader назначен |
300 Успешно обработан |
Например по JDBC получили пустое множество |
|
События ФЛК (таблица БД: event) |
||||||
2001 |
FLK |
ФЛК начат |
||||
2002 |
FLK |
ФЛК завершен без ошибок |
106 Контроль |
107 Ожидание загрузки |
||
2003 |
FLK |
ФЛК завершен с ошибками |
106 Контроль |
107 Ожидание загрузки 302 Ошибка ФЛК |
||
2004 |
Manager |
Получен запрос на отчет ФЛК |
||||
2005 |
Manager |
Отправлен отчет ФЛК |
||||
2006 |
Manager |
Получен запрос длины очереди ФЛК |
||||
2007 |
Manager |
Отправлена длина очереди ФЛК |
||||
События загрузки (таблица БД: event) |
||||||
4001 |
Uploader |
Загрузка данных в Витрину началась |
||||
4002 |
Uploader |
Загрузка данных в Витрину завершена |
108 Загрузка |
300 Успешно обработан |
||
4003 |
Manager |
Дельта открыта |
user, инициировавший операцию |
Успешно выполненная команда |
||
4004 |
Manager |
Дельта закрыта |
user, инициировавший операцию |
Успешно выполненная команда |
||
4005 |
Manager |
Откат дельты |
user, инициировавший операцию |
Успешно выполненная команда |
||
4006 |
Manager |
Получен запрос длины очереди загрузки |
user, инициировавший операцию |
|||
4007 |
Manager |
Отправлена длина очереди загрузки |
user, инициировавший операцию |
|||
4008 |
Uploader |
Загружаемые данные разделены по дубликату первичного ключа |
offset |
|||
4009 |
Uploader |
Загружаемые данные разделены по лимиту операции Prostore |
offset |
|||
4010 |
Uploader |
Попытка подключения к Prostore |
номер попытки |
|||
Универсальные события (таблица БД: event) |
||||||
5001 |
Manager |
Компонент назначен |
В зависимости от текущего статуса |
|||
5002 |
Manager |
Отправлен запрос на удаление данных из буфера |
||||
5003 |
Buffer |
Данные удалены из буфера |
||||
5004 |
Manager |
Получен запрос статуса Сеанса |
||||
5005 |
Manager |
Отправлен ответ на запрос статуса Сеанса |
||||
5006 |
Manager |
Потеря сервиса исполняющего Сеанс |
Текущий статус |
Предыдущий статус, ожидающий назначение |
||
5007 |
Manager |
Регистрация сервиса |
||||
5008 |
Manager |
Обрыв связи с сервисом |
||||
5009 |
Manager |
Отправка сервисов для развертывания |
||||
5010 |
Deployer |
Сервис запущен |
||||
5011 |
Deployer |
Сервис остановлен |
||||
5012 |
Comparator |
Потеря компаратора, исполняющего сеанс сверки |
||||
5013 |
Comparator |
Попытка подключения к Буферу |
номер попытки |
|||
5020 |
Manager |
Расширение пачки сеансов, отправляемых на загрузку |
||||
События ошибок загрузки (таблица БД: event) |
||||||
6001 |
Любой источник |
Произвольная ошибка |
301 Ошибка обработки |
Стектрейс ошибки |
||
6002 |
Manager |
Ошибка открытия дельты |
user, инициировавший операцию |
|||
6003 |
Manager |
Ошибка закрытия дельты |
user, инициировавший операцию |
|||
6004 |
Manager |
Ошибка отката дельты |
user, инициировавший операцию |
|||
6005 |
Reader |
Недостаточно места на диске reader, рекомендуется отключение опции reader->save-read-data-> enabled |
301 Ошибка обработки |
стектрейс ошибки |
||
События сверок (таблица БД: compare_event) |
||||||
7001 |
Comparator |
Сеанс сверки создан по расписанию |
200 Новый |
|||
7002 |
Comparator |
Сеансы загрузки хэшей созданы |
200 новый |
201 Ожидание исполнения сеансов загрузки хешей |
||
7003 |
Comparator |
Сеансы загрузки хэшей успешно обработаны |
201 Ожидание исполнения сеансов загрузки хешей |
202 Сравнение хешей |
||
7100 |
Comparator |
Сравнение хешей завершено, расхождений не обнаружено |
202 Сравнение хешей |
350 Сверка завершена |
||
7010 |
Comparator |
Сравнение хешей завершено, обнаружены расхождения |
202 Сравнение хешей |
210 Выявление устойчивых расхождений |
||
7110 |
Comparator |
Недостаточно данных для выявления устойчивых расхождений |
210 Выявление устойчивых расхождений |
350 Сверка завершена |
||
7120 |
Comparator |
Устойчивые расхождения не выявлены |
210 Выявление устойчивых расхождений |
350 Сверка завершена |
||
7020 |
Comparator |
Выявлены устойчивые расхождения |
210 Выявление устойчивых расхождений |
350 Сверка завершена или 220 Формирование справочника невыравниваемых записей |
||
7130 |
Comparator |
Справочник невыравниваемых записей сформирован, нет записей для выравнивания |
220 Формирование справочника невыравниваемых записей |
350 Сверка завершена |
||
7030 |
Comparator |
Справочник невыравниваемых записей сформирован, есть записи для выравнивания |
220 Формирование справочника невыравниваемых записей |
230 Выравнивающая загрузка |
||
7031 |
Comparator |
Сеансы выравнивающей загрузки созданы |
||||
7140 |
Comparator |
Сеансы выравнивающей загрузки успешно обработаны |
230 Выравнивающая загрузка |
350 Сверка завершена |
||
7005 |
Comparator |
Пропуск создания Сеанса сверки |
||||
События ошибок сверки (таблица БД: compare_event) |
||||||
8001 |
Comparator |
Произвольная ошибка |
351 Ошибка выполнения сверки |
|||