2. Структура Компонента «Витрина данных»
2.1. Модули Компонента «Витрина данных»
Компонент имеет модульную архитектуру и построена на базе отдельных сервисов (включая разработки сторонних производителей).
Общую схему взаимосвязей сервисов можно просмотреть в разделе Архитектура Компонента «Витрина данных».
Основные составные части
Prostore (dtm-query-execution-core) - основной модуль Компонента с открытым исходным кодом, обеспечивает единый интерфейс к хранилищу разнородных данных. Определяет структуры данных, запись и чтение данных Витрины. Позволяет работать со входящими в состав хранилища СУБД одинаковым образом, используя единый синтаксис запросов SQL и единую логическую схему данных. Бэкапирование витрин выполняется средствами Prostore. Prostore включает следующие модули:
Сервис исполнения запросов - анализирует и исполняет SQL-запросы; предоставляет REST API для JDBC-драйвера. В состав сервиса входит коннектор Kafka-Jet writer, записывающий данные из брокера сообщений Kafka в PostgreSQL;
JDBC-driver - позволяет подключиться к Prostore и выполнять SQL запросы по JDBC протоколу. JDBC-driver поставляется совместно с Prostore в релизе Компонента «Витрина данных»;
Слой адаптеров - общее название модулей Компонента, которые обеспечивают подключение к СМЭВ4, как информационной системы участника взаимодействия. В зависимости от предназначения логические модули обеспечивают загрузку запросов из очереди ИС УВ в СМЭВ4 , СМЭВ3, формирование и отправку ответов в СМЭВ4, СМЭВ3, инициативное формирование уведомлений об изменении данных в Компоненте «Витрина данных», отправку уведомлений в СМЭВ4, регистрацию реплики данных ИС УВ, подписки на репликацию и поддержку реплики в актуальном состоянии. Набор модулей опционален, определяется по задачам внедрения конкретной Витрины!
Модули, входящие в состав слоя адаптеров
СМЭВ3-адаптер - обеспечивает информационное взаимодействие через единый электронный сервис единой системы межведомственного электронного взаимодействия (далее – СМЭВ).
Сервис формирования документов - предназначен для обеспечения возможности формирования документов, в формате XML и PDF, на основе предварительно подготовленных pebble-шаблонов, с возможностью добавления к сформированным документам электронной подписи.
CSV-Uploader - программный модуль Витрины данных, предназначен для загрузки и выгрузки csv-файлов со структурой Витрины и csv-шаблонов с демо-шаблонами структуры Витрины, а также просмотра Журнала операций.
BLOB-адаптер - программный модуль Витрины данных, предназначен для получения доступа из Витрины данных к BLOB-объектам ведомства (BLOB-объект - это специальный тип двоичных данных, предназначенный для хранения бинарных файлов: изображений, скан-копий документов, текстовых файлов и т.д.).
DATA-Uploader - Модуль исполнения асинхронных заданий обеспечивает обработку очереди файлов, используя следующие функциональные особенности:
обработка очереди файлов производится циклами;
очередь файлов работает в режиме упорядочения процесса по принципу «первым пришел – первым обслужен»;
каждый элемент в очереди файлов содержит UUID задания, имя витрины и таблицы, содержимое CSV-файла;
файлы в очереди могут относится к разным витринам и/или разным таблицам одной витрины.
REST-Uploader - Модуль асинхронной загрузки данных из сторонних источников реализован для обеспечения параллельной загрузки данных с независимым масштабированием REST интерфейса.
Стандартный загрузчик (Standard-loader) - Модуль управления данными (загрузка и/или удаление) в Витрине данных.
Counter-provider - Сервис генерации уникального номера (Counter-Provider) позволяет создавать неповторяющиеся уникальные порядковые номера для сквозной нумерации файлов в сервисе формирования документов Компонента «Витрина данных» конфигурации установки Стандарт.
СМЭВ QL Сервер - СМЭВ QL Сервер — приложение для конфигурирования и запуска типового API извлечения данных из хранилищ под управлением типового ПО «Витрина данных» от Минцифры (Ядро Prostore 6.1+). СМЭВ QL Сервер обладает характеристиками:
поддержка множественных источников данных Prostore;
выбор источника по условиям запроса;
защита атрибутов модели данных по их предоставлению;
автоматический параллелизм запросов к Prostore.
Агент проверок - используется для проверки качества данных, размещенных в Компоненте «Витрина данных»;
DTM-Uploader - Модуль загрузки/удаления данных.
Дополнительные сервисы
Программное обеспечение не входит в поставку Компонента:
Агент СМЭВ4 - программное обеспечение, обеспечивающее сопряжение Компонента «Витрина данных» и ИС УВ с Ядром СМЭВ4. Связь сервисов реализована через HTTP.
СУБД Postgres (Postgres Pro) - Промышленная система управления базами данных для высоконагруженных систем. Официальный сайт разработчика приложения: https://postgrespro.ru/. Совместимость СУБД Postgres (Postgres Pro) с типовым ПО «Витрина Данных» в зависимости от версии указана на портале ЕСКС.
Docker - программное обеспечение для автоматизации развёртывания и управления Компонента в виртуальных средах с поддержкой контейнеризации. Официальный сайт разработчика приложения: https://www.docker.com/.
Elasticsearch - система поиска и аналитики, позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных и сохраняет их для Graylog. Для передачи сообщений в Graylog использует Filebeat. Официальный сайт разработчика приложения: https://www.elastic.co/elasticsearch/.
Filebeat - агент на сервере для отправки различных типов оперативных данных в Elasticsearch. Официальный сайт разработчика приложения: https://www.elastic.co/elasticsearch/.
Grafana - инструмент реализован в виде панели управления и мониторинга и позволяет визуализировать системные события Компонента на базе собираемых метрик. Официальный сайт разработчика приложения: https://grafana.com/docs/.
Graylog - программное обеспечение для управления лог-файлами. Официальный сайт разработчика приложения: https://www.graylog.org/;
МongoDB - база данных Graylog. Официальный сайт разработчика приложения: https://www.mongodb.com/.
Node_exporter - процессы, обеспечивающие сбор и передачу системных метрик серверу Prometheus. Также, используется для сбора метрик модулей СМЭВ4-адаптера и CSV-uploader см. https://github.com/prometheus/node_exporter.
Prometheus - используется как система мониторинга системных ресурсов Компонента. Связь сервисов реализована через HTTP. Данные хранятся локально, в собственной TSBD базе, индексы хранятся в LevelDB. Метрики представляют собой time-series данные. Каждая метрика состоит из имени метрики, временной метки и пары «ключ – значение». Визуализация осуществляется через подключение к Grafana. Официальный сайт разработчика приложения: https://prometheus.io/.
Основные составные части
Prostore (dtm-query-execution-core) - основной модуль Компонента с открытым исходным кодом, обеспечивает единый интерфейс к хранилищу разнородных данных. Определяет структуры данных, запись и чтение данных Витрины. Позволяет работать со входящими в состав хранилища СУБД одинаковым образом, используя единый синтаксис запросов SQL и единую логическую схему данных. Prostore включает следующие модули:
Сервис исполнения запросов — анализирует и исполняет SQL-запросы; предоставляет REST API для JDBC-драйвера. В состав сервиса входит коннектор Kafka-Jet writer, записывающий данные из брокера сообщений Kafka в PostgreSQL;
JDBC-driver - позволяет подключиться к Prostore и выполнять SQL запросы по JDBC протоколу. JDBC-driver поставляется совместно с Prostore в релизе Компонента «Витрина данных»;
Слой адаптеров - общее название логических модулей Компонента, которые обеспечивают подключение к СМЭВ4, как информационной системы участника взаимодействия. В зависимости от предназначения логические модули обеспечивают загрузку запросов из очереди ИС УВ в СМЭВ4 , СМЭВ3, формирование и отправку ответов в СМЭВ4, СМЭВ3, инициативное формирование уведомлений об изменении данных в Компоненте «Витрина данных», отправку уведомлений в СМЭВ4, регистрацию реплики данных ИС УВ, подписки на репликацию и поддержку реплики в актуальном состоянии.
Модули, входящие в состав слоя адаптеров
CSV-Uploader - программный модуль Витрины данных, предназначен для загрузки и выгрузки csv-файлов со структурой Витрины и csv-шаблонов с демо-шаблонами структуры Витрины, а также просмотра Журнала операций.
DATA-Uploader - Модуль исполнения асинхронных заданий обеспечивает обработку очереди файлов, используя следующие функциональные особенности:
обработка очереди файлов производится циклами;
очередь файлов работает в режиме упорядочения процесса по принципу «первым пришел – первым обслужен»;
каждый элемент в очереди файлов содержит UUID задания, имя витрины и таблицы, содержимое CSV-файла;
файлы в очереди могут относится к разным витринам и/или разным таблицам одной витрины.
REST-Uploader - Модуль асинхронной загрузки данных из сторонних источников реализован для обеспечения параллельной загрузки данных с независимым масштабированием REST интерфейса.
Стандартный загрузчик (Standard-loader) - Модуль управления данными (загрузка и/или удаление) в Витрине данных.
Агент проверок - используется для проверки качества данных, размещенных в Компоненте «Витрина данных».
Дополнительные сервисы
Программное обеспечение не входит в поставку Компонента:
Ansible - платформа удалённого управления конфигурациями программного обеспечения, предназначенная для упрощения развёртывания Компонент «Витрина данных Лайт» через создание специальных сценариев. Официальный сайт разработчика приложения: https://www.ansible.com/.
СУБД Postgres (Postgres Pro) - Промышленная система управления базами данных для высоконагруженных систем. Официальный сайт разработчика приложения: https://postgrespro.ru/. Совместимость СУБД Postgres (Postgres Pro) с типовым ПО «Витрина Данных» в зависимости от версии указана на портале ЕСКС.
Docker - программное обеспечение для автоматизации развёртывания и управления Компонента в виртуальных средах с поддержкой контейнеризации. Контейнер позволяет производить изолированный запуск ОС с подключённой файловой системой из образа, изолированно разворачивать приложения и реализовывать микросервисы. Настройки среды хранятся в GitHub, обеспечивая единую точку управления конфигурациями. Может быть использован для для развёртывания тестового окружения Компонент «Витрина данных Лайт», без прерывания работы сервисов в продуктовой среде. Официальный сайт разработчика приложения: https://www.docker.com/.
Elasticsearch - утилита полнотекстового поиска и аналитики, которая позволяет быстро в режиме реального времени хранить, искать и анализировать большие объемы данных и сохраняет их для Graylog. Для передачи сообщений в Graylog использует Filebeat. Официальный сайт разработчика приложения: https://www.elastic.co/elasticsearch/.
Filebeat - агент на сервере для отправки различных типов оперативных данных в Elasticsearch. Официальный сайт разработчика приложения: https://www.elastic.co/elasticsearch/.
Grafana - инструмент реализован в виде панели управления и мониторинга и позволяет визуализировать системные события Компонента на базе собираемых метрик. Официальный сайт разработчика приложения: https://grafana.com/docs/.
Graylog - программное обеспечение для управления лог-файлами. Официальный сайт разработчика приложения: https://www.graylog.org/.
МongoDB - база данных Graylog. Официальный сайт разработчика приложения: https://www.mongodb.com/.
Node_exporter — процессы, обеспечивающие сбор и передачу системных метрик серверу Prometheus. Также, используется для сбора метрик СМЭВ4-адаптера и CSV-uploader см. https://github.com/prometheus/node_exporter.
Portainer - web-приложение для управления docker-контейнерами. Официальный сайт разработчика приложения: https://www.portainer.io/.
Prometheus - используется как система мониторинга системных ресурсов Компонент «Витрина данных Лайт». Связь сервисов реализована через HTTP. Данные хранятся локально, в собственной TSBD базе, индексы хранятся в LevelDB. Метрики представляют собой time-series данные. Каждая метрика состоит из имени метрики, временной метки и пары «ключ - значение». Визуализация осуществляется через подключение к Grafana. Официальный сайт разработчика приложения: https://prometheus.io/.
PostrgeSQL - база данных Prostore.
Внимание
Конкретная конфигурация Витрины данных определяется Участником взаимодействия индивидуально на этапе внедрения Компонента «Витрины данных» в составе ИТ-инфраструктуры Участника взаимодействия. Невозможно дать универсальной рекомендации для развертывания Компонента т.к. вариантов конфигурации оборудования, характера нагрузки и других факторов может быть очень много. Ниже приведены рекомендации по предварительному расчету параметров оборудования:
продумайте сценарии работы с программой необходимые для достижения ваших целей;
установите программу на тестовом стенде с рекомендуемыми техническими характеристиками (раздел Рекомендуемые технические и программные средства Руководства по установке компонента «Витрина данных»);
создайте структуру Витрины;
подготовьте тестовые данные для загрузки и определите количество загружаемых данных;
в процессе загрузки данных проведите измерение ключевых параметров нагрузки серверного оборудования;
линейно экстраполируйте эти данные на целевую систему, получив таким образом загруженность целевого оборудования;
выберете оборудование, которое будет соответствовать нагрузке для ваших задач.
2.2. Состав модулей в дистрибутиве
Состав модулей в дистрибутиве конфигурации Стандарт версии 2.5.0 приведен в таблице ниже (см. Таблица 2.1)
Наименование модуля |
Версия |
Техническое наименование |
|---|---|---|
dtm-query-execution-core |
7.5.0 |
dtm-query-execution-core:7.5.0 |
dtm-jdbc-driver |
7.5.0 |
dtm-jdbc-driver:7.5.0 |
blob-adapter |
2.5.0 |
blob-adapter:2.5.0 |
counter-provider |
2.5.0 |
counter-provider:2.5.0 |
standard-loader |
2.5.0 |
standard-loader:2.5.0 |
csv-uploader |
2.5.0 |
csv-uploader:2.5.0 |
data-uploader |
2.5.0 |
data-uploader:2.5.0 |
dtm-uploader |
2.5.0 |
dtm-uploader:2.5.0 |
printable-form-service |
2.5.0 |
printable-form-service:2.5.0 |
rest-uploader |
2.5.0 |
rest-uploader:2.5.0 |
smevql-server |
1.4.2 |
smevql-server:1.4.2 |
check-adapter |
1.0.10 |
check-adapter:1.0.10 |
smev3-адаптер |
2.5.0 |
smev3-adapter:2.5.0 |
dtm-tools |
1.23.0 |
dtm-tools:1.23.0 |
pxf-kafka-greenplum (writer) |
1.3.0 |
pxf-kafka-greenplum:1.3.0 |
kafka-jet-writer |
2.3.0 |
kafka-jet-writer:2.3.0 |
Внимание
Для переноса системных данных (сервисной БД) из ZooKeeper в Postgres-совместимые СУБД при обновлении кластера Prostore до версии 7.2 и выше используется команда ZK2PG утилиты DTM Tools.
Дистрибутив Компонента версии 2.5.0 тестировался с сервисами, приведенными в Таблица 2.2
Наименование сервиса |
Версия |
Техническое наименование |
|---|---|---|
Агент СМЭВ4 |
3.26.0 |
Агент СМЭВ4:3.26.0 |
PostgreSQL |
16.8 |
postgreSQL:16.8 |
Примечание
Дополнительные сервисы не входят в дистрибутив Компонента
Состав модулей в дистрибутиве конфигурации Лайт версии 2.5.0 приведен в таблице ниже (см. Таблица 2.3)
Наименование модулей |
Версия |
Техническое наименование |
|---|---|---|
dtm-query-execution-core |
7.5.0 |
dtm-query-execution-core:7.5.0 |
dtm-jdbc-driver |
7.5.0 |
dtm-jdbc-driver:7.5.0 |
csv-uploader |
2.5.0 |
csv-uploader:2.5.0 |
data-uploader |
2.5.0 |
data-uploader:2.5.0 |
rest-uploader |
2.5.0 |
rest-uploader:2.5.0 |
standard-loader |
2.5.0 |
standard-loader:2.5.0 |
check-adapter |
1.0.10 |
check-adapter:1.0.10 |
postgres |
16.8 |
postgres:16.8 |
portainer |
2.14.0 |
portainer:2.14.0 |
opensearch |
1.3.14 |
opensearch:1.3.14 |
mongo |
4.4 |
mongo:4.4 |
graylog |
4.3.15 |
graylog:4.3.15 |
filebeat |
7.10.2 |
filebeat:7.10.2 |
node_exporter |
1.3.1 |
node_exporter:1.3.1 |
prometheus |
2.34.0 |
prometheus:2.34.0 |
grafana |
9.5.2 |
grafana:9.5.2 |
dtm-tools |
1.23.0 |
dtm-tools:1.23.0 |
2.3. Описание модулей Витрины данных
Примечание
Описание настроек модулей, процессы запуска и остановки модуля см. в документах: «Руководстве администратора» и «Руководстве по установке».
Группа |
Техническое наименование |
Описание |
Обязательность |
Условие выбор |
|---|---|---|---|---|
Ядро Компонента «Витрина данных» |
dtm-query-execution-core |
Prostore |
Да |
Используются во всех случаях |
dtm-kafka-jet-writer |
Коннектор Prostore, отвечающий за запись данных |
|||
Модуль работы с бинарными файлами |
blob-adapter |
Адаптер чтения бинарных файлов |
Нет |
Используется при необходимости работы с бинарными файлами |
Модули загрузки данных [1] |
data-uploader |
Модуль исполнения асинхронных заданий |
Нет |
Используется для работы модуля rest-uploader. Устанавливается только совместно с rest-uploader |
dtm-uploader |
ETL-сервис загрузки данных |
Нет |
Используется как ETL для загрузки большого объема данных из внешних источников |
|
rest-uploader |
Модуль асинхронной загрузки данных из сторонних источников |
Нет |
Используется для параллельной асинхронной загрузки в витрину большого объема данных из внешних источников. Устанавливается только совместно с data-uploader |
|
standard-loader |
Модуль управления данными (загрузка и/или удаление) в Витрине данных |
Нет |
Используется для:
Источника и Витрины с точностью до конкретной записи. |
|
CМЭВ3-адаптер |
smev3-adapter |
Модуль обеспечения взаимодействия через СМЭВ3 |
Нет |
Используется для обработки запросов и ответов из очереди СМЭВ |
Модули сервиса печатных форм |
printable-form-service |
Сервис печатных форм |
Нет |
Используются для формирования документов в формате XML и PDF на основе предварительно подготовленных pebble-шаблонов, с возможностью добавления к сформированным документам электронной подписи |
counter-provider |
Сервис генерации уникального номера |
|||
rest-adapter |
Модуль генерации endPoint по swagger и формирования ответов pebble-шаблонам |
|||
СМЭВ QL Сервер |
smevql-server |
Компонент взаимодействия с витриной данных, реализу.obq её типовое API согласно внутренней спецификации СМЭВ QL |
Нет |
Для Потребителя взаимодействие со СМЭВ QL сервером равнозначно виду информационного обмена - Обмен с использованием регламентированных запросов типа «Rest-сервис» |
Агент проверок |
check-adapter |
механизм контроля качества данных, размещённых в Компоненте «Витрина данных». |
Нет |
Используется для контроля качества данных, по проверкам, заведённым в ФГИС «ЕИП НСУД» и размещённым в Компоненте «Витрина Данных» |
2.3.1. Агент проверок
Примечание
Модуль входит в состав конфигурации Стандарт и Лайт
2.3.1.1. Область применения
Агент проверок (check-адаптер) – механизм непрерывного контроля качества данных, размещённых в Компоненте «Витрина данных».
Агент проверок обеспечивает:
возможность непрерывного контроля качества данных, по проверкам, заведённым в ФГИС «ЕИП НСУД» и размещённым в Компоненте «Витрина Данных»;
возможность формирования и передачи статистики по результатам проверок в ФГИС «ЕИП НСУД»;
возможность приема из подсистемы ЕСУМД ФГИС «Моя школа» результатов сверок сопоставлений данных из витрины с опорной витриной данных;
возможность контроля качества данных о физических лицах путём сверки с данными, содержащимися в других источниках.
2.3.2. Сервис генерации уникального номера (Counter-Provider)
Примечание
Модуль входит в состав конфигурации Стандарт
2.3.2.1. Общее описание
Модуль «Сервис генерации уникального номера» позволяет создавать неповторяющиеся уникальные порядковые номера для сквозной нумерации файлов в сервисе формирования документов Компонента «Витрина данных» конфигурации Стандарт.
В модуле реализованы функции:
долговременного хранения неограниченного списка счетчиков;
атомарного изменения счетчика при параллельном использовании этой функции.
Основные функции модуля это:
Создание и долговременное хранение неограниченного списка счетчиков;
Обработка запросов на предоставление следующего номера счетчика;
Создание резервной копии и восстановление из нее (бекапирование);
Миграция счетчиков;
Публикация данных о модуле.
Новый счетчик создается при первой попытке получения следующего номера счетчика (получен GET запрос /api/{service}/number/{counter}).
Параметрами счетчика являются:
Имя сервиса - переменная
serviceв пути запроса;Имя счетчика - переменная
counterв пути запроса;Стартовое значение - задается в настройке
start-numberмодуля;Инкремент счетчика - задается в настройке
increment-gapмодуля.
2.3.3. Сервис формирования документов
Примечание
Модуль входит в состав конфигурации Стандарт
2.3.3.1. Общее описание
Сервис формирования документов предназначен для обеспечения возможности формирования документов, в формате XML и PDF, на основе предварительно подготовленных pebble-шаблонов, с возможностью добавления к сформированным документам электронной подписи.
Внимание
Максимальный размер формируемого отчета не должен превышать 2Гб!
Сервис формирования документов выполняет следующие основные функции:
Прием REST запроса на создание документа в соответствии со сцецификацией модуля;
Запрос необходимых данных для формирования документа в ядре Prostore;
Запрос номера документа в Сервисе генерации уникального номера;
Формирование документа, на основе поступившего в Витрину запроса, в формате:
XML;
PDF.
Отправка сформированных документов на подпись (опционально) в сервис Notarius;
Отправка сформированных и подписанных документов в виде ответа на пришедший запрос;
Публикация данных о модуле.
2.3.3.1.1. Процесс обработки запроса через модуль «Сервис формирования документов»
Прием REST запроса на создание документа
Запрос на создание документа приходит на эндпоинт POST /report. Форматы запроса и ответа модуля описаны в спецификации OpenAPI модуля.
После получения из ядра СМЭВ4 запрос на создание документа отправляется напрямую Агентом СМЭВ4.
Запрос данных
Pebble-движок, обрабатывая запрос по сценарию, может выполнять различные операции, в том числе и запросы к Простору. В ответ на запрос данных Prostore возвращает строки данных, в JSON.
Если результат не может быть десериализован как JSON, то работа алгоритма прерывается и в ответ на запрос возвращается ошибка 500 Internal Server Error, тело
ответа - пустое.
Запрос номера документа
Запрос номера документа осуществляется вызовом запроса GET /api/{service}/number/{counter} Сервиса генерации уникального номера.
Вызов осуществляет pebble-движок, на основе шаблона формирования извлечения данных для запрашиваемого вида документа.
В адресе запроса service задается полем counter-service.serviceName в настройках модуля, счетчик определяется pebble-шаблоном.
В ответе на запрос возвращается следующий номер счетчика, который используется для нумерации отчета.
Формирование документа
Для формирование документа используются шаблоны формирования, в зависимости от запрашиваемого типа представления: XML или PDF. При этом при формировании PDF используется промежуточная трансформация в HTML, из которого формируется финальный PDF документ.
Внимание
Следует обратить внимание, что при формировании XML-документов используется - присоединенная подпись (подпись содержится в самом XML-документе).
Для PDF-документов - отсоединенная подпись (подпись документа формируется отдельным файлом), т.е. при формировании PDF-документа сгенерируется два файла: PDF-документ и файл электронной подписи для этого документа.
Отправка сформированных документов на подпись
При необходимости подписания документа (представления кроме xml и pdf) осуществляется вызов метода POST/api/v1/sign Агента СМЭВ4.
При этом, в зависимости от представления результата:
xml_sig - присоединенная подпись:
Возвращается подписанный фрагмент файла;
Модуль пересобирает xml с учетом полученного подписанного фрагмента;
pdf_sig - присоединенная подпись:
Возвращается подписанный файл;
xml_detached_sig, pdf_sig - отсоединенная подпись:
Возвращается электронная подпись в формате p7s.
Отправка сформированных и подписанных документов
Сформированный и подписанный документ возвращается в качестве ответа на вызов метода POST /report напрямую Агенту СМЭВ4 для отправки в ядро СМЭВ4.
Отображение данных различными шрифтами
Для отображения в pdf отчете данных различными шрифтами требуется добавить шрифты в папку с pebble шаблонами и явно ссылаться на файлы шрифтов из генерируемого HTML представления.
Пример шаблона:
<html xmlns="http://www.w3.org/1999/html">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8">
<style>
@font-face {
font-family: 'DejaVu Serif';
src: url('DejaVuSerif.ttf') ;
}
@font-face {
font-family: 'MagistralC';
src: url('MagistralCRegular.otf') ;
}
* { font-family:"DejaVu Serif"; font-size: xx-large; margin:0; padding:0; text-indent:0;}
.cm { font-family:"MagistralC"; font-size: xxx-large; margin:0; padding:0; text-indent:0;}
</style>
</head>
<body>
<p >Дата рождения serif</p>
<p class="cm">Дата рождения MagistralC</p>
<p>01.01.2000</p>
<p>рус01.01.2000</p>
<p>en01.01.2000</p>
</body>
</html>
2.3.3.1.2. Общая схема взаимодействия через модуль «Сервис формирования документов»
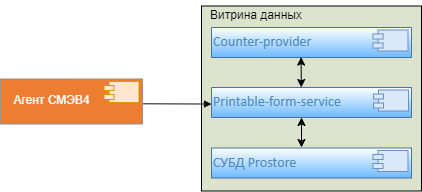
Рисунок - 2.1 Общая схема взаимодействия через «Сервис Формирования документов»
2.3.3.1.3. Примеры шаблонов
2.3.3.1.3.1. Шаблон extract_data.peb
{#формируем sql запрос в переменную passengersquery#}
{% var passengersquery %}
{% if _0 is empty %}
select * from auto_db.passenger limit 10
{% else %}
select * from auto_db.passenger limit {{ _0 }}
{% endif %}
{% endvar %}
{# выполняем sql запрос и помещаем результат выполнения в переменную rows.searchpassenger #}
{{ sql("searchpassenger", passengersquery) }}
{% var json_data %}
{
"passengers": [
{% for p in rows.searchpassenger %}
{# формируем json динамически #}
{% if loop.first %}
{% else %}
,
{% endif %}
{
"id": "{{ p.id }}",
"firstname": "{{ p.firstname }}",
"middlename": "{{ p.middlename }}",
"lastname": "{{ p.lastname }}",
"birthday": "{{ p.birthday }}"
}
{% endfor %}
]
}
{% endvar %}
{#выведем полученный json в неэкранированной форме#}
{{ json_data | raw }}
2.3.3.1.3.2. Шаблон generate_xml.peb
{#соберем xml документ#}
<passengers>
{% for p in _0.passengers %}
<passenger id="{{ p.id }}">
<firstname>{{ p.firstname }}</firstname>
<middlename>{{ p.middlename }}</middlename>
<lastname>{{ p.lastname }}</lastname>
<birthday>{{ p.birthday }}</birthday>
</passenger>
{% endfor %}
</passengers>
2.3.3.1.3.3. Шаблон generate_pdf.peb
{#соберем html документ#}
<html>
<head>
<style>
table, th, td {
border: 1px solid black;
}
</style>
</head>
<body>
<h3>Passengers</h3>
<table>
<tr>
<th>id</th>
<th>firstname</th>
<th>middlename</th>
<th>lastname</th>
<th>birthday</th>
</tr>
{% for p in _0.passengers %}
<tr>
<td>{{ p.id }}</td>
<td>{{ p.firstname }}</td>
<td>{{ p.middlename }}</td>
<td>{{ p.lastname }}</td>
<td>{{ p.birthday }}</td>
</tr>
{% endfor %}
</table>
<body>
</html>
2.3.3.1.4. REST запрос к сервису
openapi: "3.0.2"
info:
title: Printable-form-service
version: "1.0"
description: API сервиса формирования документов
servers:
- url: 'http://localhost:8081'
paths:
/report:
post:
summary: Запрос на формирование документа
tags:
- PrintableForm
operationId: postReport
requestBody:
required: true
content:
application/json:
schema:
$ref: '#/components/schemas/ReportRequest'
responses:
'200':
description: OK
content:
multipart/mixed:
schema:
$ref: '#/components/schemas/ReportResponse'
examples:
xml:
$ref: '#/components/examples/xml'
xml_detached_sig:
$ref: '#/components/examples/xml_detached_sig'
pdf:
$ref: '#/components/examples/pdf'
pdf_sig:
$ref: '#/components/examples/pdf_sig'
'400':
description: Bad Request
content:
application/json:
schema:
$ref: '#/components/schemas/ErrorMessage'
'500':
description: Internal Server Error
content:
application/json:
schema:
$ref: '#/components/schemas/ErrorMessage'
components:
schemas:
ReportRequest:
description: "Тело запроса на формирование документа"
type: object
required:
- requestId
- subRequestId
- datamartMnemonic
- certificate
- reportName
- result
- params
properties:
requestId:
description: "Идентификатор запроса"
type: string
format: uuid
subRequestId:
description: "Идентификатор подзапроса"
type: string
format: uuid
datamartMnemonic:
description: "Мнемоника Витрины данных"
type: string
certificate:
description: "Алиас сертификата"
type: string
reportName:
description: "Название документа, в виде v<версия РЗ>_<мнемоника РЗ>"
type: string
result:
type: array
description: "Массив необходимых представлений документа, подставляется из параметра doctype РЗ"
items:
type: string
enum:
- pdf
- pdf_sig
- xml
- xml_detached_sig
params:
type: array
description: "Массив параметров документа, подставляются из оставшихся параметров РЗ"
items:
type: string
example:
requestId: 9151f21f-43ae-43b4-92f3-f4af67cdf545
subRequestId: 0151f21f-43ae-43b4-92f3-f4af67cdf546
datamartMnemonic: demo_view
certificate: MIIB/AYJKoZIhvcNAQcCoIIB7TCCAekCAQExADALBgkqhkiG9w0BBwGgggHRMIIBzTCCAXigAwIBAgIJANOtR7OLdZp6MAwGCCqFAwcBAQMCBQAwNTELMAkGA1UEBhMCUlUxCzAJBgNVBAoTAlJUMRkwFwYDVQQDDBBibGFzdG9mZl9jYV90ZXN0MB4XDTI0MDYxMzEwMzAxMVoXDTM0MDYxMTEwMzAxMVowLTERMA8GA1UEAwwIaXRvbmVkZXYxCzAJBgNVBAoMAlJUMQswCQYDVQQGEwJSVTBmMB8GCCqFAwcBAQEBMBMGByqFAwICJAAGCCqFAwcBAQICA0MABEBKaYnJXmFy5LaENHYklUpwlZCKtKfT0zrl3ZWWzl617fbfFkx50mZ/TNkMC1bPKw66peyBeiyxH3Ex9GhlhRGNo2owaDAdBgNVHQ4EFgQUkpelMTqUCxHujSJLQlbOI4JXJmwwDgYDVR0PAQH/BAQDAgTwMB8GA1UdIwQYMBaAFG+jo68J8q+Yv7whvdrDSaIFNWUlMBYGA1UdJQEB/wQMMAoGCCsGAQUFBwMCMAwGCCqFAwcBAQMCBQADQQCHGQxmwPCjRNYSNXSYqB40ap5BQBEjaZ8Ortx7iaqH+N1reoNnDG/Mb99Ecm9DjKqsfOiIBpDcTMSm1RSUDYUTMQA=
reportName: v1_printable_form_address
result:
- pdf
params:
- 11
- 0000bcce-fa66-4915-b805-c06e003bc7fb
- Станислав
- Тестович
- Тестов
- 2022-03-14
- Picture_7.jpg
ReportResponse:
type: string
description: "Ответ на запрос из n частей, соответствующих запрошенным представлениям документа"
ErrorMessage:
type: object
required:
- errorMessage
properties:
errorMessage:
description: Сообщение об ошибке
type: string
examples:
xml:
value: |
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="xml_docType"
Content-Type: text/plain
xml
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="xml_content"; filename="document_1.xml"
Content-Type: application/xml
Content-Transfer-Encoding: binary
<?xml version="1.0" encoding="UTF-8" standalone="no"?><root>...</root>
--9151f21f-43ae-43b4-92f3-f4af67cdf545--
xml_detached_sig:
value: |
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="xml_detached_sig_docType"
Content-Type: text/plain
xml_detached_sig
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="xml_detached_sig_content"; filename="document_1.xml"
Content-Type: application/xml
Content-Transfer-Encoding: binary
<?xml version="1.0" encoding="UTF-8" standalone="no"?><root>...</root>
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="xml_detached_sig_detached_sign"; filename="xmlSign.p7s"
Content-Type: application/octet-stream
Content-Transfer-Encoding: binary
<file data>
--9151f21f-43ae-43b4-92f3-f4af67cdf545--
pdf:
value: |
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="pdf_docType"
Content-Type: text/plain
pdf
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="pdf_content"; filename="pdfFileName.pdf"
Content-Type: application/pdf
Content-Transfer-Encoding: binary
<file data>
--9151f21f-43ae-43b4-92f3-f4af67cdf545--
pdf_sig:
value: |
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="pdf_sig_docType"
Content-Type: text/plain
pdf_sig
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="pdf_sig_content"; filename="pdfFileName.pdf"
Content-Type: application/pdf
Content-Transfer-Encoding: binary
<file data>
--9151f21f-43ae-43b4-92f3-f4af67cdf545
Content-Disposition: form-data; name="pdf_sig_detached_sign"; filename="pdfSign.p7s"
Content-Type: application/octet-stream
Content-Transfer-Encoding: binary
<file data>
--9151f21f-43ae-43b4-92f3-f4af67cdf545--
2.3.4. СМЭВ3-адаптер
Примечание
Модуль входит в состав конфигурации Стандарт
2.3.4.1. Общее описание
Модуль «CМЭВ3-адаптер» обеспечивает информационное взаимодействие через единый электронный сервис единой системы межведомственного электронного взаимодействия (далее – СМЭВ).
С помощью CМЭВ3-адаптера Компонент «Витрина данных» выступает участником взаимодействия в роли Поставщика данных, а именно:
получает запросы из очереди СМЭВ;
отправляет ответы на запросы из очереди СМЭВ;
формирует и отправляет уведомления в СМЭВ об изменении данных в экземпляре Витрины данных.
Внимание
Отправляемые через СМЭВ3-адаптер файлы, не должны быть нулевыми (не содержать никаких данных)!
2.3.4.2. Схема взаимодействия
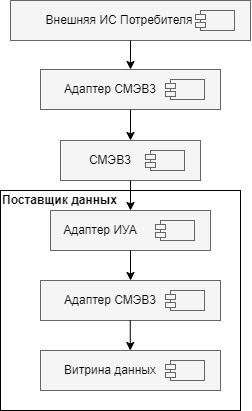
Рисунок - 2.2 Подключение к СМЭВ
Внешняя ИС выполняет запрос к СМЭВ 3 на получение данных от Поставщика данных.
Запрос через CМЭВ3-адаптер отправляется в СМЭВ.
Адаптер СМЭВ 3 на стороне Поставщика данных принимает запрос из СМЭВ и отправляет его в Витрину данных поставщика.
В Витрине Поставщика данных формируется ответ на поступивший запрос.
2.3.5. СМЭВ QL Сервер
Примечание
Модуль входит в состав конфигурации Стандарт
2.3.5.1. Назначение СМЭВ QL сервера
2.3.5.1.1. О системе
СМЭВ QL сервер - это компонент взаимодействия с витриной данных, который реализует её типовое API согласно внутренней спецификации СМЭВ QL.
Основным назначением СМЭВ QL сервер является обработка REST-запросов Потребителей на получение или изменение данных за счёт формирования оптимальных (простых) SQL-запросов к витрине.
Для Потребителя взаимодействие со СМЭВ QL сервером равнозначно виду информационного обмена - Обмен с использованием регламентированных запросов типа «Rest-сервис».
Основной принцип работы СМЭВ QL сервера заключается в следующем:
СМЭВ QL принимает на вход REST-запрос, который содержит перечень запрашиваемых ресурсов, условий выбора данных, требуемые атрибуты ответа и пр. После чего определяет данные каких объектов и из каких источников необходимо извлечь. При этом определение источников происходит на основании заранее описанных моделей данных, которые хранятся на сервере в файлах вида
model.yaml(что извлекать) иsource.yaml(откуда извлекать). Запросы также могут быть заранее сохранены в файлахquery.json(Регламентированные СМЭВ QL запросы).Далее формирует, в определенной последовательности (на основании плана выполнения запросов), столько SQL-запросов к источникам данных, сколько ресурсов было запрошено в исходном запросе от клиента. При этом запросы могут выполняться как последовательно, в случае если в запросе ресурсы имеют вложенность (иерархию) или параллельно, если ресурсы указаны на одном уровне. Это позволяет значительно упростить SQL-выражения и уменьшить сложность запроса к БД.
Обрабатывает результаты выполнения SQL-запросов по мере их поступления от источников.
Затем формирует и передает комплексный ответ клиенту.
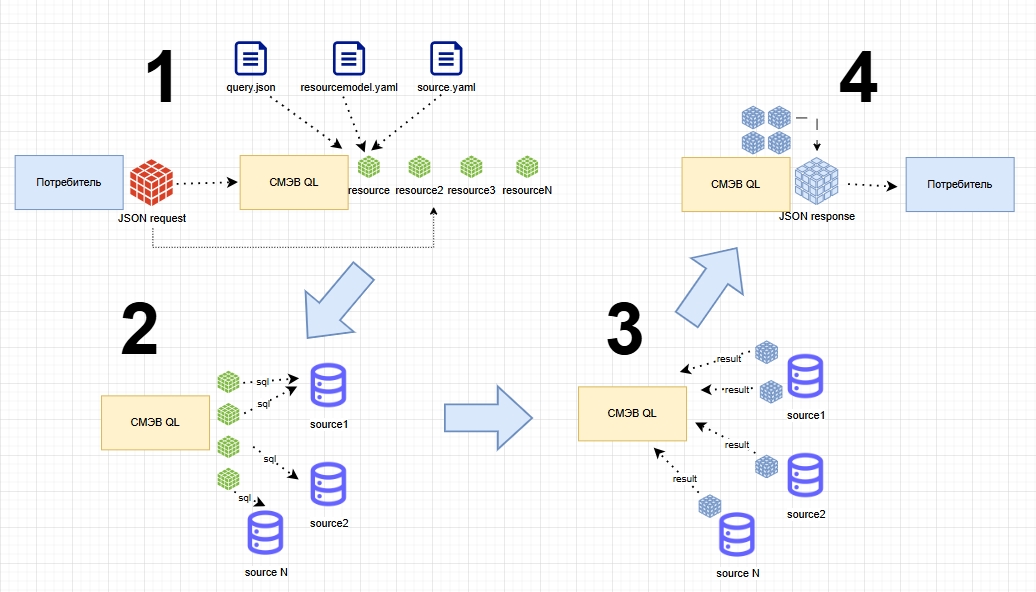
Рисунок - 2.3 Схема СМЭВ QL Сервера
2.3.5.1.2. Цели СМЭВ QL сервера
Целями создания СМЭВ QL сервера являются:
Повышение скорости предоставления ответов от витрины данных Поставщика по сравнению с типовым видом взаимодействия Агент - Витрина.
Защита витрины данных Поставщика от неоптимальных запросов.
Сокращение объёма ответов.
Сокращение количества передаваемых запросов от Потребителей.
Повышение скорости развития услуг ЕПГУ.
2.3.5.1.3. Задачи СМЭВ QL сервера
Основные задачи СМЭВ QL сервера:
Формирование API и модели данных витрины .
Приём REST-запросов от Потребителей через Агент СМЭВ4.
Формирование простых SQL-запросов к витрине.
Формирование распределенных запросов к нескольким витринам.
Формирование и передача ответа Потребителю.
Проверка и формирование цифровых подписей ответов.
Описание и исполнение при вызове модели машины состояний.
Нотификация подписчиков при изменении данных витрины.
Предоставление внешним клиентам OpenAPI для управления.
2.3.5.1.4. Место СМЭВ QL сервера в ИТ-ландшафте
СМЭВ QL сервер взаимодействует со следующими компонентами СМЭВ4:
Агент СМЭВ4.
Сервис исполнения запросов ядра витрины данных.
Сервер криптографии (Notarius).
Сервис формирования документов.
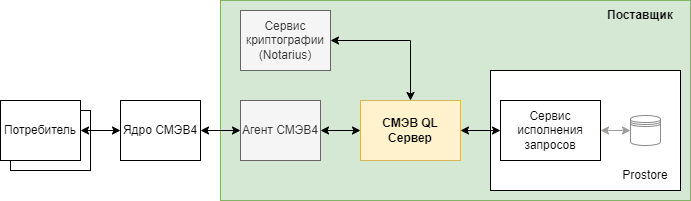
Рисунок - 2.4 Схема взаимодействия СМЭВ QL Сервера с компонентами СМЭВ4
2.3.5.1.5. Язык и синтаксис
2.3.5.1.5.1. Моделирование
Для моделирования документного слоя данных в спецификации выбран язык разметки YAML.
2.3.5.1.5.2. Запросы и ответы
Для написания запросов, а также в качестве сериализатора ответов, спецификация определяет использование JSON.
2.3.5.1.6. Типизация
Фактические типы данных наследуют типы данных JSON (включая NULL):
string;
number;
object;
array;
boolean;
null.
2.3.5.1.6.1. Типы данных в модели и приведение типов
В описании модели допускается указание фактического типа данных атрибута ресурса вторым элементом массива type. Указание является опциональным, по умолчанию подразумевается неограниченный STRING.
Пример из описания модели:
fields:
id:
name: Идентификатор записи
type:
- number
- SHORT
length: 20
nullable: not NULL
key: PRIMARY
В качестве второго уточняющего типа следует применять типы НСУД:
STRING;
DOUBLE;
FLOAT;
BOOLEAN;
BYTE (не поддерживается Компонентом «Витрина данных»);
BINARY;
BIG_DECIMAL (не поддерживается Компонентом «Витрина данных»);
LONG;
INTEGER;
SHORT;
DATE;
TIME;
TIMESTAMP.
2.3.5.1.7. Моделирование данных
Модели данных описываются в формате YAML в папке проекта models согласно спецификации СМЭВ QL.
Структура базовой модели приведена в Раздел 2.3.5.2.3.
Структура базовой модели приведена в Раздел 2.3.5.2.4.
2.3.5.1.8. Метрики
Для обеспечения возможности сбора информации о работе СМЭВ QL Сервера реализован набор метрик, обеспечивающий формирование показателей:
время исполнения входящих запросов;
количество успешных / не успешных выполнений входящих запросов;
время исполнения исходящих запросов или обращений к СПО;
количество успешных / не успешных выполнений исходящих запросов или обращений к СПО.
2.3.5.2. Основные понятия СМЭВ QL
2.3.5.2.1. Ресурс
Ресурс представляет собой объект (таблица) хранилища Поставщика, данные которого могут быть получены или изменены Потребителем при запросе к СМЭВ QL серверу. Ресурс описывается в модели данных СМЭВ QL, а так же указывается в исходном запросе от Потребителя.
Пример определения ресурса в модели данных СМЭВ-QL:
resources:
- tickets: *base_model
name: Билеты
fields: "id", "passengerid", "tripid", "number", "bycard", "price", "sold"
Пример определения ресурса в запросе Потребителя:
"query": {
"tickets": {
"conditions": {
"number": 1
},
"attributes": ["id", "passengerid", "tripid", "number", "bycard", "price", "sold"]
}
2.3.5.2.2. Машина состояний
СМЭВ QL содержит встроенную машину состояний (или стэйт-машина) для изменения ресурсов витрин данных. Одновременно с этим стейт машина может в качестве подтверждения перехода состояния использовать внешний источник.
Карта состояний и переходов машины состояний описывается в виде YAML-файла state.yaml располагаемого в папке
states/<имя-модели>/<х.х версия модели> инстанса СМЭВ QL сервера.
2.3.5.2.3. Базовая модель данных
Базовая модель данных - это описание типовых элементов и форматов данных, которые могут использоваться (наследоваться) при создании пользовательских моделей (Раздел 2.3.5.2.4).
Базовая модель не описывает схему данных витрины и не участвует в логике СМЭВ QL при обработке запросов. Хранится в файловой
системе СМЭВ QL сервера по пути: models>base>1.0>model.yaml
2.3.5.2.4. Модель данных
Модель данных (пользовательская модель данных, custom-модель) - описание метаданных витрины, извлекаемых при обращении потребителя к СМЭВ QL серверу. Содержит названия ресурсов (таблиц), атрибутов ресурсов, связи с другими моделями, ограничения на использование ресурсов для потребителей, а так же источники хранения ресурсов.
Каждая модель представляет из себя YAML-файл, которая может ссылаться на базовую модель данных (Раздел 2.3.5.2.3) для оптимизации описания.
Хранится в виде YAML-файла model.yaml по пути: models>custom>1.0>model.yaml инстанса СМЭВ QL сервера.
2.3.5.2.5. Распределённый запрос
При обращении Потребителя к СМЭВ QL серверу, исполнение запроса (получение данных по запросу) может происходить с участием одного или нескольких источников (поставщиков данных). В случае если для получения данных шло обращение к двум и более источникам, то такой запрос называется распределенным.
Описание источников получения данных задается на уровне Раздел 2.3.5.2.4 в блоке extract:.
При этом Потребитель всегда обращается к одному СМЭВ QL, от которого ожидает получение всех данных о всех источников.
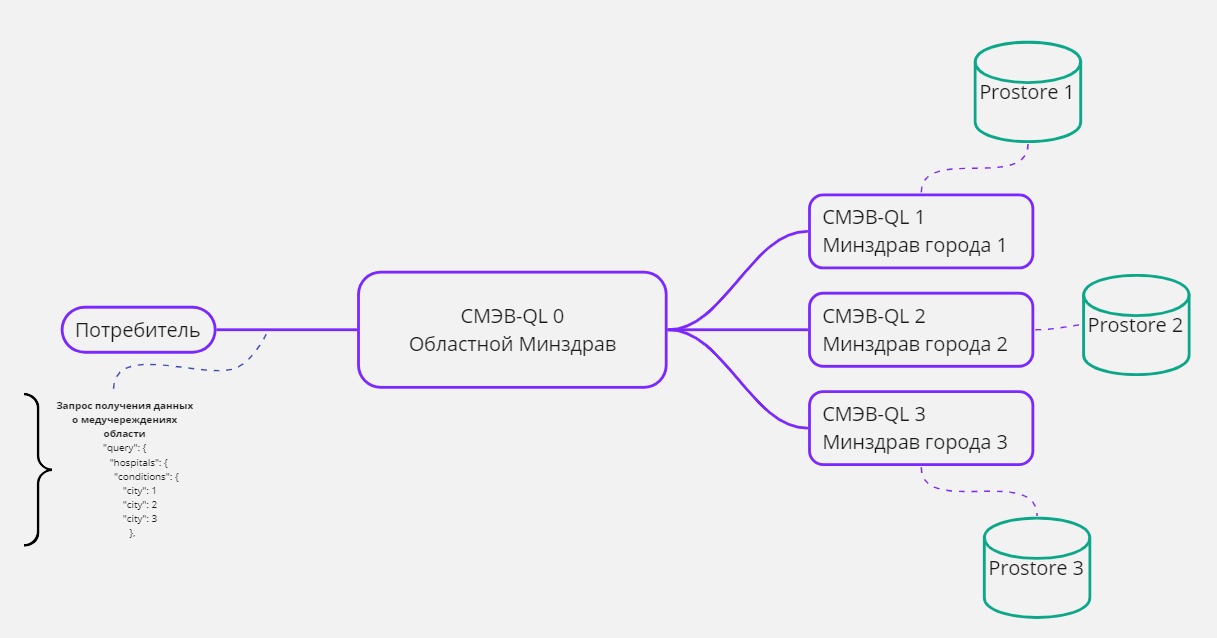
Рисунок - 2.5 Пример схемы распределенного запроса
2.3.5.2.6. Регламентированный СМЭВ QL запрос
Регламентированный СМЭВ QL запрос (СМЭВ QL РЗ) - это сохраненный в файловой системе сервера шаблон запроса к СМЭВ QL серверу с обозначенными местами для вставки параметров.
При вызове СМЭВ QL РЗ в шаблон подставляются переданные параметры и выполняется стандартный запрос к данным.
2.3.5.3. Функции СМЭВ QL Сервера
2.3.5.3.1. Администрирование и конфигурирование
2.3.5.3.1.1. Создание СМЭВ QL Сервера
Данная функция позволяет создать рабочий экземпляр СМЭВ QL сервера с помощью команды, выполняемой утилитой.
Параметр |
Описание |
Где задается |
|---|---|---|
app name |
Имя создаваемого экземпляра СМЭВ QL сервера. Параметр является обязательным для заполнения |
в командной строке:
|
Предварительное состояние:
Развернут дистрибутив СМЭВ QL сервер.
Запущена консоль утилиты для работы со СМЭВ QL.
Результирующее состояние:
Создана первичная структура папок и файлов СМЭВ QL.
Ошибка выполнения команды.
Сценарий выполнения
Администратор сервера в консоли вводит команду создания нового экземпляра СМЭВ QL с указанием имени:
java -jar smevql-server-all.jar new <new-app-name>
Система выполняет создание экземпляра СМЭВ QL сервера с заданным именем:
если во время выполнения команды возникла ошибка, то сценарий завершается с результирующим состоянием 2;
иначе, команда выполнена успешно, создана первичная структура папок и файлов, завершение сценария с результирующим состоянием 1.
Результирующее состояние:
СМЭВ QL сервер успешно запущен, создана первичная структура папок и файлов.
Ошибка выполнения команды.
Первичная структура папок и файлов
Название |
Тип |
Описание |
Уровень вложенности |
|---|---|---|---|
application.yaml |
yaml-file |
Файл с описанием настроек СМЭВ QL сервер (Раздел 2.2.6.1) |
1 |
credentials.yaml |
yaml-file |
Файл с описанием представления СМЭВ QL сервер (Раздел 2.2.6.1) |
1 |
logs |
folder |
Папка с лог-файлами СМЭВ-QL сервер |
1 |
models |
folder |
Папка с описанием моделей данных |
1 |
readme.md |
md-file |
read-файл в формате markdown, описывает основные функции СМЭВ QL |
1 |
smevql.jar |
jar-file |
Jar-файл с кодом СМЭВ QL |
1 |
sources |
folder |
Папка с описанием источников данных |
1 |
states |
folder |
Папка с описанием машин состояний |
1 |
openapi.yaml |
yaml-file |
Файл с первичной спецификацией Open API СМЭВ QL |
1 |
Название |
Тип |
Описание |
Уровень вложенности |
|---|---|---|---|
base |
folder |
Папка с версиями описания структуры базовой модели данных |
2 |
current (symlink) |
symlink |
Ссылка на папку модели по умолчанию |
3 |
1.0 |
folder |
Папка с версией базовой модели данных |
3 |
model |
yaml-file |
Файл с описанием базовой модели данных |
4 |
Содержимое папки sources
По умолчанию, пустая папка, содержимое заполняется в процессе создания моделей источников.
Название |
Тип |
Описание |
Уровень вложенности |
|---|---|---|---|
environment_name.log |
log-file |
Лог-файл СМЭВ QL |
2 |
Содержимое папки states: по умолчанию, пустая папка, содержимое заполняется в процессе создания машин-состояний.
2.3.5.3.1.2. Конфигурирование СМЭВ-QL сервер
Пример конфигурации файла application.yml для СМЭВ QL сервера см. в разделе Раздел 2.2.6.1 Руководства администратора.
2.3.5.3.1.3. Запуск, остановка, перезапуск приложения СМЭВ QL сервер
Примеры команд и их описание приведено в Раздел 3.6.1.
2.3.5.3.1.4. OpenAPI СМЭВ-QL
2.3.5.3.1.4.1. Общее описание
Обращение потребителей данных или иных внешних систем к СМЭВ QL серверу происходит путем вызова REST-методов. Первичная спецификация Open API СМЭВ QL сервера поставляется в исходном дистрибутиве, которая в дальнейшем может обновляться на основании модели данных и модели машины-состояний.
Спецификация Open API хранится в файловой системе СМЭВ QL сервера по пути: smevql/openapi.yaml
2.3.5.3.1.4.2. Описание спецификации
Группа |
Метод |
Назначение |
|---|---|---|
States (работа с моделью машины состояний) |
GET/states |
Получить описание всех моделей машин состояний |
GET/states/{model} |
Получить описание конкретной модели машины состояний |
|
POST/states/{model}/{event} |
Изменить статус (состояние) машины состояний. Спецификация метода строится на основании заполненной карты машины состояний. |
|
Model (работа с моделью данных) |
GET/model |
Получить описание всех моделей данных |
GET/model/{model} |
Получить описание конкретной модели данных |
|
GET/model/{model}/{version} |
Получить описание конкретной версии модели данных |
|
GET/server/indexes/required |
Получить список рекомендованных для создания индексов полей.
Строится на используемых в связях моделей (connections) и блоке
|
|
Sources (работа с моделью источников) |
GET/sources |
Получить описание модели источников |
Data (работа с данными поставщика) |
GET/data/{token} |
Запрос данных в асинхронном режиме по токену |
GET/certificaties |
Получить сертификат для проверки цифровой подписи на стороне клиента |
|
POST/data |
Ключевой запрос получения данных поставщика. Схема запроса по умолчанию не содержит объекты витрины, а обновляется отдельной процедурой на основании заполненной модели данных (Раздел 2.3.5.2.4). |
|
POST/regulated-query |
Выполнение СМЭВ QL РЗ |
|
Push (управление рассылками на изменения данных витрины) |
POST/push/consumer/create |
Зарегистрировать нового потребителя на получение уведомлений при изменении данных витрины |
GET/push/consumer |
Получить список всех потребителей, зарегистрированных на получение уведомлений при изменении данных витрины |
|
GET/push/consumer/resources/{agent_target} |
Получить список ресурсов, изменения которых, отслеживает заданный потребитель |
|
GET/push/consumer/agent_targets/{resource} |
Получить список потребителей, которые отслеживают изменения заданного ресурса |
|
POST/push/consumer/delete/resource |
Удалить отслеживание изменений конкретного ресурса для заданного потребителя |
|
POST/push/consumer/delete/ |
Удалить отслеживание изменений всех ресурсов для заданного потребителя |
|
Прочие служебные методы |
GET/ping |
Проверить сетевую доступность СМЭВ QL сервер |
События |
POST/in-event |
Зарегистрировать новое событие |
Подробное описание всех эндпоинтов в Раздел 2.2.6.5.
2.3.5.3.1.4.3. Обновление OpenAPI на основании изменений модели данных
Для применения изменений модели (или применения новой модели) данных в Open API СМЭВ QL необходимо выполнить следующие действия:
Администратор системы выполняет команду запуска или перезапуска приложения (подробнее см. Раздел 3.6.1)
Система определяет актуальную версию модели (старшая по номеру или версия явно указанная в
current symlink).Система дополняет схемы OpenAPI атрибутами из модели.
Система сохраняет обновленные данные Open API только в оперативной памяти (локальный файл
openapi.yamlне меняется).
Для того, чтобы изменения модели были применены в локальном файле openapi.yaml, необходимо выполнить следующие действия:
Администратор системы выполняет в консоли команду генерации OpenAPI:
yaml g openapi model
Система определяет актуальную версию модели данных (старшая по номеру или версия явно указанная в
current symlink)Система дополняет схемы OpenAPI атрибутами из модели.
Система обновляет локальный файл
openapi.yaml.
2.3.5.3.1.5. Регистрация OpenAPI СМЭВ QL в СМЭВ4
Для возможности использования СМЭВ QL сервер, необходимо выполнить регистрацию OpenAPI в СМЭВ4 через ЕИП НСУД и выдать права доступа потребителям на выполнение запросов вида - Обмен с использованием регламентированных запросов типа «Rest-сервис» в системе ЛК УВ.
При регистрации REST-интерфейса потребуется указать следующие ключевые атрибуты:
Мнемоника информационной системы поставщика данных.
Указание префикса url REST-интерфейса СМЭВ QL сервер, например:
smevql/api/v1Приложить заполненный файл openapi.yaml (Раздел 2.3.5.3.1.4)
2.3.5.3.2. Работа с моделями
2.3.5.3.2.1. Создание базовой модели
2.3.5.3.2.1.1. Общее описание
Базовая модель данных автоматически генерируется при создании СМЭВ QL и не должна редактироваться вручную.
Базовая модель служит для унификации описания типов данных и позволяет значительно сокращать описание атрибутов ресурса в модели данных (Модель данных).
Пример описания атрибута в модели данных без применения базовой модели:
id:
name: Идентификатор
type:
- string
- STRING
length: 0
nullable: null
key: NONE
Пример описания атрибута в модели данных c применением базовой модели:
id: *ds
2.3.5.3.2.1.2. Общий сценарий выполнения
Администратор сервера в консоли вводит команду создания экземпляра СМЭВ QL сервер:
java -jar smevql-server-all.jar new (new-app-name)
Система создаёт новую версию папки и файла базовой модели с заполненным содержимым -
model.yaml
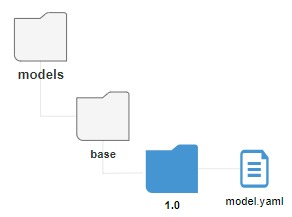
Рисунок - 2.6 Создание базовой модели
2.3.5.3.2.1.3. Описание базовой модели
default_string: &ds
name: Строка
type:
- string
- STRING
length: 0
nullable: NULL
key: NONE
source: NONE
default_number: &dn
name: Число
type:
- integer
- INTEGER
length: 0
nullable: NULL
key: NONE
source: NONE
primary_key: &pk
name: Ключ
type:
- string
- STRING
length: 0
nullable: NULL
key: PRIMAY
source: NONE
static_value: &sv
name: Статическое значение
type:
- string
- STRING
length: 0
nullable: NULL
key: NONE
source: STATIC //зарезервированное значение
default_value: Значение //статическое значение без извлечения
env_value: &ev
name: Значение из окружения
type:
- string
- STRING
length: 0
nullable: NULL
key: NONE
source: ENV //зарезервированное значение
default_value: Значение если нет переменной окружения
env_key: ключ_переменной_окружения
base_model: &base_model
default_fields: &default_fields
2.3.5.3.2.2. Генерация модели данных
2.3.5.3.2.2.1. Общее описание
Данная функция позволяет сгенерировать новую пустую Модель данных.
2.3.5.3.2.2.2. Сценарий выполнения
Администратор сервера в консоли вводит команду генерации новой модели данных с обязательным указанием названия модели:
./smevql g model <model-name>
Система проверяет, что имя модели уникально:
если имя модели не уникально (модель данных с таким именем уже существует в файловой системе СМЭВ QL), то Система выводит соответствующее сообщение об ошибке.
иначе, имя модели уникально, переход к выполнению следующего шага.
Система создаёт папку с указанным наименованием и файл
model.yamlДалее Администратор сервера вручную заполняет модель данных требуемыми значениями.
Для генерации модели на основе другого источника, использующего подключение к ПО Prostore используется команда:
./smevql schema-gen -ds <source-name> -d <model-name>
Без указания параметра -ds будет формироваться модель на основе источника с названием Prostore.
2.3.5.3.2.2.3. Описание модели данных
Элемент модели |
Описание |
Пример |
|---|---|---|
|
Название модели данных |
smevql |
version: |
Номер версии модели данных |
1.0 |
resources: |
Описание ресурсов модели данных |
|
<resource_name>: *base_model |
Техническое название ресурса. Должно быть уникальным в рамках модели данных, т.к. используется для указания связей |
|
name: |
Название ресурса на русском языке |
|
description: |
Дополнительное описание ресурса, обычно указывается его бизнес-смысл |
|
fields: |
Список полей ресурса. Для каждого поля указывается:
|
|
connections: |
Описание связей между ресурсами по заданным ключам |
|
belongs_to: |
||
has_many: |
||
conditions: |
Описание ограничений на использование полей в пользовательских запросах |
|
allowed: |
Если заполнено, то поиск разрешен только по этим полям и полям с ключами |
|
denied: |
Если заполнено, то поиск запрещен по этим ключам |
|
always: |
Наличие условий в блоке |
|
extract: |
Указание источника данных для ресурса |
|
name: |
Название (мнемоника) источника данных |
|
table: |
Название таблицы в схеме БД источника |
|
conditions: |
Массив условий применения источника на основании значений полученных в запросе атрибутов. Все условия внутри источника действуют через логическое И (AND). Если запрос подходит под два и более источников , то данные извлекаются и объединяются из всех подходящих. |
|
fetch: |
Режим получения данных (синхронный или асинхронный). Содержит атрибуты:
|
2.3.5.3.2.2.4. Пример блока fields
fields:
<<: *default_fields
first_name: *ds
last_name:
<<: *ds
guard: [last_name]
snils:
<<: *ds
guard: [last_name first_name snils]
2.3.5.3.2.2.5. Пример блока resources
resources:
# slots — техническое название модели, по нему производятся все связи
- slots: *base_model
# значение name — название модели на русском языке
name: Слоты
# description - дополнительное описание ресурса
description: таблица с указанием доступных и занятых временных интервалов
# fields — список полей модели
fields:
# список полей может включать перечень полей из default_fields
<<: *default_fields
# поля по-умолчанию наследуются от ds (default_string) из базовой модели
id: *ds
resource_id: *ds
# у поля может быть переопределен source (по-умолчанию у каждого поля источник всей модели)
type: *ds
source:
field: tag_type
age: *ds
source:
field: tag_age
visitTime: *ds
duration: *ds
status: *ds
create_ts: *ds
update_ts: *ds
update_ts: *ds
2.3.5.3.2.2.6. Пример блока connections
connections:
belongs_to:
- resource:
primary_key: [ id ]
foreign_key: [ resource_id ]
has_many:
- book:
primary_key: [ id ]
foreign_key: [ slot_id ]
- unaccessible_period:
primary_key: [ resource_id, type ]
foreign_key: [ resource_id, type ]
2.3.5.3.2.2.7. Пример блока conditions
conditions:
allowed: [id, name] # если заполнено, то поиск разрешен только по этим полям и полям с ключами
denied: [snils] # если заполнено, то поиск запрещен по этим ключам
always: # наличие условий в блоке always должно ко всем запросам ресурса добавлять эти условия, если указаны в запросе, то перетирать
- region: ["=", "77"]
- blocked: ["=", true]
2.3.5.3.2.2.8. Пример блока extract
extract:
source:
- name: prostore
table: misdm.slots
2.3.5.3.2.2.9. Пример блока conditions
extract:
source:
- name: prostore1
table: misdm.slots
conditions:
# попадание в промежуток
- range:
field: age
from: 0
to: 2
- eq:
field: color
not: "blue"
- name: prostore2
table: misdm.39slots
conditions:
# ограничения по (не)равенству
- eq:
field: resource_id
is: 1
- name: prostore3
table: misdm.39slots
conditions:
# ограничения по наличию в источнике
- eq:
field: snils
extract:
source: redis
table: default_table
key: resource_hashed_id
algorithm: md5
# select count(*) > 0 from offices.offices where resource_hashed_id = ?
# параметр: md5(snils)
is: true
- name: prostore_default
table: misdm.39slots
conditions:
- fallback: true
2.3.5.3.2.2.10. Пример блока fetch
fetch:
policy: sync | async | async_on_timeout # на данном этапе реализуется только sync
store_timeout: PT15M
timeout: PT20S
retries: 2
2.3.5.3.2.3. Автоматическое создание модели данных на основе схемы БД
2.3.5.3.2.3.1. Общее описание
Данная функция позволяет создать заполненную модель данных, на основе схемы БД подключенного источника (на основе схемы данных Prostore).
2.3.5.3.2.3.2. Сценарий выполнения
Предварительные условия:
Настроена модель источника данных типа Prostore (Раздел 2.3.5.3.3.1).
Создана базовая модель (Раздел 2.3.5.3.2.1).
Ход выполнения:
Администратор сервера в консоли вводит команду генерации модели данных на основе схемы БД источника Prostore:
./smevql schema-gen -d <название схемы>
Система проверят наличие базовой модели:
если базовая модель отсутствует, то Система выводит соответствующее сообщение об ошибке;
иначе, переход к выполнению следующего шага;
Система проверяет, что имя модели (название схемы) уникально:
если имя модели не уникально (модель данных с таким именем уже существует в файловой системе СМЭВ QL), то Система выводит соответствующее сообщение об ошибке;
иначе, имя модели уникально, переход к выполнению следующего шага;
Система создаёт папку с указанным наименованием и файл
model.yaml;Система заполняет содержимое файла model.yaml по следующим правилам:
Каждая таблица в схеме БД - это отдельный ресурс в модели данных;
Каждый атрибут таблицы в схеме БД - это элемент блока
fields:соответствующего ресурса;Блок
connections:- пустой;Блок
conditions:- пустой;Блок
extract:-name: <название источника из модели источника>,table: <название таблицы из БД>.
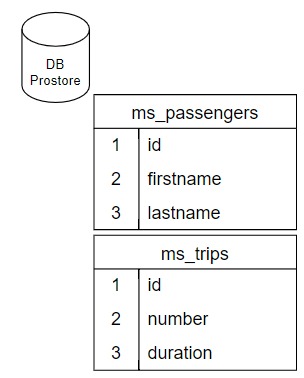
Рисунок - 2.7 Схема в БД Prostore
Сгенерированная модель данных:
- name: smevql
version: 1.0
data:
resources:
- passenger: *base_model
name: Пассажиры
description: Логическая таблица "Пассажиры"
fields:
id:
!!merge <<: *ds
name: ИД пассажира
firstname:
!!merge <<: *ds
name: Имя
lastname:
!!merge <<: *ds
name: Фамилия
connections:
extract:
source:
- name: prostore
table: ms.passengers
- trip: *base_model
name: Рейс
description: Логическая таблица "Рейс"
fields:
!!merge <<: *default_fields
id:
!!merge <<: *ds
name: ИД рейса
number:
!!merge <<: *pkn
name: Номер
duration:
!!merge <<: *dtm
name: В пути
connections:
extract:
source:
- name: prostore
table: ms.trips
2.3.5.3.2.4. Создание новой версии модели данных
2.3.5.3.2.4.1. Общее описание
СМЭВ QL может одновременно использовать несколько разных моделей данных с разным наименованием.
Однако в рамках одного наименования модели (папки с названием модели) может быть активна только одна версия модели данных.
Версия модели данных характеризуется уникальным номером и наличием отдельной папки с данным номером в файловой системе СМЭВ QL.
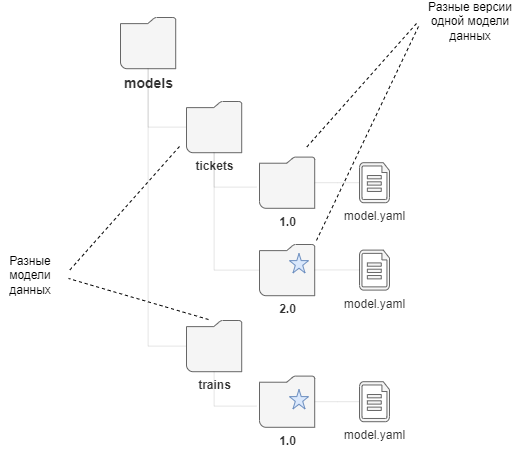
Рисунок - 2.8 Разные версии одной модели
Модели данных считываются, валидируются и загружаются в память из папки models при запуске СМЭВ QL сервера.
По умолчанию используется версия model, на которую ссылается symlink current, при его отсутствии по умолчанию считается старшая по номеру версия.
Модели и версии, начинающиеся с подчеркивания (_) НЕ загружаются, они находятся в стадии проектирования.
2.3.5.3.2.4.2. Сценарий выполнения
Предварительные условия:
Подготовлена модель данных с учетом всех необходимых изменений (файл
model.yaml).
Ход выполнения:
Администратор системы выбирает папку с названием модели данных для которой необходимо создать новую версию.
Администратор системы вручную создает новую папку с указанием нового номера версии (обычно это новое целочисленное значение).
Администратор системы вручную переносит, заранее подготовленный файл model.yaml, в папку с новым номером версии.
2.3.5.3.2.5. Проверка валидности модели данных
2.3.5.3.2.5.1. Общее описание
Валидация модели данных выполняется при каждом запуске СМЭВ QL сервер и в случае возникновения ошибок, приложение не будет запущено.
Помимо этого можно предварительно проверить корректность заполнения модели данных путем вызова специальной команды в консоли приложения.
2.3.5.3.2.5.2. Сценарий выполнения
Администратор сервера в консоли вводит команду проверки валидности модели данных:
если требуется проверить все модели данных, то выполняется команда:
./smevql test model all.если требуется проверить конкретные модели, то выполняется команда (с указанием через запятую) наименований моделей:
./smevql test model <model-name1>, <model-name2>.
Система проверяет корректность заполнения моделей данных и в случае наличия ошибок выведет соответствующее сообщение.
2.3.5.3.2.6. Маппинг типов данных СМЭВ QL - Prostore
Логический тип Prostore |
Описание |
Логический тип СМЭВ QL |
Тип базовой модели СМЭВ QL |
|---|---|---|---|
BOOLEAN |
Логический (булевый) тип |
BOOLEAN |
&db, &pkb |
CHAR (n) |
Строка ограниченной длины (n символов). Размерность строки обязательна |
STRING |
&ds, &dst, &denv, &pks |
VARCHAR [(n)] |
Строка ограниченной длины (n символов). Размерность строки опциональна |
STRING |
&ds, &dst, &denv, &pks |
LINK |
Строка неограниченной длины. Предназначена для ссылочных полей |
BINARY |
&dbn, &pkbn |
UUID |
Строка ограниченной длины (36 символов) |
STRING |
&ds, &dst, &denv, &pks |
INTEGER, алиас — INT32 |
Целое число фиксированной длины со знаком в
диапазоне от |
SHORT, INTEGER |
&pksh, &dsh, &pkn, &dn |
BIGINT, алиас — INT64 |
Целое число фиксированной длины со знаком в диапазоне -263, 263-1 [2] |
LONG |
&pkl, &dl |
DOUBLE |
Число с плавающей запятой с двойной точностью |
DOUBLE |
&dd, &pkd |
FLOAT |
Число с плавающей запятой |
FLOAT |
&pkf, &df |
DATE |
Дата (без времени суток) |
DATE |
&ddt, &pkdt |
TIME, TIME (p) |
Время (без даты). Значение p задает точность отображаемого времени. Возможные значения: от 0 (секунды) до 6 (микросекунды). Значение по умолчанию - 6. Количество микросекунд находится в диапазоне от 0 до 86399999999 |
TIME |
&dtm, &pktm |
TIMESTAMP, TIMESTAMP (p) |
Дата и время. Значение p задает точность отображаемого времени. Возможные значения: от 0 (секунды) до 6 (микросекунды). Значение по умолчанию - 6 |
TIMESTAMP |
&pkts, &dts |
Не поддерживается в Prostore |
BYTE |
&dbt, &pkbt |
|
Не поддерживается в Prostore |
BIG_DECIMAL |
&dbd, &pkbd |
2.3.5.3.3. Работа с источниками данных
2.3.5.3.3.1. Создание модели источников
2.3.5.3.3.1.1. Общее описание
Данная функция позволяет добавлять новую версию описания модели источников данных СМЭВ-QL.
В качестве источников данных для СМЭВ-QL сервер могут выступать:
REST-интерфейс витрины данных (Prostore);
Другой СМЭВ-QL сервер
Модель источников данных СМЭВ-QL хранится в файловой системе СМЭВ-QL сервера по пути: sources/custom/1.0/source.yaml
Допускается описание всех источников в рамках одной модели.
2.3.5.3.3.1.2. Общий сценарий выполнения
Администратор сервера в консоли вводит команду генерации новой пустой модели источника:
./smevql g source <source-name>
Система создаёт новую версию папки и файла модели источника с пустыми значениями -
source.yamlАдминистратор сервера открывает на редактирование файл модели источника
source.yamlи заполняет параметры необходимыми значениями.
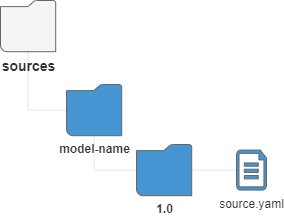
Рисунок - 2.9 Создание модели источников данных
2.3.5.3.3.1.3. Структура source.yaml
Описание источника данных в формате YAML имеет следующую структуру:
Параметр |
Описание |
|---|---|
Наименование |
Наименование источника данных. В рамках файла При этом именем источника в моделях данных считается часть без учета данного постфикса. То есть источник |
type |
Тип интеграционного взаимодействия. На текущий момент поддерживается только rest |
version |
|
adapter |
Тип источника данных. Может принимать значения:
|
protocol |
Указание протокола передачи данных. На текущий момент поддерживается только HTTP |
host |
Хост-адрес сервера источника данных |
port |
Порт сервера источника данных |
path |
Путь для вызова REST-метода API источника данных |
template |
Шаблон передачи REST-запроса к источнику |
payload-path |
|
headers |
Значения по умолчанию для заголовка REST-запроса к источнику |
threads-count |
|
connection-timeout |
Тайм-аут ожидания ответа от сервера источника |
Описание источника данных в формате YAML имеет следующую структуру:
prostore_source:
type: rest
version: 1.0
adapter: prostore
protocol: http
host: localhost
port: 9090
path: api/v1/datamarts/query?format=json
template: '{ "query": "%{request}", "queryId": "%{request_id}" }'
payload-path: result
headers:
- accept: application/json
- content-type: application/json
threads-count: 10
connection-timeout: 0
smevql_server_source:
type: rest
version: 1.0
adapter: smevql
protocol: https
host: localhost
port: 9091
path: api/query?format=json
template: '{ "query": "%{request}" }'
payload-path: result
headers:
- accept: application/json
- content-type: application/json
2.3.5.3.3.2. Создание новой версии модели источников
2.3.5.3.3.2.1. Общее описание
СМЭВ QL может одновременно использовать несколько разных моделей источников с разным наименованием.
Однако в рамках одного наименования модели (папки с названием модели) может быть активна только одна версия модели источников.
Версия модели источников характеризуется уникальным номером и наличием отдельной папки с данным номером в файловой системе СМЭВ QL.
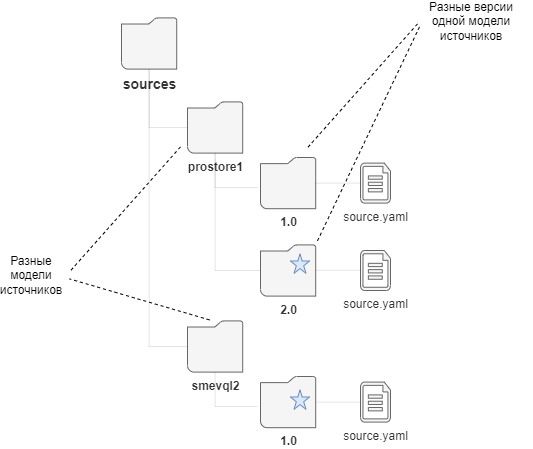
Рисунок - 2.10 Создание новой версии модели источников данных
Источники данных считываются, валидируются и загружаются в память из папки sources при запуске СМЭВ QL сервера.
По-умолчанию используется версия источника, на которую ссылается symlink current, при его отсутствии по-умолчанию считается старшая версия.
Источники и версии, начинающиеся с подчеркивания (_) НЕ загружаются, они находятся в стадии проектирования.
2.3.5.3.3.2.2. Сценарий выполнения
Предварительные условия:
Подготовлена модель источников с учетом всех необходимых изменений (файл
source.yaml).
Ход выполнения:
Администратор системы выбирает папку с названием модели источников для которой необходимо создать новую версию.
Администратор системы вручную создает новую папку с указанием нового номера версии (обычно это новое целочисленное значение).
Администратор системы вручную переносит, заранее подготовленный файл source.yaml, в папку с новым номером версии.
2.3.5.3.3.3. Проверка доступности источников
2.3.5.3.3.3.1. Общее описание
Данная функция позволяет проверить сетевую доступность источников, указанных в модели.
2.3.5.3.3.3.2. Сценарий выполнения
Администратор сервера в консоли вводит команду проверки доступности источников:
если требуется проверить все источники, то выполняется команда:
./smevql test source all;если требуется проверить конкретный источник, то выполняется команда (с указанием через запятую) наименований источников:
./smevql test source <source-name1>, <source-name2>;
Система отправляет проверочный запрос к источнику и дожидается ответа в течении заданного таймаута:
если ответ не пришёл в течение заданного таймаута, то Система выводит соответствующее сообщение об ошибке, источник не доступен;
иначе, ответ пришёл в течение заданного таймаута, источник доступен.
2.3.5.3.4. Работа с картами машин состояний
2.3.5.3.4.1. Создание карты машины-состояний
2.3.5.3.4.1.1. Общее описание
Карта машины состояний (Раздел 2.3.5.2.2) описывает её статусы и события, при вызове которых осуществляется переход к следующему статусу.
Карта состояний и переходов машины состояний описывается в виде YAML-файла state.yaml и хранится в файловой системе СМЭВ QL сервера по
пути: states><model-name>><version number>>state.yaml
2.3.5.3.4.1.2. Структура карты машины состояний
Элемент |
Описание |
|---|---|
model: |
Название карты машины состояний (модели стэйт-машины) |
states: |
Массив возможных состояний |
state: |
Название состояния |
attributes: |
Массив атрибутов, описывающих состояние. Каждый атрибут имеет следующие свойства:
|
initial: |
Признак исходного состояния. Может быть определен только у одного состояния в рамках одной карты машины состояний. |
delete: |
Признак, указывающий что при переходе в данное состояние будут удалены данные в соответствии с условиями
переданными в блоке При этом значения атрибутов для такого статуса не применимы, они игнорируются. Состояние с данным признаком считается конечным и не может использоваться в разделе from при описании событий. |
static: |
Признак, при установке которого не меняется статус, а только передается указанная в описании события часть запроса в блоке confirm к связанному источнику. |
events: |
Список событий изменения состояний. Каждое событие вызывается отдельным методом Важно! В любой модели машины состояний по умолчанию присутствует event с типом init, хотя он и не описан в явном виде. Такое событие является обязательным и при его вызове в витрину добавляется новая запись и устанавливается статус исходного состояния (initial) |
event: |
Название события |
from: |
Массив состояний из которых возможен вызов события |
to: |
В какое состояние переходит стэйт-машина после наступления события |
hooks: |
Массив связанных событий, которые будут выполняться после перехода в заданное состояние. На текущий момент в рамках hook возможен только вызов событий других стэйт-машин. Каждый hook имеет следующие свойства:
|
confirm: |
Вызов внешнего REST-метода. Данное действие выполняется до осуществления перехода в рамках вызванного события. Блок содержит следующие свойства: Описание запроса:
Описание ответа:
|
updatable: |
Признак, указывающий, что необходимо обновить ресурс в рамках вызываемого события |
updatable_attributes: |
Массив атрибутов, которые необходимо обновить в рамках вызываемого события.
Если массив пустой |
Пример структуры карты машины состояний:
model: slot # имя модели
states: # массив состояний объекта
- state: available # название состояния available
attributes: # массив атрибутов, описывающих состояние
- name: status # состояние определятся значением атрибута status
value: AVAILABLE # значение атрибута для описываемого состояния
initial: true
- state: booked
attributes:
- name: status
value: RECORDED
- state: reserved
attributes:
- name: status
value: RESERVED
- state: cancelled
attributes:
- name: status
value: CANCELED
- state: blocked
attributes:
- name: status
value: BLOCKED
- state: deleted
delete: true
events: # список событий изменения состояний, из них создаются методы API
- event: book # создает метод POST /states/slot/book
from: # массив состояний из которых возможен вызов события
- available
- reserved
to: booked # в какое состояние переводится объект после события
hooks: # массив связанных событий
- model: book # после перевода надо вызвать событие init для модели book
event: init
confirm:
source: rmis_rest # названия источника
endpoint: /booking/book
method: post
body: payload # что включать в тело запроса (full|state|conditions|payload|credentials)
accept: # условие принятия
jsonpath: $.status.statusCode
eq: 0 # ожидаем, что statusCode будет равен 0
enrich:
allow: true // по умолчанию false
attributes: [] // пустой массив — все, а если перечислены, то только эти
jsonpath: $.update.payload // ожидается что по этому адресу объект с атрибутами и значениями
- event: reserve
from: available
to: reserved
updatable: true // по умолчанию false для всех, кроме init, возможность изменять запись при переводе статуса
updatable_attributes: [] // массив атрибутов, которые можно обновлять, пустой — можно все
- event: block
from: available
to: blocked
- event: cancel
from:
- available
- reserved
- booked
- blocked
to: cancelled
hooks:
- model: book
event: cancel
- event: delete
from:
- available
- reserved
- booked
- blocked
- cancelled
to: deleted
hooks: # массив связанных событий
- model: book # после перевода надо вызвать событие delete для модели book
event: delete
2.3.5.3.4.1.3. Сценарий выполнения
Администратор системы в произвольном текстовом редакторе создает и заполняет файл (
state.yaml) с описанием карты машины состояний.Администратор системы создает папку с названием модели стэйт-машины в рамках каталога
states.Администратор системы создает папку с указанием номера версии модели стэйт-машины в рамках каталога с названием стэйт-машины.
Администратор системы вручную переносит, заранее подготовленный файл
state.yaml, в папку с новым номером версии.Для возможности вызова API методов новой карты машины состояния необходимо обновить openAPI СМЭВ QL (Раздел 2.3.5.3.1.4.3)
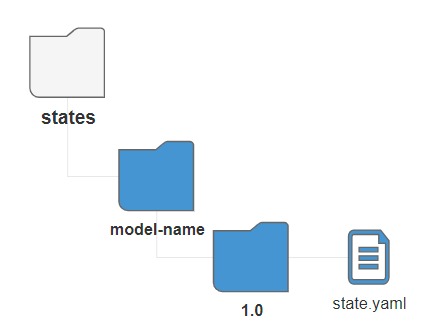
Рисунок - 2.11 Создание карты машины-состояний
2.3.5.3.4.2. Создание новой версии карты машины-состояний
2.3.5.3.4.2.1. Общее описание
СМЭВ QL может одновременно использовать несколько разных моделей стэйт-машин с разным наименованием.
Однако в рамках одного наименования модели (папки с названием модели) может быть активна только одна версия модели стэйт-машины.
Версия модели стэйт-машины характеризуется уникальным номером и наличием отдельной папки с данным номером в файловой системе СМЭВ QL.
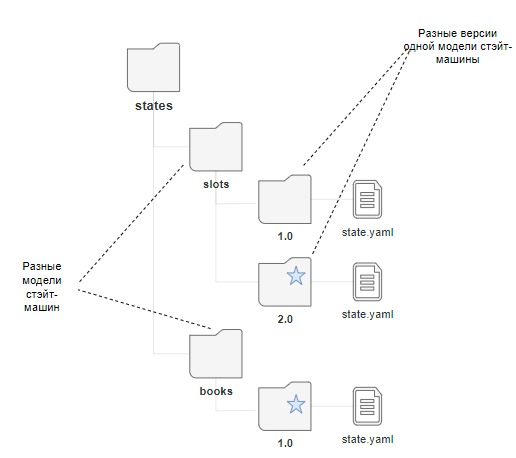
Рисунок - 2.12 Создание новой версии карты машины-состояний
Карты машин состояний считываются, валидируются и загружаются в память из папки states при запуске СМЭВ QL сервера.
По-умолчанию используется версия стэйт-машины, на которую ссылается symlink current, при его отсутствии по-умолчанию считается старшая версия.
Карты машин состояний и версии, начинающиеся с подчеркивания (_) НЕ загружаются, они находятся в стадии проектирования.
2.3.5.3.4.2.2. Сценарий выполнения
Предварительные условия:
Подготовлена модель стэйт-машины с учетом всех необходимых изменений (файл
state.yaml).
Ход выполнения:
Администратор системы выбирает папку с названием стэйт-машины для которой необходимо создать новую версию.
Администратор системы вручную создает новую папку с указанием нового номера версии (обычно это новое целочисленное значение).
Администратор системы вручную переносит, заранее подготовленный файл state.yaml, в папку с новым номером версии.
Администратор перезапускает сервер (Раздел 3.6.1).
2.3.5.3.5. Обработка запроса к витрине
2.3.5.3.5.1. Запрос получения данных из витрины (POST/data)
2.3.5.3.5.1.1. Общее описание
Для выполнения запроса к СМЭВ QL серверу на получение данных витрины (или нескольких витрин, если запрос распределенный (Раздел 2.3.5.2.5)) потребитель
должен вызвать опубликованный метод POST/data.
В рамках запроса необходимо передать в теле JSON-объект заданного формата.
POST /data содержит подробное описание.
2.3.5.3.5.2. Запрос изменения данных витрины через события машины состояний (POST/states/{model}/{event})
Для выполнения запроса к СМЭВ QL сервер на изменение данных витрины через машину состояний потребитель должен вызвать
опубликованный метод POST/states/{model}/{event}, где model - название карты машины состояний, а event - событие карты машины
состояний.
В рамках запроса необходимо передать в теле JSON-объект заданного формата.
В рамках вызова событий машины состояний можно выполнять следующие действия:
Изменить статус машины состояния без обновления данных витрины;
Обновить данные витрины (добавить новые, изменить текущие);
Удалить данные витрины;
Вызывать событие другой машины состояния;
Добавить/обновить/удалить данные другой витрины.
POST /states/{model}/{event} содержит подробное описание.
2.3.5.3.5.3. Обработка запроса получения данных витрины
2.3.5.3.5.3.1. Общее описание
При поступлении запроса от Потребителя на получение данных к СМЭВ QL сервер запускается процесс его обработки, который можно условно разделить на 4 этапа:
Проверка запроса и доступов.
Формирование плана исполнения запроса.
Исполнение плана запроса.
Передача ответа потребителю.
Для возможности получения данных Потребителем должны быть соблюдены следующие предварительные условия:
Модель данных СМЭВ QL сервера успешно создана.
Зарегистрирован метод получения данных витрины
POST/data.Потребитель обладает правами на выполнение REST-запроса.
2.3.5.3.5.3.2. Проверка запроса и доступов
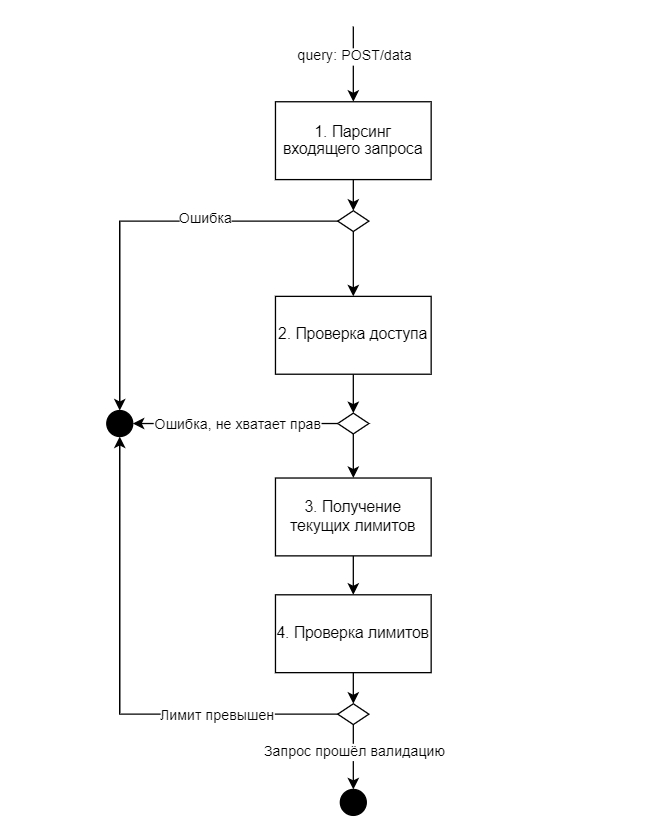
Рисунок - 2.13 Проверка запроса и доступов
Запускающее событие:
Получен запрос получения данных витрины (вызван метод
POST/data)
Ход выполнения:
СМЭВ QL (далее Система) проверяет тело запроса на соответствие заданной схеме (Обработка запроса к витрине):
если запрос не соответствует заданной схеме, то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
иначе, формат запроса корректен, переход к выполнению следующего шага.
Система проверяет доступ ИС Потребителя к данным витрины, для этого сравнивает полученный в запросе идентификатор системы-потребителя (блок
credentials->system) c перечнем запрещенных и разрешенных, который задается в конфигурационном файле приложенияapplication.yaml(black_listиwhite_list):если доступ запрещен, то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
иначе, доступ разрешен, переход к выполнению следующего шага.
Система получает из блока персистентности Redis текущие значения лимитов на выполнение запросов.
Система проверяет превышение установленных лимитов на выполнение запроса Потребителя к заданным ресурсам. Для этого сравнивает текущие полученные значения на шаге 3 с настройками лимитов, определенных в конфигурационном файле приложения
application.yaml(limits):если допустимый лимит превышен, то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
иначе, лимиты не превышены, переход к выполнению этапа «Формирование плана исполнения запроса».
2.3.5.3.5.3.3. Формирование плана исполнения запроса
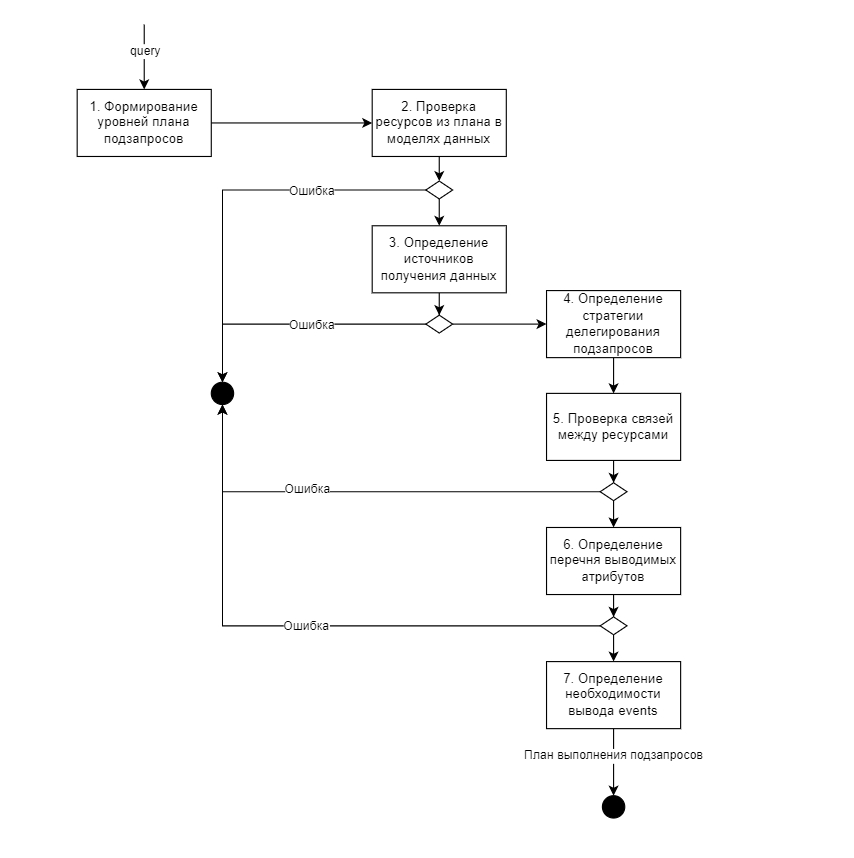
Рисунок - 2.14 Формирование плана исполнения запроса
Запускающее событие:
Запрос получения данных витрины прошел необходимые проверки.
Ход выполнения:
1. Система на основании вложенности ресурсов, заданной в запросе (query) определяет уровни плана выполнения запроса и sql-выражения. Формирование плана запроса основывается на внешнем объединении данных в сторону основной сущности.
Порядок формирования плана запроса:
на основе query определяется основная запрашиваемая сущность
на основе query определяются вспомогательные сущности
на основе query определяются conditions к основной сущности
на основе query определяются conditions к вспомогательным сущностям
на первом уровне плана формируется запрос к основной сущности на основе:
запрошенных атрибутов
данных модели
условий фильтрации
Отмечаются поля, составляющие PK.
Первичные ключи, даже отсутствующие в атрибутах запроса к серверу должны быть в запросе к источнику.
формируется запрос к вспомогательным сущностям на основе:
запрошенных атрибутов
данных модели
условий фильтрации
с добавлением фильтрации по PK основной или предшествующей сущности
Первичные ключи, даже отсутствующие в атрибутах запроса к серверу должны быть в запросе к источнику, за исключением терминальных запросов.
Пример уровней плана на основе запроса:
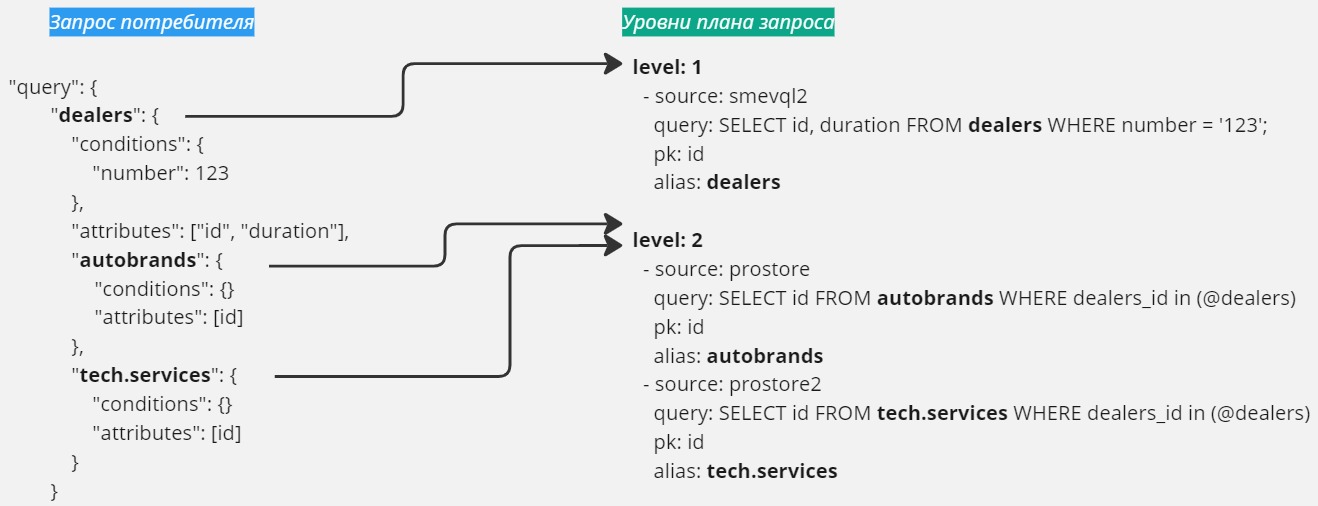
Рисунок - 2.15 Формирование плана исполнения запроса
Система проверяет, что все ресурсы из плана запроса определены в модели данных:
если хотя бы один ресурс не описан в модели данных, то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
иначе, все ресурсы описаны в модели данных, переход к выполнению следующего шага.
Система проверяет, что для каждого ресурса определён источник получения данных. Для этого по каждому ресурсу определяет его источник в модели данных (блок
extract:), в т.ч. с учетом условий применения источника (extract->conditions:) и описан ли источник в модели source:если хотя бы один источник данных не определен в модели данных или не описан в модели источников, то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
иначе, для каждого ресурса определен источник данных, переход к выполнению следующего шага.
Система определяет стратегию делегирования подзапросов (подзапросов более низкого уровня). Для этого определяет значение в параметре
request→strategyконфигурационного файла приложенияapplication.yaml(делегирование возможно только источнику smevql):если значение
atomic- то последовательность выполнения подзапросов соответсвует иерархии уровней, определенной на шаге 1;иначе установлено значение delegate - делегирование подзапроса со всеми дочерними элементами другому СМЭВ QL. В таком случае, все делегированные подзапросы исключаются из плана запроса данного СМЭВ QL.
Система проверяет, что в модели данных (блок connections:) существуют и корректно заполнены связи между всему основными и подчиненными ресурсами:
если хотя бы одна связь между основным и подчиненным ресурсом не задана или некорректно описана, то то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
иначе, связи между ресурсами заполнены корректно, переход к выполнению следующего шага.
Система проверяет, что перечень атрибутов, запрашиваемый Потребителем не запрещен на уровне модели данных. Для этого проверяет заполнение блока
guard:в модели данных и определяет соблюдены ли условия по передачи данных атрибутов в запросе (блокconditions):если хотя бы один атрибут запрещен для передачи Потребителю (guard заполнен в модели, а требуемый conditions не заполнен в запросе), то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
иначе, все требуемые атрибуты разрешены для передачи Потребителю, переход к выполнению следующего шага.
Система на основании блока
fetch→show_eventsопределяет возможность обогащения передаваемых атрибутов данными о возможных событиях (event) машины состояний. Текущий процесс завершается и вызывается исполнение плана запроса.
2.3.5.3.5.3.4. Исполнение плана запроса
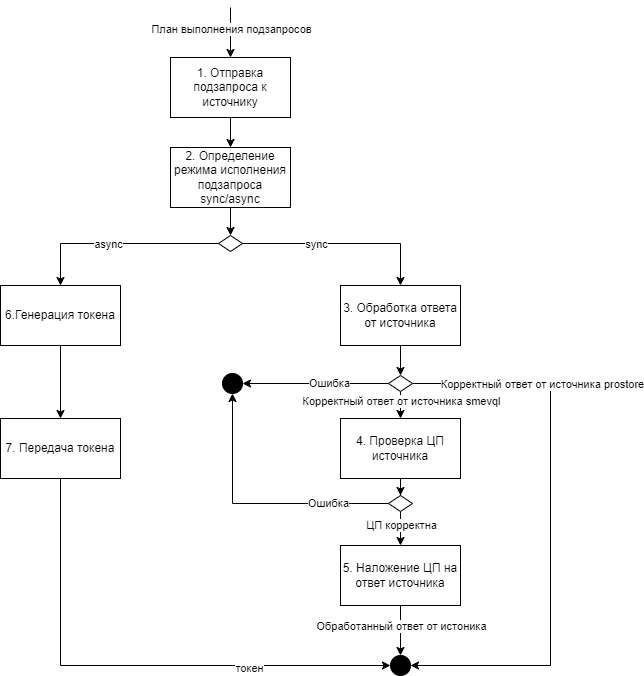
Рисунок - 2.16 Исполнение плана запроса
Запускающее событие:
Подготовлен план выполнения запроса
Ход выполнения:
Указанная последовательность выполняется для каждого подзапроса из плана. При этом сначала параллельно выполняются подзапросы первого уровня, затем подзапросы второго уровня на основе данных полученных на первом уровне и т.д. по всем уровням иерархии плана запроса.
В качестве ответа от Источника могут быть сами запрашиваемые данные (если обращение к источнику шло в синхронном режиме) или токен (если обращение к источнику шло в асинхронном режиме).
Система отправляет подзапрос к источнику с указанным в плане sql-выражением. Так же на этом шаге Система обновляет счетчики лимитов в Redis, при этом количество увеличивается на величину подзапросов к источникам данных.
Система ожидает ответ и определяет режим обработки подзапроса к источнику ресурса. Для этого определяет значение параметра
fetch->policyв модели данных ресурса:если установлено значение
syncилиasync_on_timeoutи ответ пришёл в течение заданного таймаута, то режим обработки подзапроса синхронный, переход к выполнению шага 2;иначе, установлено значение async или async_on_timeout и исчтоник не отвечает в в течение заданного таймаута, то режим обработки подзапроса асинхронный, переход к выполнению шага 6.
Система обрабатывает полученный ответ от источника или обрабатывает ситуацию, когда ответ не получен:
если ответ получен и он некорректного формата или ответ не получен в заданный таймаут, то Система передаёт соответствующее сообщение об ошибке, процесс завершается;
если, ответ корректен и получен в заданный таймаут, а источником данных является prostore, то данный процесс завершается и вызывается выполнение передачи ответа потребителю (Раздел 2.3.5.3.5.3.5);
иначе, ответ корректен и получен в заданный таймаут, а источником данных является smevql, переход к выполнению следующего шага.
Система проверяет, что ответ от источника подписан цифровой подписью (далее ЦП). Для этого извлекает данные из полученного ответа (блок
signature) и отправляет данные ЦП на проверку в модуль Notarius. После чего дожидается результатов проверки ЦП от Notarius:если ЦП не прошла успешную проверку в Notarius или блок
signatureне заполнен источником, то ответ считается невалидным, Система передаёт соответствующее сообщение об ошибке, процесс завершается;иначе, ЦП прошла успешную проверку в Notarius, ответ валиден, переход к выполнению следующего шага.
Система накладывает свою ЦП на ответ источника. Для этого отправляет запрос в модуль Notarius и ожидает получение ответа. После чего ответ подписан ЦП (заполнен блок partials в ответе для потребителя). Процесс завершается после получения всех ответов от всех источников и вызывается выполнение передачи ответа потребителю (Раздел 2.3.5.3.5.3.5).
Система генерирует токен (по которому в дальнейшем Потребитель сможет отдельно запросить данные) и записывает его в блоке персистентности Redis.
Система в качестве временного ответа от источника подставляет токен (Раздел 2.3.5.3.5.4). Процесс завершается после получения всех ответов от всех источников и вызывается выполнение передачи ответа потребителю.
2.3.5.3.5.3.5. Передача ответа потребителю
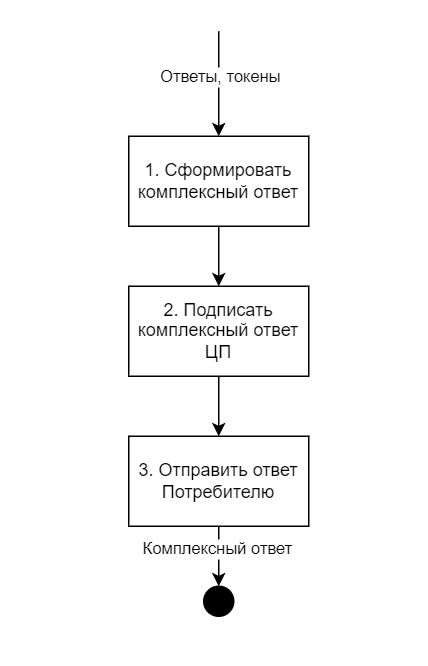
Рисунок - 2.17 Передача ответа потребителю
Запускающее событие:
Получены все ответы от источников и/или токены.
Ход выполнения:
Система формирует комплексный ответ на основе полученных ответов от источников и/или токенов. Формат ответа в таблице ниже:
Элемент |
Описание |
Пример |
|---|---|---|
response |
Объект, который содержит данные запрашиваемых ресурсов и/или токенов для асинхронного получения данных ресурсов |
|
<resource_name> |
Название ресурса, массив данных которого был получен в источнике. Если запрос содержал подчиненные ресурсы, то данные таких ресурсов будут вставлены в массив объекта основного ресурса. Если данные ресурса должны быть получены отдельно в асинхронном режиме, то ответ будет содержать блок
|
|
credentials |
Объект, содержащий общие данные запроса и информация о потребителе |
|
response |
Объект описывает общие параметры ответа. Имеет следующие атрибуты:
|
|
system |
Объект описывает параметры системы-потребителя данных. Имеет следующие атрибуты:
|
|
request |
Объект описывает общие параметры запроса. Имеет следующие атрибуты:
|
|
signature |
Объект, содержащий данные ЦП по каждому ответу от каждого источника, а так же ЦП комплексного ответа |
|
complex |
ЦП комплексного ответа, имеет следующие атрибуты:
|
|
partials |
Массив ЦП по каждому полученному ответу от источников данных. Содержит следующие атрибуты:
|
2.3.5.3.5.3.6. Пример блока response
"response": {
"ticket": [
{
"number": 1,
"price": 701.0252675821603,
"trip": [
{
"id": "f72f4157-e11b-4fe1-86a2-babaeb3ccd21",
"duration": "07:31:03"
}
]
}
]
}
2.3.5.3.5.3.7. Пример блока async
"async": {
"token": "11111-22222-333333-4444-55555",
"source": "region81",
"reason": "async_on_timeout",
"timeout": "500ms",
"request_in": "10s",
"retries_left": "9"
}
2.3.5.3.5.3.8. Пример блока credentials
"credentials": {
"response": {
"id": "fc7953cb-99ad-4a78-b49d-c3dce2c4bb89",
"sub_id": "a8744e12-49ce-4524-861d-0e3b9a763d14",
"started_at": "2023-02-13 07:55:23 +0300",
"finished_at": "2023-02-13 07:55:23 +0300"
},
"system": {
"mnemonic": "117bed7f-1c07-4079-a446-1161588db4e5",
"instance_id": "ccb4a88f-f44b-43e7-8a97-3e45c8345e90",
"user_id": "5ed38461-0907-486a-930a-7b443482932c"
},
"request": {
"id": "df5a0073-c6be-4d8c-8eb2-9b2f4188a429",
"sub_id": "0cdb59ce-224b-4118-8da1-c5ea08a5d955",
"name": "driver_data",
"purpose_id": "ed1170f1-3caa-4985-aa38-c9c5a190b770",
"audit": "false",
"audit_id": "fc1048fe-323d-4eeb-92df-5710b3d1d100",
"audit_token": "39e47aac-45d2-44c1-8c26-2d9b28b1703b"
}
},
"signature": {
"complex": {
"digest": "985925e62ce3494a4e73f20676f1506ef64380f0",
"signature": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9"
},
"partials": [
{
"digest": "985925e62ce3494a4e73f20676f1506ef64380f0",
"signature": "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9",
"response_id": "fc7953cb-99ad-4a78-b49d-c3dce2c4bb89",
"jsonpath": "$.response.office"
}
]
}
}
2.3.5.3.5.4. Асинхронное получение данных клиентом
2.3.5.3.5.4.1. Общее описание
Разные источники с разной скоростью передают данные и по скорости передачи данных их условно можно разделить на «быстрые» и «медленные».
При взаимодействии с «быстрыми» источниками обмен клиента (потребителя) со СМЭВ QL происходит в синхронном режиме в таком случае запрашиваемые данные передаются с
разу в момент обращения, а при взаимодействии с «медленными» источниками обмен происходит в асинхронном режиме, в таком случае данные передаются с
определенным временным лагом. Указание типа взаимодействия, синхронное или асинхронное, определяется на уровне модели данных в блоке fetch->policy.
Для потребителя наличие в ответе блока async с токеном вместо данных означает, что данные необходимо получить отдельным запросом, вызвав метод GET/data/{token}.
2.3.5.3.5.4.2. Передача асинхронных данных от источника в СМЭВ QL
Предварительные условия:
СМЭВ QL отправил источнику запрос получения данных (Раздел 2.3.5.3.5.3) и сохранил токен.
Ход выполнения:
Источник подготавливает и передает данные в асинхронном режиме.
СМЭВ QL записывает полученные данные в блоке персистентности в спейсе responses с временем жизни
store_timeout, где в качестве ключа выступает ранее сформированный токен.
Пример записи асинхронных данных в блоке персистентности:
ключ (токен):
11111-22222-333333-4444-55555значение (данные от источника)
{"referral": [
{
"to_post_name": "врач-терапевт участковый",
"end_date": null,
"speciality_id": "119",
"to_mo_id": "325",
"mo": [
{
"id": "325",
"name": "ГКБ 222; Кардиология"
}
]
}
]
}
2.3.5.3.5.4.3. Запрос асинхронных данных потребителем
Предварительные условия:
Потребитель получил ответ от СМЭВ QL с блоком async
Ход выполнения:
Потребитель, спустя рекомендованное время (параметр
async->request_inв ответе), отправляет запрос получения асинхронных данных. Для этого вызывает методGET/data/{token}, где в качестве{token}передаёт значение, полученное ранее в ответе (async→token).СМЭВ QL сервер проверяет наличие данных по токену:
если данные ещё не поступили от источника, то обновляет счётчик обращений от клиента и формирует ответ вида:
{
"response": {},
"asynced": {
"referral": [
{
"async":{
"source": "region12",
"reason": "receiving_data",
"timeout": "10s",
"request_in": "10s",
"retries_left": "5"
}
}
]
}
}
b. иначе, данные были получены от источника, Система формирует ответ с данными вида:
{
"response": {
"referral": [
{
"to_post_name": "врач-терапевт участковый",
"end_date": null,
"speciality_id": "119",
"to_mo_id": "325",
"mo": [
{
"id": "325",
"name": "ГКБ 222; Кардиология"
}
]
}
]
},
СМЭВ QL сервер подписывает ответ ЦП с помощью Notarius и передаёт потребителю подписанный ответ.
Примечание
Потребитель продолжает запрашивать данные с рекомендованным интервалом пока не получит данные или пока количество попыток retries_left не будет равно 0.
2.3.5.3.5.5. Обработка запроса изменения данных витрины через машину состояний
2.3.5.3.5.5.1. Общее описание
Машина состояний СМЭВ QL сервер имеет определенное количество состояний (states), переход между которыми осуществляется посредством вызова событий (events).
В зависимости типа вызываемого события выполняется разная логика по обновлению данных витрины.
2.3.5.3.5.5.2. Основной сценарий выполнения
Запускающее событие:
Потребитель вызвал событие посредством выполнения запроса POST/states/{model}/{event}.
Схема процесса:
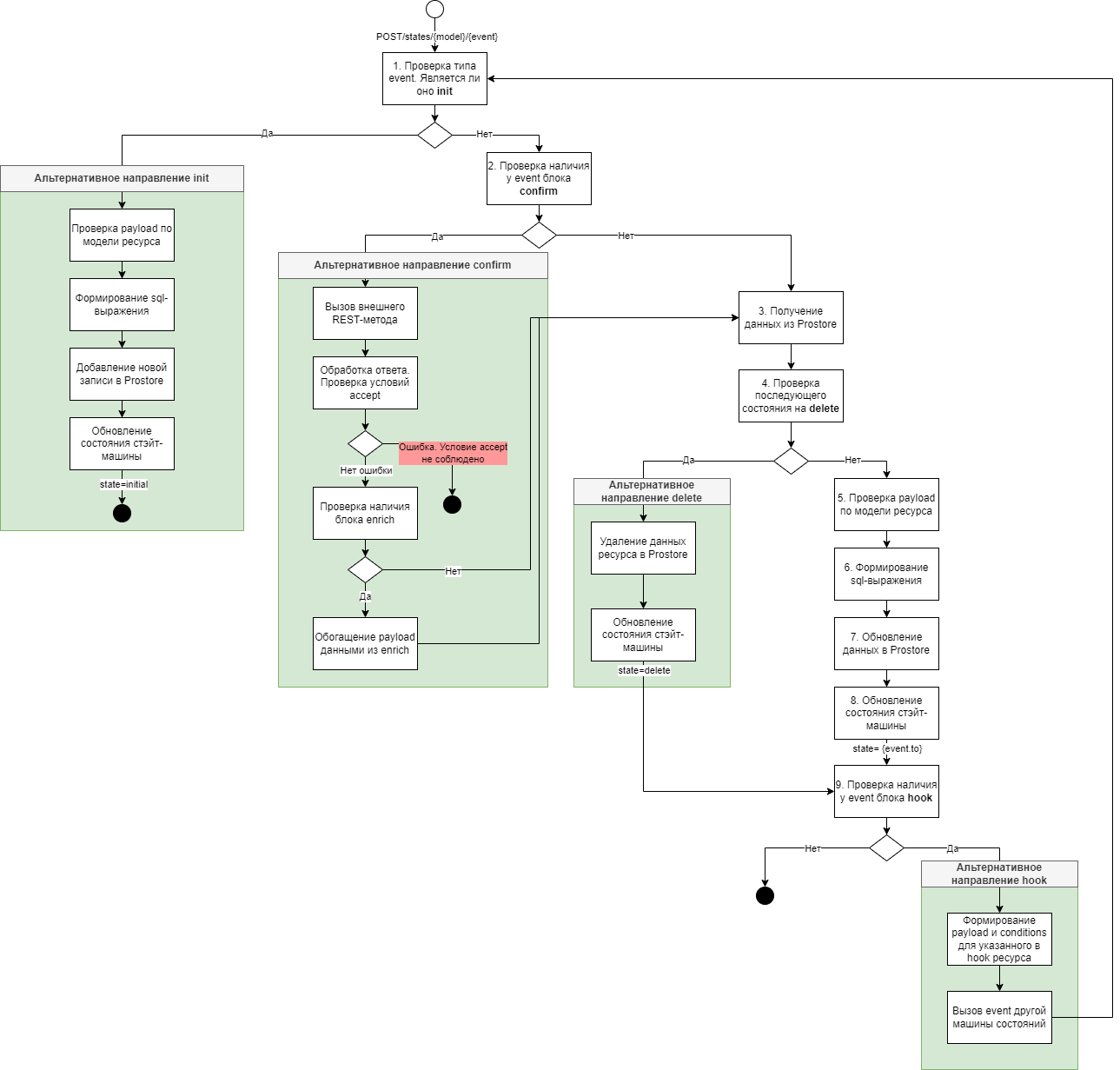
Рисунок - 2.18 Обработка запроса изменения данных витрины через машину состояний
Ход событий:
Система проверяет тип вызываемого события:
если событие с типом init (
POST/states/{model}/init), то вызывается альтернативное направление (Раздел 2.3.5.3.5.5.3);иначе, событие не init, переход к выполнению следующего шага.
Система проверяет наличие блока
confirmу вызванного события:если событие содержит блок
confirm, то вызывается альтернативное направление (Раздел 2.3.5.3.5.5.4);иначе, событие не содержит блок confirm, переход к выполнению следующего шага.
Система получает данные из Prostore для ресурса, вызванной стэйт-машины и сохраняет их в оперативной памяти для последующего обращения. В качестве критерия используются:
Условия в блоке
conditionsисходного запросаЗначения
attributes:из текущего состояния стэйт-машины
Количество записей, получаемых из Prostore ограничено настройкой max_updated_rows в конфигурационном файле приложения application.yaml.
После получения данных, осуществляется переход к выполнению следующего шага.
Система проверяет в какое состояние должна перейти стэйт-машина после выполнения вызванного события. Для этого у вызванного события читается параметр
to:если стэйт-машина должна перейти в состояние с признаком
delete = true, то вызывается альтернативное направление (Раздел 2.3.5.3.5.5.5);иначе, стэйт-машина должна перейти в состояние с признаком
delete = false(неуказанный признак delete у события приравнивается к значению false), переход к выполнению следующего шага.
Система выполняет проверку наличия атрибутов, заданных в блоке
payloadисходного запроса, в модели данных ресурса. Атрибуты отсутствующие в модели данных ресурса игнорируются (не участвуют в последующем обновлении данных витрины). После данной проверки, осуществляется переход к выполнению следующего шага.Система формирует SQL-выражение (определяет какие атрибуты должны быть обновлены) для обновления данных витрины (для выполнения операции upsert в prostore) с учетом следующих правил:
Атрибуты из
payloadисходного запроса применяются только, если у вызванного события признакupdatable: true;Атрибуты из
payloadисходного запроса ограничиваются блокомupdatable_attributes:(если он указан) вызванного события;Атрибуты, полученные при выполнении
confirm(Раздел 2.3.5.3.5.5.4) из блокаenrich, применяются всегда;Атрибуты, заданные в блоке
attributes:текущего состояния стэйт-машины, применяются всегда, за исключением случая, когда у текущего состояния установлен признакstatic: true.
После формирования SQL-выражения, осуществляется переход к выполнению следующего шага.
Система обновляет данные ресурса в Prostore (операция upsert) значениями атрибутов, определенных на шаге 6 и только для тех записей, которые были получены на шаге 3. После обновления данных осуществляет переход к выполнению следующего шага. Опционально: если в конфигурационном файле
application.yaml, параметрstate_machine_enabled: true, то вызывает процесс передачи уведомления об изменении данных витрины.Система переводит стэйт-машину в состояние, указанное в параметре to: вызванного события. После этого осуществляет переход к выполнению следующего шага.
Система проверят наличие блока
hooksу вызванного события:если событие содержит блок
hooks, то вызывается альтернативное направление Раздел 2.3.5.3.5.5.6;иначе, обработка события считается выполненной, завершение основного направления.
2.3.5.3.5.5.3. Альтернативное направление для событий с типом init
Данное альтернативное направление запускается из шага 1 основного направления, когда было вызвано событие стэйт-машины с типом init. Данный тип события
предполагает, что в витрину данных будут добавлены новые записи.
Система выполняет проверку наличия атрибутов, заданных в блоке
payloadисходного запроса, в модели данных ресурса. Атрибуты отсутствующие в модели данных ресурса игнорируются (не участвуют в последующем обновлении данных витрины). После данной проверки, осуществляется переход к выполнению следующего шага.Система формирует SQL-выражение для добавления новых записей ресурса с учетом атрибутов, отобранных на шаге 1 данного альтернативного направления. После этого переходит к выполнению следующего шага.
Система добавляет новые записи ресурса в Prostore (операция upsert). После этого осуществляет переход к выполнению следующего шага.
Система переводит стэйт-машину в состояние, у которого задан признак
initial: true. После чего завершается выполнение данного альтернативного и основного сценария.
Опционально: если в конфигурационном файле
application.yaml, параметрstate_machine_enabled: true, то вызывает процесс передачи уведомления об изменении данных витрины (Раздел 2.3.5.3.6.5).
2.3.5.3.5.5.4. Альтернативное направление для событий с блоком confirm
Данное альтернативное направление запускается из шага 2 основного направления, когда вызванное событие имеет блок confirm.
Такое событие предполагает обращение к внешнему источнику с целью передачи ему и получения от него дополнительных данных.
Система формирует и передаёт REST-запрос внешнему источнику. Формирование запроса и определение адресата происходит на основании параметров, указанных в блоке
confirmзапускаемого события:source,endpoint,method,body. После этого переходит к выполнению следующего шага.Система обрабатывает полученный ответ. Для этого читает условия проверки ответа, заданное в блоке
confirm->acceptвызванного события:если ответ не соответствует условиям, заданным в accept, то Система передаст соответствующую ошибку Потребителю. Завершение данного альтернативного и основного направлений.
иначе, ответ соответствует условиям, заданным в accept или блок accept не задан, переход к выполнению следующего шага.
Система проверяет наличия блока
enrichв описании вызванного события:если блок
enrichотсутствует, то выполняется переход к шагу 3 основного направления. Данное альтернативное направление завершается.иначе, блок
enrichзадан, переход к выполнению следующего шага.
Система извлекает данные из полученного на шаге 2 ответа и сохраняет их для последующего использования. Далее выполняется переход к шагу 3 основного направления. Данное альтернативное направление завершается.
2.3.5.3.5.5.5. Альтернативное направление при переходе в состояние delete
Данное альтернативное направление запускается из шага 4 основного направления, когда было вызвано событие после выполнения которого стэйт-машина должна перейти в
состояние с признаком delete. Данный тип события предполагает, что в должны быть удалены данные ресурса из витрины.
Система удаляет записи ресурса, полученные на шаге 3 основного направления.
Система переводит стэйт-машину в состояние, у которого задан признак
delete: true.После чего осуществляет переход к выполнению шага 9 основного направления. Данное альтернативное направление завершается.
Опционально: если в конфигурационном файле application.yaml, параметр state_machine_enabled: true, то вызывает процесс передачи уведомления об изменении данных
витрины.
2.3.5.3.5.5.6. Альтернативное направление для событий с блоком hooks
Данное альтернативное направление запускается из шага 9 основного направления, когда вызванное событие имеет блок hooks. Такое событие предполагает вызов другого
события машины состояния, таким образом формируя вложенные вызовы событий. Количество уровней вложенных вызовов ограничено настройкой max_nested_event в
конфигурационном файле приложения application.yaml. Если в блоке hooks определены несколько переходов (допускается указание массива), то описанные действия
выполняются для каждого перехода.
Система формирует REST-запрос для вызова другого события стэйт-машины по следующим правилам:
URL метода
POST/states/{model}/{event}:{model}- берется из параметраmodelблокаhooks;{event}- берется из параметраeventблокаhooksconditions: Заполняется идентификаторами записей нового вызываемого ресурса (название ресурса соответствует названию model). Берутся записи исходного ресурса, полученные на шаге 3 основного направления, далее по связям в модели данных определяются идентификаторы записей для нового ресурса;
payload: Строится на основе payload исходного запроса, выбираются атрибуты объекта, название которого совпадает с новым вызываемым ресурсом.
Система передаёт REST-запрос для вызова события стэйт-машины. Переход к выполнению шага 1 основного направления, но уже с данными другого события и ресурса. Завершение данного альтернативного направления.
2.3.5.3.5.6. Обработка регламентированного СМЭВ QL запроса
2.3.5.3.5.6.1. Общее описание
Для выполнения запроса к СМЭВ QL РЗ потребитель должен вызвать опубликованный метод POST /regulated-query.
В рамках запроса необходимо передать в теле JSON-объект заданного формата.
Таблица 2.11 содержит описание формата запроса POST /regulated-query.
Элемент |
Описание |
Пример |
|---|---|---|
mnemonic |
Мнемоника регламентированного запроса СМЭВ QL |
|
majorVersion |
Мажорная версия запроса |
|
minorVersion |
Минорная версия запроса |
|
params |
Объект, содержащий значения параметров запроса в формате «параметр»: «значение» |
"params":
{
"month": 1
}
|
credentials |
Объект, содержащий общие данные запроса и информация о потребителе, аналогичен запросу данных (Раздел 2.3.5.3.5) |
2.3.5.3.5.6.2. Алгоритм обработки запроса
При поступлении СМЭВ QL РЗ от Потребителя СМЭВ QL сервер запускается процесс его обработки:
Проверка запроса и доступов:
а) СМЭВ QL РЗ с такой мнемоникой и версией зарегистрирован;
б) проверка мнемоники Инициатора по black_list и white_list;
в) проверка параметров запроса на соответствие описанию в шаблоне;
Формирование запроса данных на основе СМЭВ QL РЗ и полученных параметров;
Исполнение запроса в соответсвии с Раздел 2.3.5.3.5.3.
2.3.5.3.6. Уведомления при изменении данных витрины (push-сервис)
2.3.5.3.6.1. Регистрация получателя уведомлений
2.3.5.3.6.1.1. Общее описание
Данная функция позволяет зарегистрировать в СМЭВ QL сервер нового получателя уведомлений при изменении данных ресурса.
Помимо самого факта уведомления об изменении данных, можно получать определенные атрибуты ресурса, которые будут переданы в рамках нотификации.
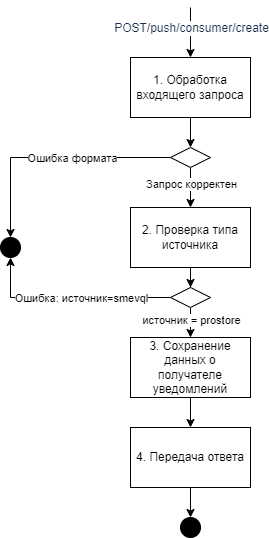
Рисунок - 2.19 Регистрация получателя уведомлений
Предварительные условия:
Потребитель (получатель уведомлений) вызвал запрос на регистрацию получения уведомлений
POST/push/consumer/create
Ход выполнения:
СМЭВ QL сервер (далее Система) проверяет входящий запрос на соответствие заданной схеме (Раздел 2.3.5.3.6.1.2):
если формат запроса некорректен, то Система возвращает соответствующую ошибку и завершает исполнение сценария.
иначе, запрос корректного формата, переход к выполнению следующего шага.
Система проверяет к какому типу относится источник данных заданного в запросе ресурса:
если тип источника = smevql, то Система возвращает соответствующую ошибку и завершает исполнение сценария.
иначе, тип источника = prostore, переход к выполнению следующего шага.
Система сохраняет данные о получателе уведомлений в
redis hashс названиемpush:consumers:[agent_target]:[resource], значение представляется в виде json:
{
"bag": ["sample_field1", "sample_field2"],
"started_at": "2022-01-01 00:00:00",
"finished_at": "2022-12-31 23:59:59"
}
Система передаёт ответ с указанием ключа:
{
"created_consumer": {
"key": "push:consumers:epgu:books"
}
}
Завершает выполнение сценария.
2.3.5.3.6.1.2. Описание запроса POST/push/consumer/create
Элемент |
Описание |
|---|---|
create_consumer |
Объект, содержащий информацию о получателе уведомлений и отслеживаемом ресурсе |
agent |
Объект, содержащий информацию об агентах СМЭВ4. Содержит следующие атрибуты:
|
resource |
Название ресурса, изменения данных которого необходимо отслеживать |
bag |
Массив атрибутов ресурса, которые необходимо передавать получателю в момент уведомления об изменении данных |
started_at |
Время начала отслеживания изменений |
finished_at |
Время окончания отслеживания изменений |
Пример:
{
"create_consumer": {
"agent": {
"source": "zdrav777",
"target": "epgu"
},
"resource": "books",
"bag": ["sample_field1", "sample_field2"],
"started_at": "2022-01-01 00:00:00",
"finished_at": "2022-12-31 23:59:59"
}
}
2.3.5.3.6.2. Удаление получателя уведомлений
2.3.5.3.6.2.1. Общее описание
Для того, чтобы прекратить получение уведомлений при изменении ресурса, необходимо вызвать один из следующих методов СМЭВ QL:
Удаление получателя уведомлений на конкретный ресурс:
POST/push/consumer/delete/resourceУдаление получателя уведомлений на все ресурсы:
POST/push/consumer/delete
2.3.5.3.6.2.2. Сценарий выполнения
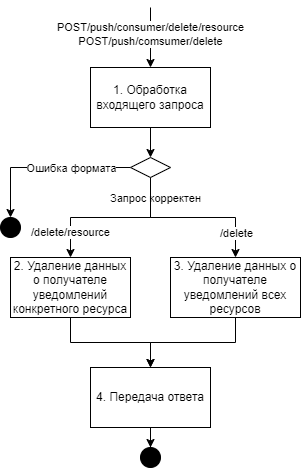
Рисунок - 2.20 Удаление получателя уведомлений
Предварительные условия:
Потребитель (получатель уведомлений) вызвал запрос на удаление получения уведомлений POST/push/consumer/delete или POST/push/consumer/delete/resource
Ход выполнения:
Система проверяет входящий запрос на соответствие заданной схеме (Раздел 2.3.5.3.6.2.3):
если формат запроса некорректен, то Система возвращает соответствующую ошибку и завершает исполнение сценария.
иначе, запрос
POST/push/consumer/delete/resourceкорректного формата, переход к выполнению шага 2 или запросPOST/push/consumer/deleteкорректного формата, переход к выполнению шага 3.
Система удаляет данные о получателе уведомлений на конкретный ресурс из redis:
hash с названием
push:consumers:[agent_target]:[resource];cсылку на hash из
setc названиемpush:consumers:by:agent_target:[agent_target];ссылку на hash из
setc названиемpush:consumers:by:resource:[resource];Переходит к выполнению шага 4.
Система удаляет данные о получателе уведомлений на все ресурсы из redis:
получает список hash из
setc названиемpush:consumers:by:agent_target:[agent_target], далее по всем hash:удаляет из
setpush:consumers:by:resource:[resource]имяhash;удаляет
setc названиемpush:consumers:by:agent:target:[agent_target];удаляет hash;
Переходит к выполнению шага 4.
Система передаёт ответ с указанием удаленных ключей:
[
{
"deleted_consumer": {
"key": "push:consumers:epgu:books"
}
},
...
]
Завершает выполнение сценария.
2.3.5.3.6.2.3. Описание запроса
Элемент |
Описание |
|---|---|
delete_consumer |
Объект, содержащий информацию о получателе уведомлений и отслеживаемом ресурсе |
agent |
Объект, содержащий информацию об агентах СМЭВ4. Содержит следующие атрибуты:
|
resource |
Название ресурса, при изменении данных которого должны перестать приходить
уведомления для заданного получателя. Заполняется только в запросе
|
Пример:
{
"delete_consumer": {
"agent": {
"source": "zdrav777",
"target": "epgu"
},
"resource": "books"
}
}
2.3.5.3.6.3. Запрос списка получателей уведомлений
2.3.5.3.6.3.1. Общее описание
Для того, чтобы запросить список получателей уведомлений, необходимо вызвать один из следующих методов СМЭВ QL:
Получатели уведомлений конкретного ресурса:
GET/push/consumer/agent_targets/{resource};Все получатели уведомлений данного СМЭВ QL:
GET/push/consumer.
2.3.5.3.6.3.2. Сценарий выполнения
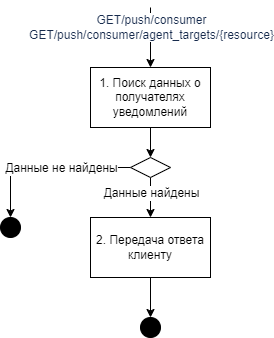
Рисунок - 2.21 Запрос списка получателей уведомлений
Предварительные условия:
Клиент вызвал запрос списка получателей уведомлений
GET/push/consumerилиGET/push/consumer/agent_targets/{resource}.
Ход выполнения:
Система выполняет поиск данных о получателях уведомлений в redis. При этом, если был вызван метод
GET/push/consumer, то Система получает все именаhashизset push:consumersи значения всехhash, а если был вызван методGET/push/consumer/agent_targets/{resource}, то Система получает именаhashизset push:consumers:by:resource:[resource]и значенияhashв рамках указанного ресурса.если данные не были найдены, то Система возвращает соответствующую ошибку и завершает исполнение сценария.
иначе, данные были найдены, переход к выполнению следующего шага.
Система формирует и передаёт ответ клиенту с указанием:
перечня всех получателей уведомлений, если был вызван метод
GET/push/consumer.перечня получателей уведомлений при изменении конкретного ресурса, если был вызван метод
GET/push/consumer/agent_targets/{resource}.
Формат ответа не меняется в зависимости от вызванного метода, отличается только количество передаваемых данных. Пример ответа:
[
{
"agent": {
"target": "epgu"
},
"key": "push:consumers:epgu:books"
"resource": "books",
"bag": ["sample_field1", "sample_field2"],
"started_at": "2022-01-01 00:00:00",
"finished_at": "2022-12-31 23:59:59"
},
...
]
2.3.5.3.6.4. Запрос данных об отслеживаемых ресурсах
2.3.5.3.6.4.1. Общее описание
Данная функция позволяет получить перечень отслеживаемых ресурсов заданным потребителем.
Для этого клиенту необходимо вызвать метод GET/push/consumer/resources/{agent_target}, где в качестве {agent_target} передать значение мнемоники Агента
Потребителя.
2.3.5.3.6.4.2. Сценарий выполнения
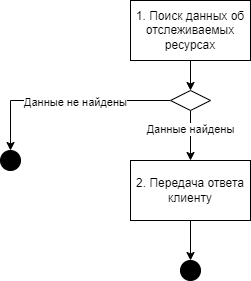
Рисунок - 2.22 Запрос данных об отслеживаемых ресурсах
Предварительные условия:
Клиент вызвал запрос списка отслеживаемых ресурсов
GET/push/consumer/resources/{agent_target}.
Ход событий:
Система выполняет поиск данных об отслеживаемых ресурсах в redis: получает имена
hashизsetpush:consumers:by:agent_target:[agent_target]и значенияhash.если данные не были найдены, то Система возвращает соответствующую ошибку и завершает исполнение сценария.
иначе, данные были найдены, переход к выполнению следующего шага.
Система формирует и передаёт ответ клиенту. Завершает выполнение сценария.
Пример ответа:
[
{
"agent": {
"target": "epgu"
},
"key": "push:consumers:epgu:books"
"resource": "books",
"bag": ["sample_field1", "sample_field2"],
"started_at": "2022-01-01 00:00:00",
"finished_at": "2022-12-31 23:59:59"
},
...
]
2.3.5.3.6.5. Передача уведомления при вызове события машины-состояний
2.3.5.3.6.5.1. Общее описание
Передача уведомлений об изменении данных витрины средствами СМЭВ QL сервер возможна при выполнении определенного перехода машины состояний (Раздел 2.3.5.3.5.5).
Формирование и передача уведомления происходит в следующих случаях:
Добавление новой записи в Prostore (для событий с типом
init);Удаление данных в Prostore (при переходе в состояние с типом
delete);Обновление данных в Prostore.
2.3.5.3.6.5.2. Сценарий выполнения
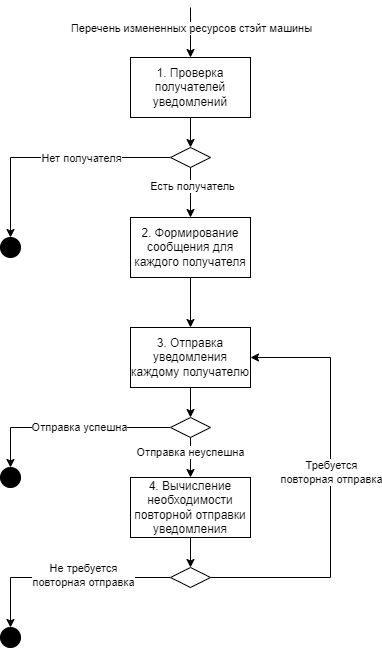
Рисунок - 2.23 Передача уведомления при вызове события машины-состояний
Предварительные условия:
Стэйт машина передала перечень измененных (новые, обновлённые, удалённые) записей ресурсов;
Получатель зарегистрировал REST-метод (
POST/api/v1/smevql/notify) для приёма уведомлений.
Ход событий:
Данные шаги выполняются в цикле для каждой записи измененного ресурса.
Система проверяет есть ли зарегистрированные получатели уведомлений при изменении заданного ресурса. Для этого читает из redis
setc названиемpush:consumers:by:resourceссылки на зарегистрированных получателей, для каждой ссылки: читает из redis hash данные получателя; проверяет активность получателя на текущий момент.если не найдено ни одного активного получателя, то передача уведомления не требуется, завершение сценария для данной записи измененного ресурса.
иначе, найден один или более активных получателей, переход к выполнению следующего шага.
Система формирует сообщение (содержимое уведомления) для каждого получателя, определенного на шаге 1 (Раздел 2.3.5.3.6.5.3). При необходимости (если при регистрации получения уведомлений (Раздел 2.3.5.3.6.1) был заполнен раздел bag) получает дополнительные атрибуты измененного ресурса из витрины. Далее переходит к выполнению следующего шага.
Система отправляет уведомления параллельно каждому получателю (отправка уведомления выполняется методом post на адрес агента) и дожидается ответа:
если ответа не поступило в течение заданного таймаута или в ответе получена ошибка (400-500), то Система фиксирует попытку отправки (накопление счётчика) и переходит к выполнению следующего шага.
иначе, уведомление было успешно отправлено получателю, завершение сценария для данной записи измененного ресурса.
Система определяет требуется ли выполнить повторную отправку уведомления. Для этого сравнивает текущее значение счётчика попыток отправки уведомления с параметром, заданным в конфигурационном файле
application.yamlpush->retry->max_attempts:если максимальное количество попыток отправки уведомления превышено, то повторная отправка не требуется, Система сохраняет соответствующее сообщение об ошибке в лог, завершение сценария для данной записи измененного ресурса.
иначе, требуется повторная попытка отправки уведомления, Система возвращается к выполнению шага 3.
2.3.5.3.6.5.3. Описание формата уведомления
Элемент |
Описание |
|---|---|
agent |
Объект, содержащий информацию об агентах СМЭВ4 |
source |
мнемоника агента поставщика данных |
target |
мнемоника агента получателя уведомлений |
payload |
Сутевые данные уведомления |
type |
Тип уведомления. Заполняется значение |
source |
Мнемоника источника данных измененного ресурса |
entity |
Данные, полученные из стэйт машины. Содержит следующие атрибуты:
|
push_id |
Идентификатор уведомления |
Пример:
{
"notification": {
"agent": {
"source": "zdrav777",
"target": "epgu"
},
"payload": {
"type": entity
"source": "prostore",
"entity": {
"resource": "books",
"entity_id": 25,
"state": "received",
"updated_at": "2023-11-23 12:25:31",
"bag": {
"sample_field1": "sample_value"
}
}
},
"push_id": "UUID"
}
}
2.3.5.3.6.6. Регистрация метода для получения уведомлений на стороне клиента
Для того, чтобы потребитель имел возможность получать уведомления об изменении данных витрины, ему необходимо:
Развернуть на своей стороне REST-сервис, в котором реализовать метод
POST/api/v1/smevql/notify;Настроить REST-сервис для взаимодействия с Агентом СМЭВ4 Потребителя;
Зарегистрировать REST-сервис в СМЭВ4;
Добавить критерии доступа (права поставщику данных) для запросов к развернутому REST-сервису;
Выполнить процедуру регистрации получения уведомлений в СМЭВ QL.
Элемент |
Описание |
|---|---|
agent |
Объект, содержащий информацию об агентах СМЭВ4 |
source |
мнемоника агента поставщика данных |
target |
мнемоника агента получателя уведомлений |
payload |
Сутевые данные уведомления |
type |
Тип уведомления. На текущий момент всегда заполняется значение |
source |
Мнемоника источника данных измененного ресурса |
entity |
Данные, полученные из стэйт машины. Содержит следующие атрибуты:
|
push_id |
Идентификатор уведомления |
Приммер:
{
"notification": {
"agent": {
"source": "zdrav777",
"target": "epgu"
},
"payload": {
"type": entity
"source": "prostore",
"entity": {
"resource": "books",
"entity_id": 25,
"state": "received",
"updated_at": "2023-11-23 12:25:31",
"bag": {
"sample_field1": "sample_value"
}
}
},
"push_id": "UUID"
}
}
2.3.5.3.6.7. Передача уведомления на основе сообщения топика Prostore
2.3.5.3.6.7.1. Общее описание
При изменении данных витрины, Prostore формирует событие типа WRITE_OK и передаёт его в системный топик status.event.
Примеры сообщений системного топика:
//пример сообщения для версионированной таблицы
key: {"datamart":"foo","datetime":"2024-02-05 09:52:40.65","event":"WRITE_OK","eventLogId":"f5706095-9dc9-445f-bc93-11683676e3b3"}
value: {"entity":"cat","cn":1,"ts":1707126760643000,"rowsAffected":1}
//пример сообщения для не версионированной таблицы
key: {"datamart":"foo","datetime":"2024-02-05 14:34:23.119","event":"WRITE_OK","eventLogId":"ebb8d74c-d0c2-4f2c-9177-872d1bcb64c6"}
value: {"entity":"catp","cn":null,"ts":null,"rowsAffected":1}
Данная функция позволяет передать уведомление об изменении данных витрины на основе событий системного топика Prostore.
2.3.5.3.6.7.2. Сценарий выполнения
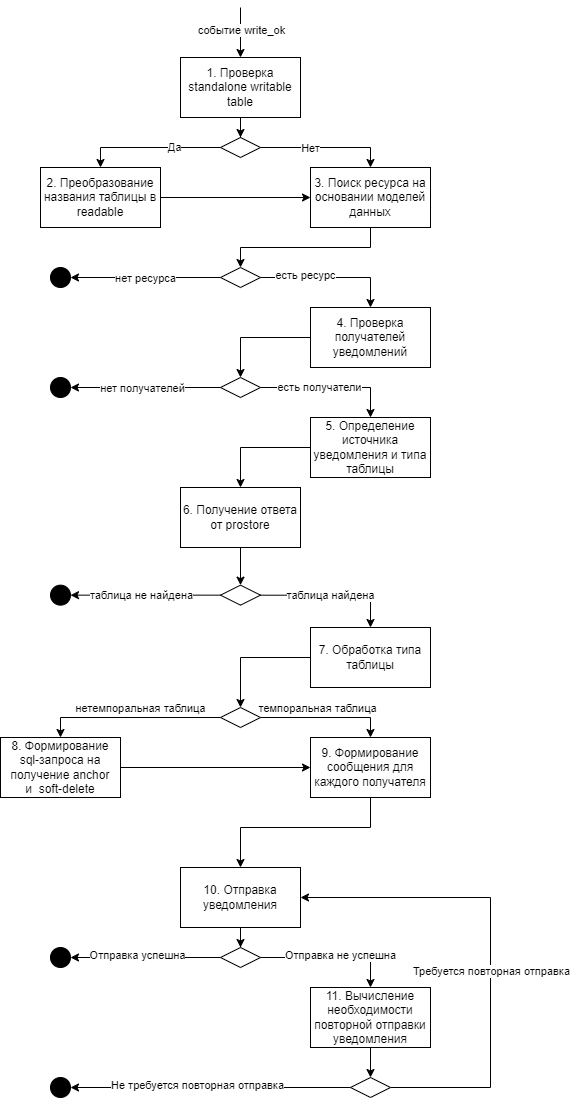
Рисунок - 2.24 Схема передачи уведомления на основе сообщения топика Prostore
Предварительные условия:
Получатель зарегистрировал REST-метод
POST/api/v1/smevql/notifyдля приёма уведомлений;В топике
status.eventпоявилось сообщение типаWRITE_OK.
Ход событий:
СМЭВ QL (далее Система) проверяет изменение данных выполнено в таблице вида standalone:
если да, то переходит к выполнению следующего шага
иначе, изменения не в
standaloneтаблице, переход к выполнению шага 3.
Система определяет
readableназваниеstandalone-таблицы. Для этого берет, полученное в сообщении названиеwritable, и ищет соответствующее ему readable название в блокеstandalone-tablesконфигурационного файлаapplication.yaml. Далее переходит к выполнению следующего шага.Далее Система выполняет поиск ресурса, к которому относится измененная таблица, на основе загруженных моделей данных:
если ресурс не найден, то Система сохраняет соответствующее сообщение в лог и завершает выполнение сценария.
иначе, ресурс определен, переход к выполнению следующего шага.
Система проверяет есть ли зарегистрированные получатели уведомлений при изменении заданного ресурса. Для этого читает из redis set c названием
push:consumers:by:resourceссылки на зарегистрированных получателей, для каждой ссылки: читает из redis hash данные получателя; проверяет активность получателя на текущий момент.если не найдено ни одного активного получателя, то передача уведомления не требуется, завершение сценария для данной записи измененного ресурса.
иначе, найден один или более активных получателей, переход к выполнению следующего шага.
Затем формирует запрос к Prostore для получения данных о существовании и типе изменённой таблицы. После чего переходит к выполнению следующего шага.
Система получает ответ с информацией об измененной таблице:
если таблица не существует в Prostore, то Система сохраняет соответствующее сообщение в лог и завершает выполнение сценария.
иначе, таблица существует в Prostore, переход к выполнению следующего шага.
Система обрабатывает значение полученного типа таблицы:
если таблица нетемпоральная (включая proxy-таблицы) , то переход к выполнению следующего шага.
иначе, таблица темпоральная, переход к выполнению шага 9.
Система формирует sql-запрос к Prostore для получения даты последнего изменения (anchor) и даты удаления (soft-delete) записи. После чего переходит к выполнению следующего шага.
Система формирует сообщение (содержимое уведомления) для каждого получателя, определенного на шаге 4 (формат уведомления см. Таблица 2.16). При этом если при регистрации получения уведомлений был заполнен раздел bag, то он не формируется. Далее переходит к выполнению следующего шага.
Система отправляет уведомления параллельно каждому получателю (отправка уведомления выполняется методом
POST/api/v1/smevql/notifyна адрес агента) и дожидается ответа:
если ответа не поступило в течение заданного таймаута или в ответе получена ошибка (400-500), то Система фиксирует попытку отправки (накопление счётчика) и переходит к выполнению следующего шага.
иначе, уведомление было успешно отправлено получателю, завершение сценария для данной записи измененного ресурса.
Система определяет требуется ли выполнить повторную отправку уведомления. Для этого сравнивает текущее значение счётчика попыток отправки уведомления с параметром, заданным в конфигурационном файле
application.yamlpush->retry->max_attempts:если максимальное количество попыток отправки уведомления превышено, то повторная отправка не требуется, Система сохраняет соответствующее сообщение об ошибке в лог, завершение сценария для данной записи измененного ресурса.
иначе, требуется повторная попытка отправки уведомления, Система возвращается к выполнению шага 10.
Элемент |
Описание |
|---|---|
agent |
Объект, содержащий информацию об агентах СМЭВ4 |
source |
мнемоника агента поставщика данных |
target |
мнемоника агента получателя уведомлений |
payload |
Сутевые данные уведомления |
type |
Тип уведомления. Заполняется значение batch, это означает, что уведомление инициировано событием системного топика Prostore |
source |
немоника источника данных измененного ресурса |
batch |
Данные, полученные из сообщения системного топика Prostore. Содержит следующие атрибуты:
|
push_id |
Идентификатор уведомления |
Пример:
{
"notification": {
"agent": {
"source": "zdrav777",
"target": "epgu"
},
"payload": {
"type": batch
"source": "prostor",
"batch": {
"resource": "books",
"updated_at": "2023-11-23 12:25:31",
"sys_cn": 134,
"anchor": null,
"soft-delete": null
}
},
"push_id": "UUID"
}
}
2.3.5.3.7. Работа с Регламентированными СМЭВ QL запросами
2.3.5.3.7.1. Создание СМЭВ QL РЗ
Для создания СМЭВ QL РЗ необходимо создать директорию соответствующую мнемонике запроса в директории queries в файловой
системе СМЭВ QL сервера.
Мнемоники СМЭВ QL РЗ являются регистронезависимыми. В случае обнаружения дублирующих запросов при
загрузке или валидации СМЭВ QL сервер возвращает warning с сообщением о дублировании РЗ. В случае дублирования должен
использоваться первый найденный РЗ, а другие игнорироваться.
В данной директории должны содержаться поддерриктории версий СМЭВ QL РЗ, в каждой из которых расположен файл шаблона
запроса query.json.
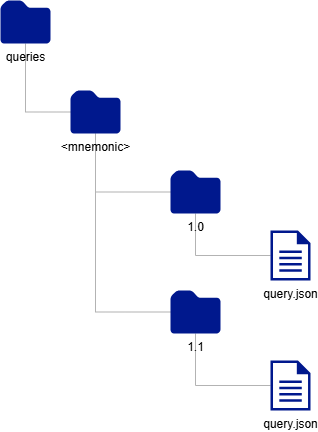
Рисунок - 2.25 Файловая система queries
2.3.5.3.7.1.1. Формат описания шаблона запроса
Шаблон запроса описывается в формате JSON и состоит из двух блоков: query и params.
Требовния к блоку запроса (query):
Блок должен соответствовать схеме для стандартного запроса данных, за исключением наличия мест для подстановки параметров;
Подстановка параметра в блок запроса (query) выполняется с использование двоеточия перед мнемоникой параметра («:month» из примера);
Не должен содержать параметры не описанные в блоке параметров;
Должен содержать все параметры, описанные в блоке параметров.
Требовния к блоку параметров (params):
Данный блок является опциональным (допустимо создание запросов без параметров);
Должен содержать массив параметров, для каждого из которых указывается:
а) Мнемоника (должна быть уникальна для данного РЗ, регистронезависимая);
б) Описание;
в) Тип параметра необходимо выбирать из JSON типов:
STRING
NUMBER
INTEGER
BOOLEAN
ARRAY
OBJECT
Другие блоки, кроме query и params в шаблоне запрещены.
Пример определения СМЭВ QL РЗ:
{ // аналогично блоку query в запросе к СМЭВ QL серверу POST /data
"query": {
"ticket": {
"conditions": {
// подстановка параметров
"month": ":month"
},
"attributes": ["id", "price"]
}
},
// блок описания параметров
"params": [{
"mnemonic": "month",
"descripton": "Месяц за который необходимо выгрузить статистику",
"type": "INTEGER"
}
]
}
2.3.5.3.7.2. Создание новой версии СМЭВ QL РЗ
Добавление новых версий СМЭВ QL РЗ производится Администратором сервиса в ручную.
Для этого необходимо в директории соответствующей мнемонике запроса создать новую поддиректорию с номером версии и новым
файлом query.json.
При добавлении версии СМЭВ QL РЗ не требуется какое-либо изменение модели данных СМЭВ QL.
2.3.5.3.7.3. Проверка валидности СМЭВ QL РЗ
Функция валидации СМЭВ QL РЗ вызывается вручную Администратором сервиса из консоли, командой:
./smevql test query <query-name1>.<major_version>.<minor_version> <query-name2>.<major_version>.<minor_version> ... | all
При этом проверяется
список СМЭВ QL РЗ
<query-name1>.<major_version>.<minor_version> <query-name2>.<major_version>.<minor_version> ...;все СМЭВ QL РЗ, при выборе опции
all.
Каждый из РЗ проверяется на соответствие формату описания, а также на наличие дублей.
2.3.5.4. Компонентная модель СМЭВ QL сервера
2.3.5.4.1. Общее представление
СМЭВ QL сервер представляет собой бэк-энд сервис, состоящий из определенного набора функциональных модулей, файловой системы (набор папок и yaml-файлов) и персистентного хранилища, реализованного на Redis. Для обращения к СМЭВ QL серверу используется набор методов OpenAPI.
2.3.5.4.2. Схема
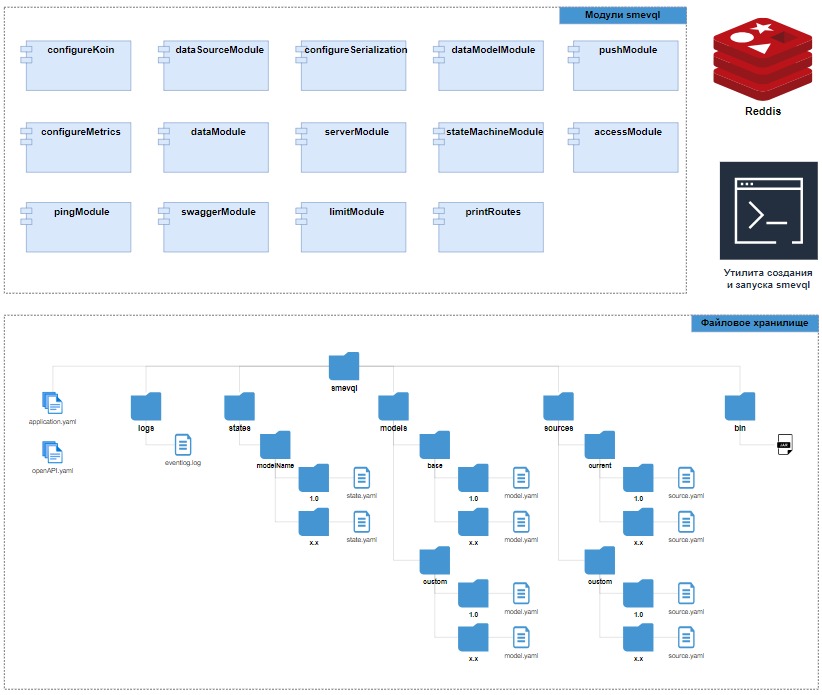
Рисунок - 2.26 Компонентная модель СМЭВ QL сервера
2.3.5.4.3. Описание компонентов
Компонент |
Описание |
|---|---|
Утилита создания и запуска smevql |
Утилита, позволяющая в терминальном режиме запускать команды для создания и запуска экземпляра СМЭВ QL сервера, а так же выполнять операции по работе с ключевыми сущностями СМЭВ QL (генерация моделей данных, подключение источников данных и т.д.). Перечень доступных команд:
|
Reddis |
Хранилище персистентных данных СМЭВ QL сервера. |
Модули smevql |
Набор функциональных модулей СМЭВ QL сервера, реализующих его логику работы. Перечень и функциональное назначение модулей в Таблица 2.18 |
Файловое хранилище |
Структура папок и файлов СМЭВ QL сервера. Хранит настройки и описание моделей ключевых сущностей: модель данных, описание источников данных, машины состояний и пр. |
Модуль |
Функциональное назначение |
|
|---|---|---|
1 |
configureKoin |
|
2 |
configureSerialization |
|
3 |
configureMetrics |
|
4 |
accessModule |
Управление доступами потребителей данных. Конфигурирование «чёрных» и «белых» списков |
5 |
serverModule |
|
6 |
pingModule |
Проверка доступности СМЭВ QL сервера |
7 |
limitModule |
Управление лимитами входящих запросов от потребителей данных |
8 |
dataSourceModule |
Управление моделями источников данных |
9 |
dataModelModule |
Управление моделями данных |
10 |
dataModule |
Обработка входящих запросов |
11 |
stateMachineModule |
Управление моделями, запуск и исполнение машин-состояний |
12 |
pushModule |
Управление подписчиками на изменение данных витрины и передача уведомлений |
13 |
swaggerModule |
Создание и предоставление внешнему клиенту описания openAPI спецификации |
14 |
printRoutes |
Запись путей вызова обработчиков |
2.3.6. Стандартный загрузчик
Примечание
Модуль входит в состав конфигурации Стандарт и Лайт
2.3.6.1. Общее описание
2.3.6.1.1. Назначение
Стандартный загрузчик (Standard-loader) - модуль управления данными (загрузка и/или удаление) в Витрине данных, формирования количественных оценок качества данных Витрины в части соответствия источнику данных.
Основные решаемые проблемы:
загрузка и удаление данных в Витрине (Раздел 2.3.6.3.1);
сверка данных ИС Источника и Витрины, в том числе автоматическая корректировка данных в Витрине (Раздел 2.3.6.3.2).
2.3.6.1.2. Термины и определения
В Таблица 2.19 приведено описание специфичных терминов стандартного загрузчика.
Термин |
Сокращение |
Определение |
|---|---|---|
Задание на загрузку |
Задание на загрузку данных из Источника в Витрину, в котором определяется каким запросом запрашивается информация, и в какие Витрины и таблицы загружаются данные. |
|
Задание сверки |
Задание для сверки данных между Источником и Витриной, в котором определяется Источники данных, запросы на получение контрольных сумм записей (хэшей), запросы на получение данных для корректирующей загрузки. |
|
Информационная система |
ИС |
Совокупность данных в базах, а также информационных технологий и технических средств, обеспечивающих их обработку и функционирование как единого целого для решения определенных задач. Отражается в метаданных Стандартного загрузчика, для группировки Источников данных. |
Исключение из корректировки |
Набор первичных ключей данных, по которым были попытки корректировки, но при повторной сверке остались Расхождения. |
|
Источник |
Конкретный источник данных для загрузки, в рамках ИС Источника. |
|
Корректирующая загрузка |
Загрузка данных из Источника в Витрину для устранения устойчивых, в том числе добавления и удаления записей. |
|
Модульный монолит |
Модулит |
Архитектурный подход, при котором приложение формируется из независимых компонентов, взаимодействующих между собой через определенные интерфейсы, а не напрямую. |
Попытка корректировки |
Набор первичных ключей данных, для которых инициирована корректирующая загрузка: Устойчивые расхождения текущего Сеанса сверки за вычетом справочника исключений из корректировки |
|
Расписание загрузки |
Расписание, задающее периодичность создания Сеансов загрузки данных в режиме Pull. |
|
Расписание сверки |
Расписание, задающее периодичность создания Сеансов сверки. |
|
Результат сравнения |
Расхождение |
Первичные найденные расхождения между данными Источника и Витрины на основании единичного Сеанса сверки. |
Сверка |
Совокупность действий по:
|
|
Сеанс загрузки |
Информация о факте и результатах загрузки данных. Может создаваться при:
|
|
Сеанс сверки |
Информация о факте и результатах сверки данных. |
|
Сервис Стандартного загрузчика |
Сервис |
Обособленная функциональная часть Стандартного загрузчика, способная запускаться и работать как на отдельной, так и вместе с другими компонентами на общей виртуальной машине Java |
Сервис чтения данных |
Reader (Ридер) |
Сервис Стандартного загрузчика, обеспечивающий чтение или прием данных из ИС Источника. |
Событие |
Запись о факте выполнения важных действий одним из сервисов стандартного загрузчика. |
|
Устойчивое расхождение |
Расхождения, сохраняющиеся длительное время и не спровоцированные изменениями данных в Источнике. Вычисляются на основании Расхождений двух идущих подряд Сеансов сверки. |
|
Форматно-логический контроль |
ФЛК |
Процесс проверки данных на соответствие заданным форматам и логическим правилам. |
Pull |
Режим работы при котором инициализация загрузки производится со стороны Reader. |
|
Push |
Режим работы, при котором инициализация загрузки производится ИС Источника или Оператором. При этом производится обращение к интерфейсу одного из Reader. При этом производится обращение к интерфейсу одного из Reader. |
2.3.6.1.3. Схема взаимодействия
Приложение реализовано в виде модулита:
в рамках одной JVM могут запускаться как несколько, так и один сервис;
часть ридеров при необходимости можно вынести в отдельное независимое приложение и разместить на стороне ИС Источника (load-manager-reader). В этом случае для управления развертыванием удаленных ридеров используется специальный компонент - Deployer;
Реализованные сервисы модулита:
Manager - основной управляющий сервис, выполняющий функции:
конфигурирования удаленных ридеров;
создания Сеансов загрузки данных;
назначения сеансов для выполнения на других компонентах.
Deployer - сервис, управляющий развертыванием Reader, в том числе удаленных, развернутых на отдельной JVM по конфигурации, полученной от Manager.
Comparator - сервис, осуществляющий функцию Сверки.
Reader - сервис, обеспечивающий чтение или прием из ИС Источника, преобразование к формату avro (при необходимости) и передачу данных в Buffer. В зависимости от своих настроек может подключаться к одному из видов Источников для чтения данных в рамках Сеанса загрузки (режим pull) или ждать обращения ИС Источника (режим push).
Сервис Reader поддерживает следующие сочетания типов Источника и режимов работы:
JDBC: Pull;
REST: Pull, Push;
Folder: Pull.
FLK - сервис осуществляющий форматно-логический контроль данных перед загрузкой.
Buffer - сервис, отвечающий за запись, изменение и удаление данных во временном хранилище по запросам от других компонентов.
Uploader - сервис загрузки готовых данных из временного хранилища в Витрину.
Наиболее простой вариант размещения Загрузчика, ИС Источника и Витрины в одном ЦОД приведен на Рисунок - 2.27, стрелками обозначено основное направление передачи данных.
Данный вариант подходит для небольших Витрин данных, где важна простота настройки и экономия ресурсов.
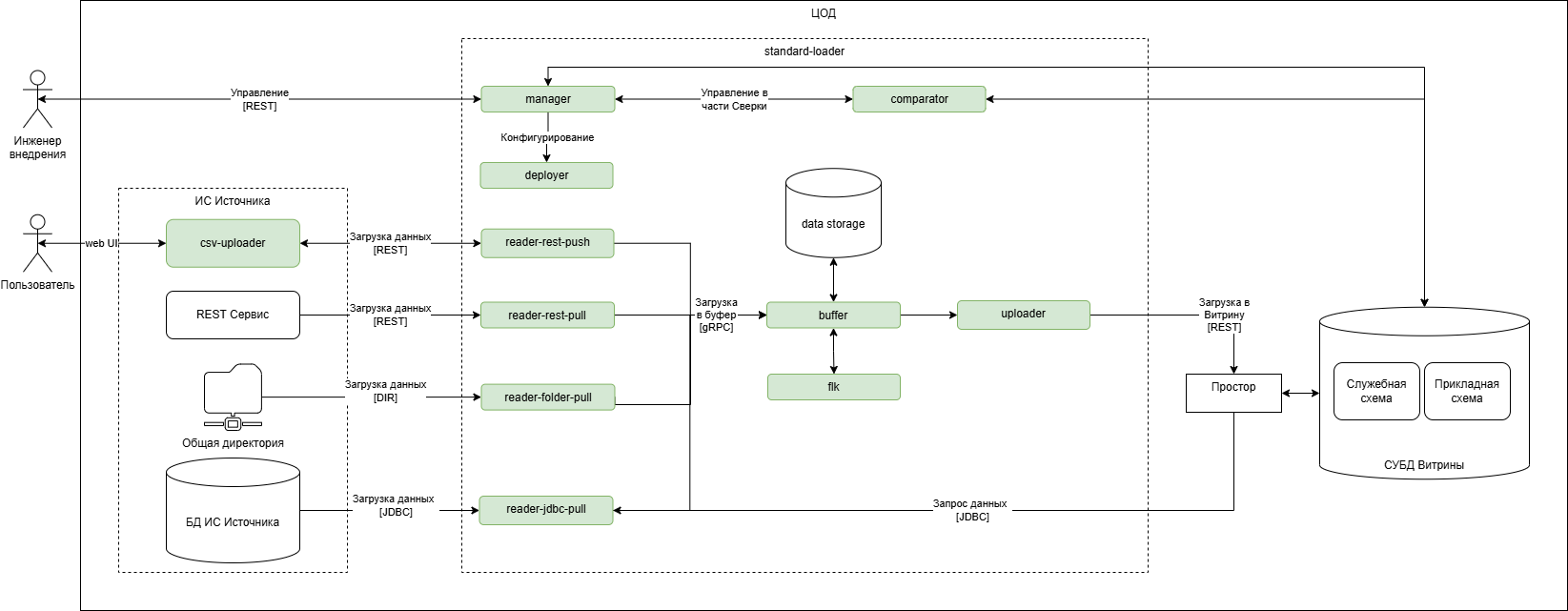
Рисунок - 2.27 Вариант развертывания стандартного загрузчика в одном ЦОД
Рисунок - 2.28 отображает вариант с размещением Витрины и ИС Источников в разных ЦОД (стрелками обозначено основное направление передачи данных). В данном случае на стороне ИС Источника разворачивается дополнительный экземпляр Стандартного загрузчика для чтения данных.
Данный вариант является основным для Витрин данных, развернутых на Гостех.
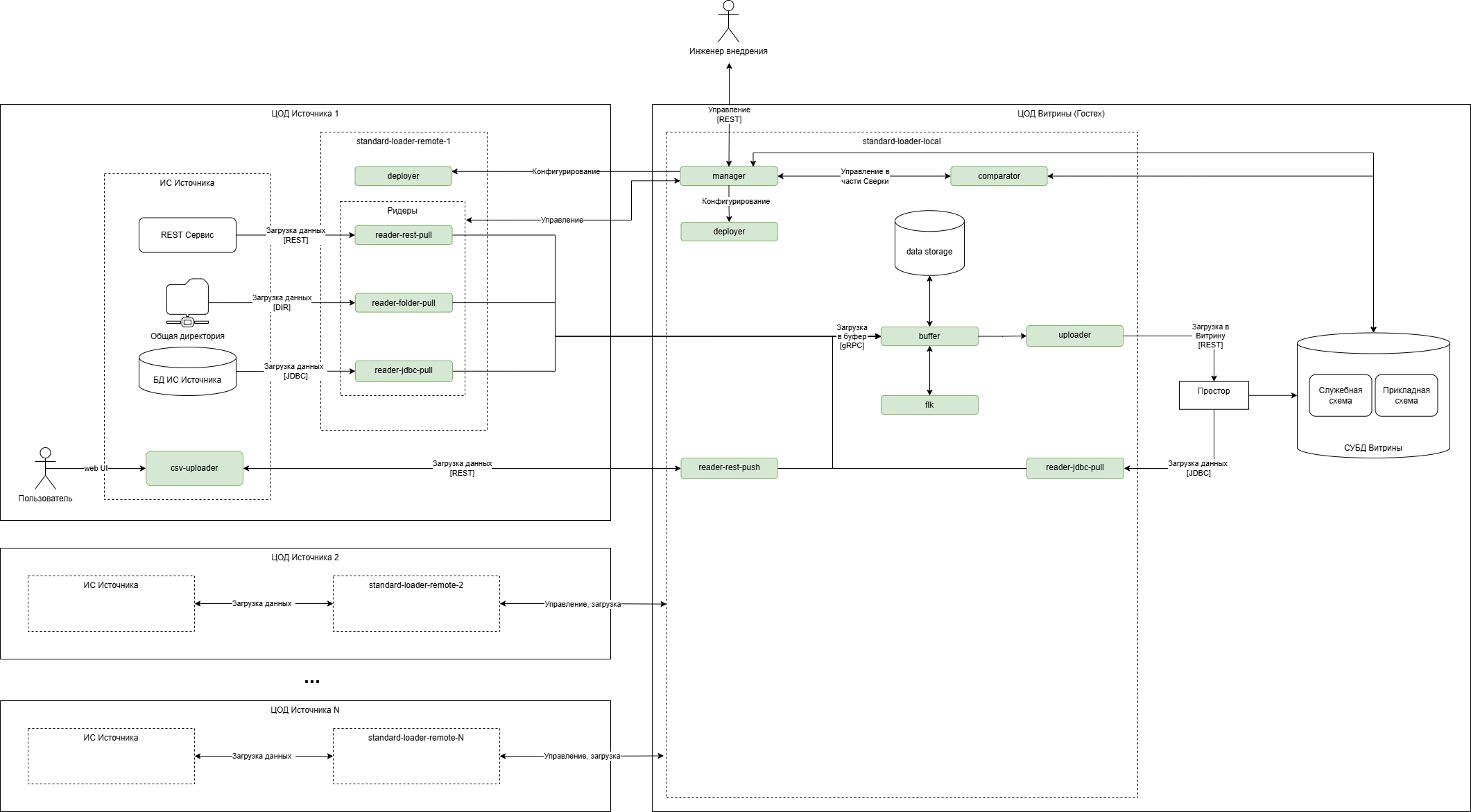
Рисунок - 2.28 Вариант развертывания стандартного загрузчика с дополнительным экземпляром
2.3.6.1.4. Ограничения и особенности работы
Поддерживается загрузка только плоских данных (нет вложенных объектов), без необходимости трансформации, т.е. структура данных, получаемая от Источника должна полностью соответствовать структуре данных в Витрине.
Примечание
В случае JDBC Источника доступна трансформация данных Источника к виду, требуемому для Витрины, SQL запросом.
Связь между основной частью Стандартного загрузчика и вынесенными Компонентами для чтения данных может быть только односторонней: Reader → основной частью Стандартного загрузчика (для возможности использования приложения в Гостех).
Функционал сверки поддерживается только для загрузки данных из ИС Источника по протоколу JDBC, при наличии доступа к полному набору данных.
Удаленные ридеры могут работать в различных часовых поясах. Для согласованности времен, при записи данных в служебную БД, временные отметки приводятся к единому часовому поясу, который можно настроить через параметр конфигурации (Раздел 2.2.7.1).
Аутентификация клиента на Компоненте чтения данных не реализована. При необходимости аутентификация должна выполняться внешними сервисами.
При переключении между загрузчиками рекомендуется удалять локальную БД CSV-Uploader для исключения недостижимых идентификаторов.
2.3.6.2. Метаданные стандартного загрузчика
2.3.6.2.1. Объекты конфигурации компонентов
2.3.6.2.1.1. information_system
Назначение: хранение данных об ИС Источников.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника ИС Источника |
EGD777 |
description |
varchar |
Человекочитаемое название ИС Источника |
ЭЖД региона 777 |
2.3.6.2.1.2. deployer
Назначение: хранение данных о сервисах Deployer, связанных с определенной Информационной системой.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника Deployer |
deployer_egd |
|
true |
is_mnemonic |
varchar |
true |
Ссылка на мнемонику ИС Источника (Information_system), для которой разворачивается Deployer |
EGD777 |
|
enabled |
boolean |
true |
Флаг активности Deployer. При необходимости можно отключить целый Deployer без его удаления из БД. |
true |
2.3.6.2.1.3. reader
Назначение: хранение данных о Reader’ах, необходимых для запуска определенным Deployer.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника сервиса |
reader_jdbc_1 |
|
true |
deployer_mnemonic |
varchar |
true |
Cсылка на мнемонику Deployer, который должен развернуть сервис |
deployer_egd |
|
data_flow_type |
varchar |
Тип потока данных, с которым работает сервис |
pull |
|||
source_type |
varchar |
Тип источника, который поддерживает сервис. Заполняется только для Reader типа
|
jdbc |
|||
enabled |
boolean |
true |
Флаг активности Deployer. При необходимости можно отключить целый Deployer без его удаления из БД. |
true |
||
true |
config_mnemonic |
varchar |
true |
Ссылка на специфичную конфигурацию сервиса |
reader_config |
2.3.6.2.1.4. config
Назначение: хранение данных о конфигурации Reader’ов.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника конфигурации |
reader_config |
|
config |
varchar |
true |
Конфигурация компонента в формате YAML (соответствуют секции readers.[].config общего файла настройки, без элемента config |
2.3.6.2.2. Объекты загрузки
2.3.6.2.2.1. source
Назначение: хранение данных об Источниках данных.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника Источника данных |
DB_EGD |
|
description |
varchar |
Человекочитаемое название Источника данных |
База данных ЭЖД |
|||
true |
is_mnemonic |
varchar |
true |
Cсылка на мнемонику ИС Источника |
EGD777 |
|
type |
varchar |
true |
Тип источника: |
jdbc |
||
source_connect |
varchar |
true |
Параметры подключения к источнику в формате JSON |
{
"connect_jdbc": {
"url": "jdbc:postgresql://localhost:5432/postgres",
"user": "postgres",
"password": "postgres"
}
}
или
{
"connect_jdbc": {
"url": "jdbc:prostore://localhost:9090"
}
}
или
{
"connect_rest": {
"protocol": "http",
"host": "localhost",
"port": 9098,
"baseUrl": "/api/v1",
"auth": {
"basic": {
"user": "{USER.ENV}",
"password": "{PASS.ENV}"
}
}
}
}
или
{
"connect_folder": {
"_comment_input_path": "директория с файлами для загрузки",
"input_path": "/data/input",
"_comment_process_path": "директория для загружаемых файлов",
"process_path": "/data/process",
"_comment_limit_files": "максимальное число файлов, загружаемых в одном сеансе",
"limit_files": 10,
"_comment_sort": "используемая сортировка, допустимые значения: name or created",
"sort": "name",
"_comment_when_complete": "действие при успешном чтении файла, допустимые значения: move_to or delete",
"when_complete": {
"move_to": {
"path": "/data/readed_success"
}
},
"_comment_exceptionally": "действие при ошибке чтения файла, допустимые значения: move_to or delete",
"exceptionally": {
"move_to": {
"path": "/data/readed_fail"
}
}
}
}
|
2.3.6.2.2.2. pull_task
Назначение: хранение данных о Задания на загрузку данных в режиме Pull.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника Задания на загрузку |
upload_students |
|
action |
varchar |
true |
Тип операции |
upsert |
||
true |
source_mnemonic |
varchar |
true |
Внешний ключ, ссылка на мнемонику источника (Source) |
pgEGD777 |
|
request |
json |
true |
Запрос к источнику в формате JSON |
{ request_sql:
{query: "select * from a" }
}
или
{ request_rest:
{method: "GET",
path: "/student/:id",
body: null,
parameters: { id: "12345"}
}
}
или
пустая строка для folder reader |
||
target_type |
varchar |
true |
Тип целевой базы. Enum: application-database (загрузка данных в Витрину, в т.ч. выравнивающая загрузка), service-database (загрузка хэшей в сервисную БД для Сверки) |
application-database |
||
target_datamart |
varchar |
true |
Целевая витрина данных |
demo_dev |
||
target_table |
varchar |
true |
Целевая таблица |
students |
||
description |
varchar |
Человекочитаемое описание задачи |
Выгрузка учеников |
2.3.6.2.2.3. schedule
Назначение: хранение данных о Расписаниях загрузки данных.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника расписания |
upload_students_hourly |
|
description |
varchar |
Описание расписания |
Выгрузка студентов каждый час |
|||
enabled |
boolean |
true |
Флаг активности расписания |
true |
||
true |
task_mnemonic |
varchar |
true |
Cсылка на Задания на загрузку (PullTask) |
upload_students |
|
cron |
varchar |
true |
Выражение CRON для периодического запуска |
1 * * * * |
||
one_time |
boolean |
Флаг для однократного выполнения |
false |
|||
overlap-mode |
varchar |
true |
Режим обработки пересекающихся запусков
Для one_time расписаний применимо только
|
skip |
2.3.6.2.2.4. session
Назначение: хранение информации о созданных Сеансах загрузки.
Жизненный цикл: создается и очищается приложением через конфигурироемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор сессии. Формируется при создании записи, линейно нарастает, используется для обеспечиения FIFO в рамках таблицы |
1025 |
|
source_mnemonic |
varchar |
Мнемоника источника |
abs5 |
|||
action |
varchar |
true |
Выполняемое действие: |
upsert |
||
flk_mode |
varchar |
true |
Режим ФЛК для данного Сеанса. Заполняется менеджером при создании сеанса, используется чтобы передать в сервис FLK нужный режим |
warning |
||
component_mnemonic |
varchar |
Мнемоника сервиса, обрабатывающего Сеанс в данный момент времени |
reader_jdbc_1 |
|||
component_instance_id |
varchar (UUID) |
Идентификатор экземпляра сервиса |
019b0713-0ff5-7935-8578-37af8636e928 |
|||
target_datamart |
varchar |
true |
Целевая витрина данных |
demo_dev |
||
target_table |
varchar |
true |
Целевая таблица |
students |
||
source_connect |
json |
Параметры подключения к источнику. При |
||||
schedule_mnemonic |
varchar |
Ссылка на расписание, которое создало сеанс, при push-инициализации сеанса = null |
upload_students_hourly |
|||
file_sz |
int |
true |
Размер файла в байтах |
1532 |
||
offset |
bigint |
Смещение для чтения данных |
1 |
|||
status_code |
int |
true |
Текущий статус сессии |
300 |
||
error_code |
integer |
Код ошибки в случае неудачи |
5001 |
|||
error_message |
text |
Текстовое описание ошибки |
Ошибка подключения к источнику |
|||
create_ts |
timestamp |
true |
Время создания сессии |
2025-08-27 10:00:00 |
||
finish_ts |
timestamp |
Время завершения сессии |
2025-08-27 10:05:00 |
|||
for_system_time |
timestamp |
true |
Метка времени для удаления истории операций. Применимо только для action truncate. |
2019-12-23 15:15:14.736193 |
||
compare_session_id |
bigint |
Cсылка на идентификатор Сеанса сверки (СompareSession), в рамках которого создан Сеанс загрузки |
12345 |
|||
is_file_deleted |
boolean |
true |
Признак удаления файла из буфера,
значение по умолчанию |
true |
||
source_fields_metadata |
varchar |
Информация о типах полей в источнике данных в виде json (ключ - имя поля, значение - тип данных prostore). Данное поле не используется в REST API Данное поле не используется в REST API |
{
"name": "VARCHAR",
"code": "BIGINT"
}
|
2.3.6.2.2.5. event
Назначение: хранение информации о созданных Событиях загрузки.
Жизненный цикл: создается и очищается приложением через конфигурироемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор события. Генерируется на БД поэтому в составе события не передается. |
50178 |
|
code |
int |
true |
Код события |
5001 |
||
true |
session_id |
bigint |
Cсылка на идентификатор Сеанса (Session), в рамках которого произошло событие. |
upsert |
||
true |
component_mnemonic |
varchar |
true |
Cсылка на сервис (Component), создавший событие. |
reader_jdbc_1 |
|
component_instance_id |
varchar |
true |
Идентификатор экземпляра |
019b0713-0ff5-7935-8578-37af8636e928 |
||
event_ts |
timestamp |
true |
Временная метка события |
2025-08-27 10:01:00 |
||
message |
varchar |
true |
Сообщение события |
«Компонент назначен» |
||
error_code |
integer |
Код ошибки в случае неудачи |
||||
error_message |
varchar |
Дополнительные данные в формате JSON или YAML |
||||
status_code_from |
int |
Статус, в котором был сеанс до события |
100 |
|||
status_code_to |
int |
Статус, в который перешел сеанс после события |
101 |
|||
payload |
varchar |
Прикладные данные для Менеджера |
{"action":"upsert",
"datamart":"univer",
"table":"students",
"forSystemTime":null}
|
2.3.6.2.3. Объекты ФЛК
2.3.6.2.3.1. flk_conditions
Назначение: хранение проверок для целевых датамартов и таблиц.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API ФЛК.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
datamart |
varchar |
true |
Датамарт, в рамках которого применяются проверки. |
demo_dev |
|
true |
table |
varchar |
true |
Таблица, в рамках которой применяются проверки. |
students |
|
condidtions |
varchar |
true |
YAML представление условий |
fields:
birthday:
uniq: true
uniq-with:
- "code"
- "passport"
match: "(\\d{4})\\-(\\d{2})\\-(\\d{2})"
code:
in:
- "1"
- "2"
- "3"
- "4"
- "5"
- "6"
- "7"
- "8"
- "9"
- "10"
uniq: true
|
2.3.6.2.3.2. validation_error
Назначение: хранение информации о найденных в ходе проведения ФЛК ошибках.
Жизненный цикл: создается и очищается приложением через конфигурироемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор ошибки |
1 |
|
true |
session_id |
bigint |
true |
Ссылка на Сеанс, в рамках которого найдена ошибка |
1025 |
|
line |
integer |
true |
Номер строки в данных, где произошла ошибка |
154 |
||
field |
varchar |
true |
Имя поля с ошибкой |
age |
||
code |
varchar |
true |
Код ошибки ФЛК |
INVALID_FORMAT |
||
value |
text |
Значение, которое вызвало ошибку |
«abc» |
|||
message |
text |
true |
Описание ошибки |
Недопустимый формат числа |
2.3.6.2.4. Объекты сверки
2.3.6.2.4.1. compare_task
Назначение: хранение данных о Задания на сверку.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника задачи |
Compare1 |
|
true |
original_source_mnemonic |
varchar |
true |
Мнемоника источника мастер данных |
EGD777 |
|
true |
datamart_source_mnemonic |
varchar |
true |
Мнемоника источника витрины данных |
datamart_EGD777 |
|
original_request |
varchar |
true |
Запрос к источнику мастер данных в формате JSON для получения хешей (контрольных сумм) |
{ request_sql:
{query: "select id::VARCHAR as pk_cortege, ('x'||md5(row(name,age)::VARCHAR))::bit(64)::bigint as hash_value from foo.cat1" }
}
|
||
datamart_request |
varchar |
true |
Запрос к витрине данных в формате JSON, запрос для получения хешей (контрольных сумм) |
{ request_sql:
{query: "select id::VARCHAR as pk_cortege, ('x'||md5(row(name,age)::VARCHAR))::bit(64)::bigint as hash_value from foo.cat1" }
}
|
||
сorrection_load_request |
varchar |
true |
Запрос корректирующей загрузки для обновления и добавления записей, задается если нужна корректирующая нужна |
{ request_sql:
{query: "select a, b, c from aaa.fff where a in(: pk_keys) " }
}
|
||
сorrection_delete_request |
varchar |
false |
Запрос корректирующей загрузки для удаления записей, задается если нужна корректирующая загрузка |
{ request_sql:
{query: "select unnest(STRING_TO_ARRAY(:pk_keys,',')) pkfield " }
}
|
||
target_datamart |
varchar |
true |
Целевой датамарт для выравнивания |
|||
target_table |
varchar |
true |
Целевая таблица для выравнивания |
|||
description |
varchar |
true |
Описание сверки заполняется опционально, позволяет указать кто создал сверку и для каких целей |
Сверка важных атрибутов, создал Петров Петр Петрович 1 октября 2025 года, чтобы спать спокойно |
Примечание
Чтобы разложить наборы первичных ключей из склейки на ПГ можно пользоваться конструкцией:
select split_part(unnest(STRING_TO_ARRAY('1_2,15_17',',')),'_',1) a, split_part(unnest(STRING_TO_ARRAY('1_2,15_17',',')),'_',2) b
В Prostore данная функция отсутствует.
2.3.6.2.4.2. compare_schedule
Назначение: хранение данных о Расписании сверки.
Жизненный цикл: создается, изменяется и удаляется Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
mnemonic |
varchar |
true |
Мнемоника расписания сверки |
CompareScheduler1 |
|
true |
compare_task_mnemonic |
varchar |
true |
Мнемоника задачи сверки |
Compare1 |
|
cron |
varchar |
true |
CRON-выражение для расписания |
0 0 1 * * ? |
||
enabled |
boolean |
true |
Признак активности расписания |
true |
||
one_time |
boolean |
true |
Признак однократного запуска |
false |
||
description |
varchar |
Комментарий к расписанию |
Ежедневная сверка |
2.3.6.2.4.3. compare_session
Назначение: хранение данных о Сеансах сверки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Идентификатор сессии |
12345 |
|
true |
compare_schedule_mnemonic |
varchar |
true |
Мнемоника расписания сверки |
CompareScheduler1 |
|
create_ts |
timestamp |
true |
Дата и время начала сессии |
2025-09-30 15:00:05.000 |
||
component_mnemonic |
varchar |
true |
Мнемоника компаратора, исполняющего сверку |
comparator |
||
component_instance_id |
varchar |
true |
Идентификатор компаратора исполняющего сверку |
019b0713-0ff5-7935-8578-37af8636e928 |
||
finish_ts |
timestamp |
Дата и время окончания сессии |
2025-09-30 15:55:00.000 |
|||
status_code |
int |
true |
Статус сессии |
350 |
||
error_code |
integer |
Код ошибки в случае неудачи |
||||
error_message |
text |
Текстовое описание ошибки |
2.3.6.2.4.4. compare_event
Назначение: хранение данных о Событиях сверки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Уникальный идентификатор события |
50178 |
|
code |
int |
true |
Код события |
5001 |
||
true |
compare_session_id |
bigint |
Cсылка на идентификатор Сеанса сверки (СompareSession), в рамках которого произошло событие. |
1234 |
||
true |
component_mnemonic |
varchar |
true |
Cсылка на сервис (Component), создавший событие. |
reader_jdbc_1 |
|
component_instance_id |
varchar |
true |
Идентификатор экземпляра |
019b0713-0ff5-7935-8578-37af8636e928 |
||
event_ts |
timestamp |
true |
Временная метка события |
2025-08-27 10:01:00 |
||
message |
varchar |
true |
Сообщение события |
«Компонент назначен» |
||
error_code |
integer |
Код ошибки в случае неудачи |
||||
error_message |
varchar |
Дополнительные данные в формате JSON или YAML |
||||
status_code_from |
int |
Статус, в котором был сеанс до события. |
200 |
|||
status_code_to |
int |
Статус, в который перешел сеанс после события. |
201 |
|||
payload |
varchar |
Прикладные данные для Менеджера |
2.3.6.2.4.5. compare_result
Назначение: хранение данных о Результатах сверки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Идентификатор записи |
1000 |
|
pk_cortege |
varchar |
true |
Кортеж PK прикладной записи, сериализованный в строку через разделитель |
019b0713-0ff5-7935-8578-37af8636e928 |
||
true |
compare_session_id |
bigint |
true |
Идентификатор сессии сравнения |
12345 |
|
difference_type |
int |
true |
Код различия, ENUM 1 - различные хеш суммы; 2 - данных нет в витрине; 3 - данных нет в источнике. |
1 |
||
hash_original |
bigint |
хеш мастер-записи, null в случае если difference_type = 3 (данных нет в источнике) |
3e968837-add7-4a59-9e65-293c6325b32c |
2.3.6.2.4.6. stable_difference
Назначение: хранение данных об Устойчивых расхождениях.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
true |
compare_session_id |
bigint |
true |
Идентификатор сессии сверки |
300 |
true |
true |
compare_session_prev_id |
bigint |
true |
Идентификатор предыдущей сессии сверки |
299 |
true |
pk_cortege |
varchar |
true |
Кортеж первичных ключей |
019b0713-0ff5-7935-8578-37af8636e928 |
|
difference_type |
int |
true |
Код различия, ENUM 1 - различные хеш суммы; 2 - данных нет в витрине; 3 - данных нет в источнике. |
1 |
||
true |
compare_task_mnemonic |
varchar |
true |
Мнемоника задания сверки |
Compare1 |
2.3.6.2.4.7. correction_attempt
Назначение: хранение данных о Попытках корректировки.
Жизненный цикл: создается и очищается приложением через конфигурируемое время.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Идентификатор попытки исправления |
12345 |
|
true |
compare_session_id |
bigint |
true |
Идентификатор Сеанса сверки |
300 |
|
true |
pk_cortege |
varchar |
true |
Кортеж первичных ключей |
019b0713-0ff5-7935-8578-37af8636e928 |
|
create_ts |
timestamp |
true |
Дата и время создания записи |
2025-09-30 15:00:05.000 |
||
true |
session_id |
bigint |
true |
Идентификатор Сеанса загрузки, в рамках которого корректировался кортеж первичных ключей |
654 |
|
true |
difference_type |
int |
true |
Тип различия |
1 |
2.3.6.2.4.8. correction_exception
Назначение: хранение данных об Исключениях из корректировки.
Жизненный цикл: создается приложением, предназначены для ручного разбора и удаления Пользователем через API управления метаданными.
РК |
FK |
Имя поля |
Тип |
Not null |
Описание |
Пример |
|---|---|---|---|---|---|---|
true |
id |
bigint |
true |
Идентификатор исключения |
4f968837-add7-4a59-9e65-293c6325b32d |
|
pk_cortege |
varchar |
true |
Кортеж первичного ключа исключения |
019b0713-0ff5-7935-8578-37af8636e928 |
||
original_source_mnemonic |
varchar |
true |
Мнемоника источника мастер данных |
EGD777 |
||
compare_session_id |
bigint |
true |
Идентификатор сеанса сверки в рамках которого выявлено исключение |
1001 |
||
true |
compare_task_mnemonic |
varchar |
true |
Мнемоника задания сверки |
Compare1 |
2.3.6.3. Функции стандартного загрузчика
2.3.6.3.1. Загрузка данных
В Таблица 2.39 приведен перечень операций, выполняемых стандартным загрузчиком с данными Витрины.
Операция |
Обозначение в метаданных |
Метод API подмодуля чтения данных |
Тип таблицы Prostore |
Поле sys_op |
Описание |
|---|---|---|---|---|---|
Загрузка данных |
upload |
…/upload |
Любой |
Недопустимо |
Выполняется загрузка или обновление данных для переданного набора первичных ключей |
Логическое удаление |
delete |
…/delete |
Любой |
Недопустимо |
Удаление данных по переданному набору первичных ключей, при этом для логических таблиц Витрины данные только помечаются как удаленные. |
Модификация данных |
modify |
…/modify |
Логическая |
Требуется включать со следующими значениями: 0 - загрузка данных; 1 - удаление данных. |
Cовмещение загрузки и логического удаления в одной операции. |
Удаление исторических данных |
truncate |
…/truncate |
Для полного удаления данных - любой. Для удаления исторических данных с момента времени - Логическая. |
Недопустимо |
Удаление данных, включая исторические. При использовании
|
Операции с данными могут быть инициализированы:
со стороны Витрины данных (
pull):однократно;
по расписанию.
ИС Источника (
push).
Для инициализации загрузки со стороны Стандартного загрузчика (режим pull) пользователю необходимо с помощью REST-API Стандартного загрузчика (см. раздел с API) или с
помощью прямых SQL-запросов к служебной БД (при наличии доступа) создать объекты:
Информационная система;
Источник нужного типа (source) с привязкой к нужной Информационной системе;
Задание на загрузку (pull_task) для созданного Источника;
Расписание (schedule) срабатывания для созданного Задания на загрузку.
После создания данных объектов нужно развернуть Reader с типом потока данных
pull, того же Типа источника и связанный с той же Информационной системой.Расписание (schedule) срабатывания для созданного Задания на загрузку.
Пример настроек для pull режима загрузки данных:
REST
-- Создание информационной системы
POST /api/v1/information-systems
{
"description": "Моя информационная система",
"mnemonic": "my_information_system"
}
-- Создание Источника с типом folder. JSON-объект в поле source_connect должен передаваться в виде строки,
-- для этого необходимо добавить escape символы
POST /api/v1/sources
{
"description": "Мой Источник",
"is_mnemonic": "my_information_system",
"type": "folder",
"source_connect": "\n{\n \"connect_folder\": {\n \"_comment_input_path\": \"директория с файлами для загрузки\",\n \"input_path\": \"/upload/input\",\n \"_comment_process_path\": \"директория для загружаемых файлов\",\n \"process_path\": \"/upload/process\",\n \"_comment_limit_files\": \"максимальное число файлов, загружаемых в одном сеансе\",\n \"limit_files\": 10,\n \"_comment_sort\": \"используемая сортировка, допустимые значения: name or created\",\n \"sort\": \"name\",\n \"_comment_when_complete\": \"действие при успешном чтении файла, допустимые значения: move_to or delete\",\n \"when_complete\": {\n \"move_to\": {\n \"path\": \"/upload/read_success\"\n }\n },\n \"_comment_exceptionally\": \"действие при ошибке чтения файла, допустимые значения: move_to or delete\",\n \"exceptionally\": {\n \"move_to\": {\n \"path\": \"/data/read_fail\"\n }\n }\n }\n}\n",
"mnemonic": "my_source"
}
-- Создание Задания на загрузку
POST /api/v1/pull-tasks
{
"action": "upsert",
"source_mnemonic": "my_source",
"request": "",
"target_type": "application-database",
"target_datamart": "foo",
"target_table": "cat1",
"description": "Мое задание на загрузку",
"mnemonic": "my_task"
}
-- Создание Расписания
POST /api/v1/schedules
{
"description": "Мое расписание",
"enabled": true,
"task_mnemonic": "my_task",
"cron": "*/5 * * * * *",
"one_time": true,
"overlap_mode": "skip",
"mnemonic": "my_schedule"
}
SQL
-- Создание Задания на загрузку
POST /api/v1/pull-tasks
{
"action": "upsert",
"source_mnemonic": "my_source",
"request": "",
"target_type": "application-database",
"target_datamart": "foo",
"target_table": "cat1",
"description": "Мое задание на загрузку",
"mnemonic": "my_task"
}
-- Создание Расписания
POST /api/v1/schedules
{
"description": "Мое расписание",
"enabled": true,
"task_mnemonic": "my_task",
"cron": "*/5 * * * * *",
"one_time": true,
"overlap_mode": "skip",
"mnemonic": "my_schedule"
}
-- Загрузка SQL --
-- Создание информационной системы
insert into persistence.information_system (mnemonic, description)
values ('my_information_system','Моя информационная система');
-- Создание Источника с типом folder
insert into persistence."source" (mnemonic, description, is_mnemonic, type, source_connect)
values('my_source','Мой Источник','my_information_system','folder',
'{
"connect_folder": {
"_comment_input_path": "директория с файлами для загрузки",
"input_path": "/upload/input",
"_comment_process_path": "директория для загружаемых файлов",
"process_path": "/upload/process",
"_comment_limit_files": "максимальное число файлов, загружаемых в одном сеансе",
"limit_files": 10,
"_comment_sort": "используемая сортировка, допустимые значения: name or created",
"sort": "name",
"_comment_when_complete": "действие при успешном чтении файла, допустимые значения: move_to or delete",
"when_complete": {
"move_to": {
"path": "/upload/read_success"
}
},
"_comment_exceptionally": "действие при ошибке чтения файла, допустимые значения: move_to or delete",
"exceptionally": {
"move_to": {
"path": "/data/read_fail"
}
}
}
}'
);
Для инициализации загрузки со стороны Источника (push) необходимо:
развернуть Reader с типом потока данных push;
обратиться к одному из методов API данного сервиса.
Описание объектов приведено в Раздел 2.3.6.2.
Reader может быть развернут и сконфигурирован:
средствами конфигурационного файла - для связывания c Информационной системой необходимо добавить ее мнемонику в настройках Reader в общем конфигурационном файле приложения;
Пример конфигурации:
readers:
- mnemonic: push-reader # Уникальный идентификатор в рамках manager
enabled: true
data-flow-type: push
source-type: rest
is-mnemonic: my_information_system
config:
file-size:
restriction: ${SEND_FILE_SIZE_RESTRICTION:512MB}
rest-timeout: ${REST_TIMEOUT:60s} # Таймаут обработки запроса. 0 - таймаут отключен
stream:
avro-codec: zstd # zstd/none
validation:
charset-check-enabled: true # признак выполнения проверки кодировки
valid-charsets: [ UTF-8, US-ASCII, TIS-620 ] # допустимые кодировки для механизма автоопределения
# Предельный размер отчета синхронной проверки, ограничение нужно чтобы не выйти за ограничение heap
# при формировании отчета в памяти. При срабатывании предела в лог приложения выдается предупреждение.
# Получив отчет лимитированной длины, клиент должен понимать что получил не весь отчет об ошибках. При увеличении
# этого параметра необходимо внимательно следить за утилизацией памяти приложения. Размер отчета считается в числе
# записей, значение <=0 означает неограниченный отчет, такая настройка опасна падением приложения по OutOfMemory.
report-max-length: 10_000
csv-parser:
# Символ разделителя значений
separator: ${CSV_PARSER_SEPARATOR:;}
# Символ кавычки
quote-char: ${CSV_PARSER_QUOTE_CHAR:"}
# Символ экранирования значений
escape-char: ${CSV_PARSER_ESCAPE_CHAR:'}
# Настройка интерпретации значений как null. Допустимые значения:
# - EMPTY_SEPARATORS - пустое значение между двумя разделителями, например ;;
# - EMPTY_QUOTES - пустые кавычки, например ;"";
# - BOTH - оба варианта
# - NEITHER - никогда. Пустая строка всегда определяется как пустая строка
field-as-null: ${CSV_PARSER_FIELD_AS_NULL:EMPTY_SEPARATORS}
средствами служебной Базы данных - для связывания c Информационной системой необходимо создать согласованные между собой объекты метаданных Deployer (1), Config (2) и Reader (3).
Внимание
Порядок создания данных объектов важен!
Пример создания с использованием REST-API
-- Создание Deployer
POST /api/v1/deployers
{
"is_mnemonic": "my_information_system",
"enabled": true,
"mnemonic": "my_deployer"
}
-- Создание конфигурации Reader
POST /api/v1/configs
{
"config": "\nfile-size:\n restriction: ${SEND_FILE_SIZE_RESTRICTION:512MB}\nrest-timeout: ${REST_TIMEOUT:60s} # Таймаут обработки запроса. 0 - таймаут отключен\nstream:\n avro-codec: zstd # zstd/none\nvalidation:\n charset-check-enabled: true # признак выполнения проверки кодировки\n valid-charsets: [ UTF-8, US-ASCII, TIS-620 ] # допустимые кодировки для механизма автоопределения\n# Предельный размер отчета синхронной проверки, ограничение нужно чтобы не выйти за ограничение heap\n# при формировании отчета в памяти. При срабатывании предела в лог приложения выдается предупреждение.\n# Получив отчет лимитированной длины, клиент должен понимать что получил не весь отчет об ошибках. При увеличении\n# этого параметра необходимо внимательно следить за утилизацией памяти приложения. Размер отчета считается в числе\n# записей, значение <=0 означает неограниченный отчет, такая настройка опасна падением приложения по OutOfMemory.\nreport-max-length: 10_000\ncsv-parser:\n separator: ${CSV_PARSER_SEPARATOR:;} # Символ разделителя значений\n quote-char: ${CSV_PARSER_QUOTE_CHAR:\"} # Символ кавычки\n escape-char: ${CSV_PARSER_ESCAPE_CHAR:'} # Символ экранирования значений\n # Настройка интерпретации значений как null. Допустимые значения:\n # - EMPTY_SEPARATORS - пустое значение между двумя разделителями, например ;;\n # - EMPTY_QUOTES - пустые кавычки, например ;\"\";\n # - BOTH - оба варианта\n # - NEITHER - никогда. Пустая строка всегда определяется как пустая строка\n field-as-null: ${CSV_PARSER_FIELD_AS_NULL:EMPTY_SEPARATORS}\n",
"mnemonic": "reader_folder_pull"
}
-- Создание Reader
POST /api/v1/readers
{
"deployer_mnemonic": "my_deployer",
"data_flow_type": "pull",
"source_type": "folder",
"enabled": true,
"config_mnemonic": "reader_folder_pull",
"mnemonic": "reader_folder_pull"
}
Пример создания с использованием SQL
-- Создание Deployer
insert into persistence.deployer (mnemonic, is_mnemonic, enabled)
values('my_deployer', 'my_information_system', true);
-- Создание конфигурации Reader
insert into persistence.config (mnemonic, config)
values('reader_folder_pull', '
file-size:
restriction: \${SEND_FILE_SIZE_RESTRICTION:512MB}
rest-timeout: \${REST_TIMEOUT:60s} # Таймаут обработки запроса. 0 - таймаут отключен
stream:
avro-codec: zstd # zstd/none
validation:
charset-check-enabled: true # признак выполнения проверки кодировки
valid-charsets: [ UTF-8, US-ASCII, TIS-620 ] # допустимые кодировки для механизма автоопределения
# Предельный размер отчета синхронной проверки, ограничение нужно чтобы не выйти за ограничение heap
# при формировании отчета в памяти. При срабатывании предела в лог приложения выдается предупреждение.
# Получив отчет лимитированной длины, клиент должен понимать что получил не весь отчет об ошибках. При увеличении
# этого параметра необходимо внимательно следить за утилизацией памяти приложения. Размер отчета считается в числе
# записей, значение <=0 означает неограниченный отчет, такая настройка опасна падением приложения по OutOfMemory.
report-max-length: 10_000
csv-parser:
separator: \${CSV_PARSER_SEPARATOR:;} # Символ разделителя значений
quote-char: \${CSV_PARSER_QUOTE_CHAR:"} # Символ кавычки
escape-char: \${CSV_PARSER_ESCAPE_CHAR:\'} # Символ экранирования значений
# Настройка интерпретации значений как null. Допустимые значения:
# - EMPTY_SEPARATORS - пустое значение между двумя разделителями, например ;;
# - EMPTY_QUOTES - пустые кавычки, например ;"";
# - BOTH - оба варианта
# - NEITHER - никогда. Пустая строка всегда определяется как пустая строка
field-as-null: \${CSV_PARSER_FIELD_AS_NULL:EMPTY_SEPARATORS}
');
-- Создание Reader
insert into persistence.component (mnemonic, deployer_mnemonic, data_flow_type, source_type, enabled, config_mnemonic)
values('reader_folder_pull', 'my_deployer', 'pull', 'folder', true, 'reader_folder_pull');
Варианты конфигурирования Reader описаны в Раздел 2.2.7.1.
В результате инициализации создается Сеанс загрузки.
Жизненный цикл Сеанса загрузки представлен в разделе Статусная модель сеанса загрузки.
В процессе обработки Сеанса загрузки создаются События загрузки (Event), которые позволяют детально отследить этапы загрузки данных, возникающие ошибки и замедление. Описание событий представлено в разделе События модуля.
2.3.6.3.1.1. Алгоритм загрузки
Рисунок - 2.29 содержит диаграмму последовательности загрузки данных.
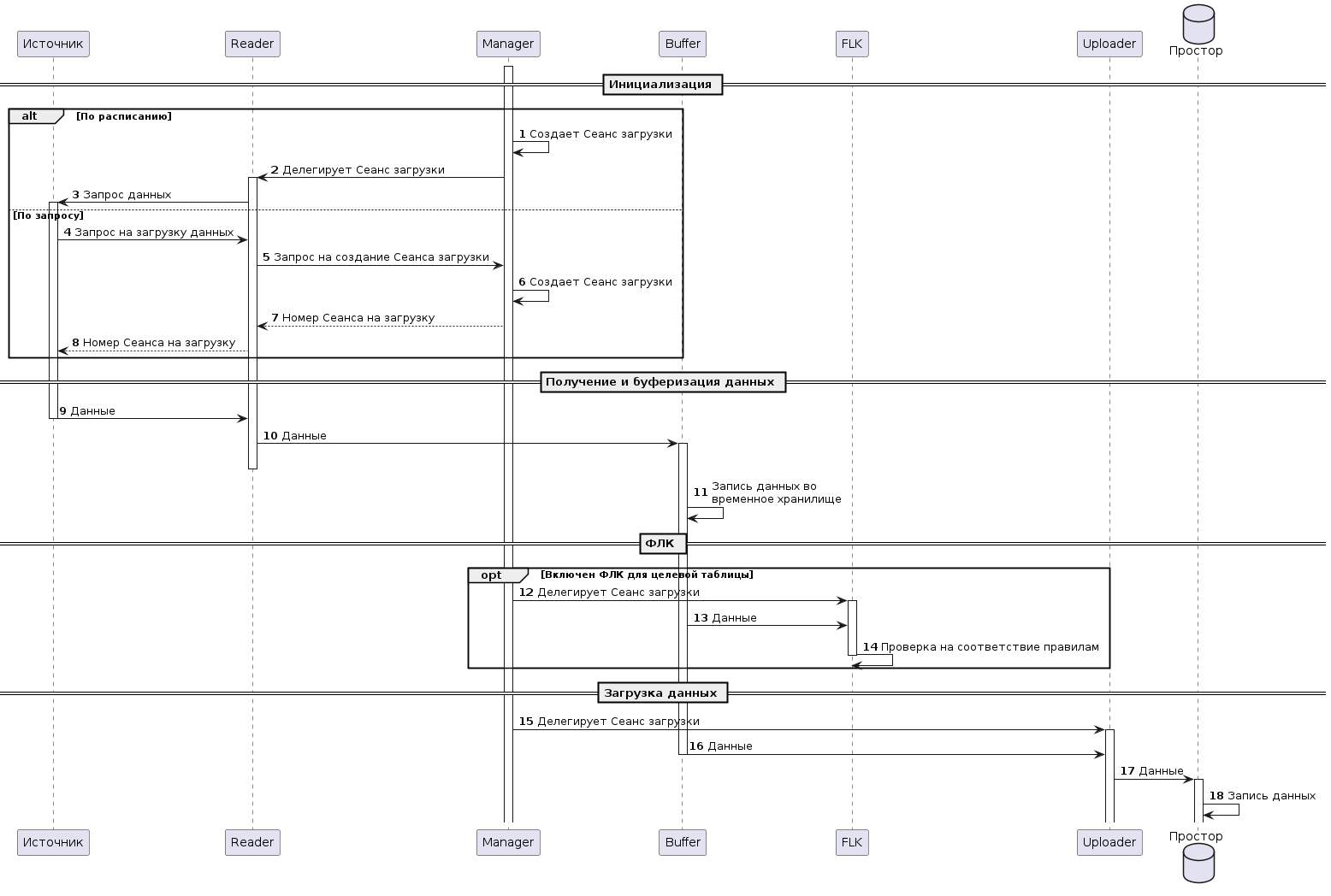
Рисунок - 2.29 Диаграмма последовательности загрузки данных
Инициализация.
а) По расписанию:
Manager создает сеанс загрузки согласно установленному Расписанию;
Manager делегирует сеанс загрузки в Reader;
Reader запрашивает данные в Источнике;
б) По запросу:
Источник данных инициирует запрос на загрузку данных к Reader;
Reader перенаправляет запрос на создание Сеанса загрузки в Manager;
Manager создает сеанс загрузки;
Manager возвращает в Reader номер сеанса загрузки и другую служебную информацию;
Reader передает номер сеанса загрузки Источнику.
Получение и буферизация данных.
а) Источник передает запрошенные данные в Reader;
б) Reader конвертирует в avro и перенаправляет полученные данные в Buffer;
в) Buffer сохраняет данные во временное хранилище.
ФЛК (опционально).
а) Manager делегирует сеанс загрузки модулю ФЛК;
б) Buffer передает данные модулю ФЛК;
в) Модуль ФЛК выполняет проверку данных на соответствие установленным правилам (подробная информация о режимах ФЛК и правилах представлена в Раздел 2.3.6.3.1.3).
Загрузка данных.
а) Manager делегирует Сеанс загрузки к Uploader;
б) Buffer передает данные Сеанса загрузки в Uploader;
в) Uploader выполняет передачу данных в Prostore;
г) Prostore осуществляет требуемые действия с данными.
2.3.6.3.1.2. Статусная модель сеанса загрузки
Рисунок - 2.30 содержит диаграмму статусной модели сеанса загрузки.
Рисунок - 2.30 Диаграмма статусной модели сеанса загрузки
Статусная модель сеанса загрузки приведена в Таблица 2.40
Код |
Название |
Описание |
Финальный статус |
Действия при получении данного статуса |
|---|---|---|---|---|
0 |
Идентификатор запроса не обнаружен |
Технический статус, например сеанс уже удалили или запросили по ошибочному идентификатору |
Да |
Использовать действующий номер Сеанса |
100 |
Новый |
Создан новый сеанс загрузки данных, ожидается назначение сеанса для Reader, который будет выгружать данные |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
101 |
Reader назначен |
Сеанс загрузки данных назначен для Reader, ожидается получение данных от Reader |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
102 |
Буферизация |
Reader получает данные от источника и начал передачу данных в Buffer |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
105 |
Ожидание контроля |
Переход в этот статус выполняется после окончания буферизации или трансформации, в случае, если ФЛК для данного сеанса включен. Ожидается назначение компонента ФЛК, который будет выполнять проверки поступающих в витрину данных. |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
106 |
Контроль (ФЛК) |
Выполняется ФЛК |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
107 |
Ожидание загрузки |
Ожидается назначение загружающего компонента Uploader |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
108 |
Загрузка |
Uploader назначен, выполняется загрузка данных в витрину |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
300 |
Успешно обработан |
Конечный статус успешной обработки задания (в том числе если были пропущены строки не соответствующие ФЛК) |
Да |
Если установлен режим ФЛК При наличии пропущенных при загрузке строк проанализировать и устранить выявленные недочеты в загружаемых данных или скорректировать проверки ФЛК. В других случаях действия не требуются. |
301 |
Ошибка обработки |
Ошибка обработки сеанса, файл не загружен |
Да |
Необходимо: изучить содержимое вернувшегося поля
|
302 |
Ошибка контроля |
Ошибки ФЛК, файл не загружен |
Да |
В процессе ФЛК выявлены ошибки, необходимо
запросить отчет ФЛК, обратившись к
standard-loader c компонентом ФЛК запросом
Далее проанализировать и устранить выявленные недочеты в загружаемых данных или скорректировать проверки ФЛК. |
2.3.6.3.1.3. Форматно-догический контроль
Для включения ФЛК пользователю необходимо:
настроить режим ФЛК в конфигурации модуля (Раздел Раздел 2.2.7.1.1):
указать flk: enabled = true;
задать manager → flk → mode;
добавить правила ФЛК (FLKCondition) для целевой Витрины и таблицы при помощи API Стандартного загрузчика (Раздел Раздел 2.3.6.5).
Правила ФЛК задаются в разрезе целевой Витрины и таблицы, для которых можно задать следующие проверки:
проверка уникальности полей:
по сочетанию атрибутов (для комплексных ключей);
по заданному атрибуту;
сравнение значения с константой;
соответствие регулярному выражению.
Для одного поля возможно создать не более одной проверки одного типа, при этом у каждого поля может быть несколько проверок разных типов.
2.3.6.3.1.3.1. Режимы ФЛК
Для настройки mode реализованы режимы:
skip_string- пропускаются строки не прошедшие ФЛК;warning- строки не прошедшие ФЛК выводятся в лог приложения, а также добавляются в Журнал ФЛК;skip_file- Сеанс загрузки отменяется если найдена хотя бы одна строка не прошедшая ФЛК, при этом ФЛК с формированием Журнала проводится для всего объема данных;skip_on_first_error- Сеанс загрузки отменяется если найдена хотя бы одна строка не прошедшая ФЛК, при этом ФЛК с формированием Журнала завершаются на первой встреченной ошибке;skip_string_except_last- пропускаются строки не прошедшие ФЛК по уникальности кроме последней.
2.3.6.3.1.3.2. Проверка уникальности по одному или по сочетанию полей
Пример запроса для проверки уникальности по группе файлов:
fields:
--проверка уникальности по одному полю
snils:
uniq: true
--проверка по сочетанию полей
id:
uniq: true
uniq-with: [type,region]
2.3.6.3.1.3.3. Проверка сравнения значения с константой
Проверка осуществляется для значений каждого поля в соответствии с заданным правилом, которое включает в себя проверку сравнения с константой (>, <, >=, <=, =, !=).
fields:
# условие или
type:
in: ["1","2","3"]
# условие больше и меньше
age:
">": 6
"<": 19
# условие равенства
subject:
"=": "math"
# условие не равно
mark:
'!=": null
2.3.6.3.1.3.4. Проверка соответствия регулярному выражению
Проверка соответствия регулярному выражению должна выполняется на основе Java Util Regexp (https://docs.oracle.com/javase/7/docs/api/java/util/regex/package-summary.html)
fields:
birthday:
# ограничение на формат даты ГГГГ-ММ-ДД: 4 цифры года, 2 цифры месяца и 2 цифры дня
match: "(\\d{4})\\-(\\d{2})\\-(\\d{2})"
2.3.6.3.2. Сверка данных
Стандартный загрузчик позволяет выполнять сверку части или всех данных между Источником и Витриной с точностью до конкретной записи, без остановки текущей загрузки данных и возможностью автоматической корректировкой отличающихся данных.
Примечание
Функция сверки доступна только для источников с типом JDBC
Для инициализации сверки пользователю (с помощью API Стандартного загрузчика (Раздел 2.3.6.5) или с помощью прямых запросов к служебной БД (при наличии доступа) необходимо создать следующие объекты:
Информационные системы:
Источника;
Витрины данных;
Источники (source) типа JDBC с привязкой к соответствующим Информационным системам:
для подключения к СУБД Источника;
для подключения к Витрине данных.
Задание на сверку (compare_task) со ссылками на созданные Источники.
Расписание (compare_schedule) срабатывания для созданного Задания на сверку.
После создания объектов необходимо развернуть сервисы чтения данных по аналогии с загрузкой данных (Раздел 2.3.6.3.1).
Пример настроек для сверки данных:
REST
-- Создание информационных систем
POST /api/v1/information-systems
{
"description": "Информационная система Источника",
"mnemonic": "original_information_system"
},
{
"description": "Информационная система Витрины",
"mnemonic": "datamart_information_system"
}
-- Создание Источников с типом jdbc. JSON-объект в поле source_connect должен передаваться в виде строки,
-- для этого необходимо добавить escape символы
POST /api/v1/sources
{
"description": "Мой источник",
"is_mnemonic": "original_information_system",
"type": "jdbc",
"source_connect": "\n{\n \"jdbc\": {\n \"url\": \"jdbc:postgresql://postgres:5432/test1\",\n \"user\": \"dtm\",\n \"password\": \"dtm\"\n }\n}\n",
"mnemonic": "original_source"
},
{
"description": "Источник Витрина данных",
"is_mnemonic": "datamart_information_system",
"type": "jdbc",
"source_connect": "\n{\n \"jdbc\": {\n \"url\": \"jdbc:prostore://prostore:9090\"\n }\n}\n",
"mnemonic": "datamart_source"
}
-- Создание Задания на сверку. JSON-объект в полях original_request, datamart_request, correction_delete_request, correction_load_request
-- должен передаваться в виде строки, для этого необходимо добавить escape символы
POST /api/v1/compare-tasks
{
"original_source_mnemonic": "original_source",
"datamart_source_mnemonic": "datamart_source",
"original_request": "\n{\n \"sql\": {\n \"query\": \"SELECT id::VARCHAR as pk_cortege, ('x'||md5(row(lastname,firstname,patronymic,birthdate)::VARCHAR))::bit(64)::bigint as hash_value FROM standard_loader.students_college_actual WHERE active = true\"\n }\n}\n",
"datamart_request": "\n{\n \"sql\": {\n \"query\": \"SELECT CAST(id AS VARCHAR) as pk_cortege, CHECK_SUM_INT64(ROW(lastname, firstname, patronymic, CAST(birthdate AS VARCHAR))) as hash_value FROM receiver.students_college WHERE active = true\"\n }\n}\n",
"target_datamart": "receiver",
"target_table": "students_college",
"correction_delete_request": "\n{\n \"sql\": {\n \"query\": \"SELECT id FROM receiver.students_college WHERE id in(:pk_keys)\"\n }\n}\n",
"correction_load_request": "\n{\n \"sql\": {\n \"query\": \"SELECT * FROM standard_loader.students_college_actual WHERE id in(:pk_keys)\"\n }\n}\n",
"description": "Моя сверка",
"mnemonic": "my_compare"
}
-- Создание Расписания сверки
POST /api/v1/compare-schedules
{
"compare_task_mnemonic": "my_compare",
"cron": "*/5 * * * * *",
"description": "Мое расписание сверки",
"enabled": true,
"mnemonic": "my_compare_schedule",
"one_time": false
}
SQL
-- Создание информационных систем
insert into persistence.information_system (mnemonic, description)
values
('original_information_system','Информационная система Источника'),
('datamart_information_system','Информационная система Витрины');
-- Создание Источников с типом jdbc
insert into persistence."source" (mnemonic, description, is_mnemonic, type, source_connect)
values
('original_source', 'Мой источник', 'source_information_system', 'jdbc', '
{
"connect_jdbc": {
"url": "jdbc:postgresql://postgres:5432/test1",
"user": "dtm",
"password": "dtm"
}
}
'),
('datamart_source', 'Источник Витрина данных', 'datamart_information_system', 'jdbc', '
{
"jdbc": {
"url": "jdbc:prostore://prostore:9090"
}
}
'),
-- Создание Задания на сверку
insert into compare_task
(mnemonic, original_source_mnemonic, datamart_source_mnemonic, original_request, datamart_request, correction_load_request, correction_delete_request, target_datamart, target_table, description)
values('my_compare', 'original_source', 'datamart_source', '
{
"sql": {
"query": "SELECT id::VARCHAR as pk_cortege, ('x'||md5(row(lastname,firstname,patronymic,birthdate)::VARCHAR))::bit(64)::bigint as hash_value FROM standard_loader.students_college_actual WHERE active = true"
}
}
','
{
"sql": {
"query": "SELECT CAST(id AS VARCHAR) as pk_cortege, CHECK_SUM_INT64(ROW(lastname, firstname, patronymic, CAST(birthdate AS VARCHAR))) as hash_value FROM receiver.students_college WHERE active = true"
}
}
', '
{
"sql": {
"query": "SELECT * FROM standard_loader.students_college_actual WHERE id in(:pk_keys)"
}
}
', '
{
"sql": {
"query": "SELECT id FROM receiver.students_college WHERE id in(:pk_keys)"
}
}
', 'receiver', 'students_college', 'Моя сверка');
-- Создание Расписания сверки
insert into compare_schedule
(mnemonic, compare_task_mnemonic, cron, enabled, one_time, description)
values('my_compare_schedule', 'my_compare', '*/5 * * * * *', true, false, 'Мое расписание сверки');
В результате инициализации по заданному расписанию создаются Сеансы сверки. Жизненный цикл Сеанса загрузки представлен в разделе Раздел 2.3.6.3.2.2.
В процессе обработки каждого Сеанса сверки создаются:
события сверки (compare_event), которые позволяют детально отследить этапы выполнения сверки. Описание событий представлено в разделе Раздел 2.3.6.4.
журнал Результатов сверки (compare_result), в котором содержатся все выявленные расхождения между данными Источника и Витрины;
журнал Устойчивых расхождений (stable_difference), в котором содержатся расхождения, сохраняющиеся на протяжении двух последовательных сеансов сверки, при условии неизменности оригинальных данных в Источнике.
Также, в случае включения автоматической корректировки, создаются:
журнал Попыток корректировки (correction_attempt), в котором содержатся первичные ключи записей и ссылки на Сеансы корректирующей загрузки, в рамках которых данные записи корректировались;
журнал Исключений из корректировки (correction_exception), в котором содержатся первичные ключи записей, которые не удалось автоматически скорректировать. Данные записи предназначены для ручного разбора и будут исключены из дальнейшей автоматической корректировки.
Описание объектов приведено в разделе Раздел 2.3.6.2.
2.3.6.3.2.1. Алгоритм сверки
Рисунок - 2.31 содержит диаграмму последовательности обработки Сеанса сверки.
Рисунок - 2.31 Диаграмма последовательности обработки Сеанса сверки
Инициализация и загрузка контрольных сумм:
а) Comparator создает Сеанс сверки;
б) Comparator делегирует Manager создание Сеансов загрузки контрольных сумм;
в) Manager создает Сеансы загрузки из Источника и Витрины;
г) Manager делигирует выполнение Сеансов загрузки подходящим Reader’ам;
д) Reader’ы получают Сеансы загрузки и инициируют запросы к Источнику и Витрине данных для получения контрольных сумм;
е) Источник и Витрина данных вычисляют и передают контрольные суммы Reader;
ж) Reader загружает контрольные суммы в служебную базу данных (при этом используется штатный механизм загрузки).
Сравнение контрольных сумм:
а) Comparator отправляет запрос к Служебной БД на сравнение контрольных сумм;
б) Служебная БД выполняет сравнение и возвращает выявленные расхождения;
в) Если расхождения не обнаружены, Comparator завершает процесс сверки;
г) Если расхожнения обнаружены, Comparator формирует журнал Результатов сверки в Служебной БД и переходит к вычислению Устойчивых расхождений.
Вычисление устойчивых расхождений:
а) Comparator проверяет наличие данных минимум двух смежных сверок;
б) Если данных недостаточно, Comparator завершает процесс сверки;
в) Если данных достаточно, Comparator выполняет вычисление устойчивых расхождений;
г) Если Устойчивые расхождения не выявлены, Comparator завершает процесс сверки;
д) Если Устойчивые расхождения выявлены, Comparator формирует журнал Устойчивых расхождений;
е) Comparator проверяет необходимость корректировки.
Фаза корректировки данных:
а) Если корректировка включена, Comparator обновляет журнал Исключений из корректировки;
б) Comparator делегирует Manager создание Сеансов корректирующей загрузки для всех Устойчивых расхождений, за вычетом Исключений из корректировки;
в) Comparator Формирует журнал Попыток корректировки;
г) Manager создает Сеансы корректирующей загрузки;
д) Manager делегирует сеансы корректирующей загрузки подходящему Reader’у;
е) Ридер получает делегированные Сеансы корректирующей загрузки и запрашивает данные в Источнике;
ж) Источник возвращает Reader’у запрошенные данные;
з) Reader передает корректирующие данные в Витрину (при этом используется штатный механизм загрузки);
и) Витрина загружает данные в целевую таблицу.
2.3.6.3.2.2. Статусная модель Сеанса сверки
Сверка может включать лишь одну пару загрузок хешей и их сравнение, либо может так же включать дополнительные действия по выявлению устойчивых расхождений данных, или даже серию загрузок ключей и их сравнений.
Рисунок - 2.32 Статусная модель Сеанса сверки
Статусная модель сеанса сверки приведена в Таблица 2.41
Код |
Название |
Описание |
Финальный статус |
Действия при получении данного статуса |
|---|---|---|---|---|
200 |
Новый |
Создан новый сеанс Сверки, ожидается назначение Компаратору, который будет выгружать данные |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
201 |
Ожидание исполнение сеансов загрузки хешей |
Созданы сеансы загрузки контрольных сумм, ожидается их исполнение |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
202 |
Сравнение хешей |
Контрольные суммы данных Источника и Витрины загружены в служебную БД, выполняется их сравнение |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
210 |
Выявление устойчивых расхождений |
Выявлены расхождения между данными Источника и Витрины, выполняется сравнение расхождений с предыдущим Сеансом Сверки для выявления устойчивых расхождений |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
211 |
Формирование справочника невыравниваемых записей |
Выявлены устойчивые расхождения, выполняется анализ результатов прошлой корректирующей загрузки для выявления записей не поддающихся автоматической корректировке |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
230 |
Выравнивающая загрузка |
В Задании сверки настроена автоматическая корректировка, а так же найдены записи для которых она возможна. Сеансы корректирующей загрузки созданы, ожидается их исполнение |
Нет |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30сек. |
350 |
Сверка завершена |
Конечный статус успешной обработки задания |
Да |
Необходимо изучить результаты проведенной Сверки:
При наличии Устойчивых расхождений и включенном механизме автоматической корректировки данных, изучить также:
|
351 |
Ошибка выполнения сверки |
Ошибка обработки сеанса, сверка не произведена |
Да |
Необходимо
|
2.3.6.4. События модуля
Код события |
Источник |
Сообщение |
Перевод из статуса (status_from) |
Перевод в статус (status_to) |
Прикладные данных (payload) |
Примечание |
|---|---|---|---|---|---|---|
События создания сеансов (таблица БД: event) |
||||||
1001 |
Manager |
Сеанс создан по расписанию |
100 Новый |
|||
1002 |
Reader |
Сеанс создан по запросу |
100 Новый |
session |
||
1003 |
Reader |
Данные запрошены |
||||
1004 |
Buffer |
Поступила порция данных |
100 Новый 101 Reader назначен |
102Буферизация |
chunk_num |
|
1006 |
Buffer |
Загрузка в буфер завершена |
102 Буферизация |
105 Ожидание контроля 107 Ожидание загрузки |
file_sz |
|
1007 |
Manager |
Неудачная попытка создания Сеанса. skip |
||||
1008 |
Manager |
Неудачная попытка создания Сеанса. wait |
||||
1020 |
Reader |
Обработка нового файла |
file_name |
|||
1021 |
Reader |
Пустой файл, прикладные данные отсутствуют |
file_name |
Применимо только для reader folder pull, сообщает о факте обработки пустого файла, но при этом в сеансе могут быть и другие файлы |
||
1022 |
Reader |
Загружаемых данных нет |
Reader назначен |
300 Успешно обработан |
Например по JDBC получили пустое множество |
|
События ФЛК (таблица БД: event) |
||||||
2001 |
FLK |
ФЛК начат |
||||
2002 |
FLK |
ФЛК завершен без ошибок |
106 Контроль |
107 Ожидание загрузки |
||
2003 |
FLK |
ФЛК завершен с ошибками |
106 Контроль |
107 Ожидание загрузки 302 Ошибка ФЛК |
||
2004 |
Manager |
Получен запрос на отчет ФЛК |
||||
2005 |
Manager |
Отправлен отчет ФЛК |
||||
2006 |
Manager |
Получен запрос длины очереди ФЛК |
||||
2007 |
Manager |
Отправлена длина очереди ФЛК |
||||
События загрузки (таблица БД: event) |
||||||
4001 |
Uploader |
Загрузка данных в Витрину началась |
||||
4002 |
Uploader |
Загрузка данных в Витрину завершена |
108 Загрузка |
300 Успешно обработан |
||
4003 |
Manager |
Дельта открыта |
user, инициировавший операцию |
Успешно выполненная команда |
||
4004 |
Manager |
Дельта закрыта |
user, инициировавший операцию |
Успешно выполненная команда |
||
4005 |
Manager |
Откат дельты |
user, инициировавший операцию |
Успешно выполненная команда |
||
4006 |
Manager |
Получен запрос длины очереди загрузки |
user, инициировавший операцию |
|||
4007 |
Manager |
Отправлена длина очереди загрузки |
user, инициировавший операцию |
|||
4008 |
Uploader |
Загружаемые данные разделены по дубликату первичного ключа |
offset |
|||
4009 |
Uploader |
Загружаемые данные разделены по лимиту операции Prostore |
offset |
|||
4010 |
Uploader |
Попытка подключения к Prostore |
номер попытки |
|||
Универсальные события (таблица БД: event) |
||||||
5001 |
Manager |
Компонент назначен |
В зависимости от текущего статуса |
|||
5002 |
Manager |
Отправлен запрос на удаление данных из буфера |
||||
5003 |
Buffer |
Данные удалены из буфера |
||||
5004 |
Manager |
Получен запрос статуса Сеанса |
||||
5005 |
Manager |
Отправлен ответ на запрос статуса Сеанса |
||||
5006 |
Manager |
Потеря сервиса исполняющего Сеанс |
Текущий статус |
Предыдущий статус, ожидающий назначение |
||
5007 |
Manager |
Регистрация сервиса |
||||
5008 |
Manager |
Обрыв связи с сервисом |
||||
5009 |
Manager |
Отправка сервисов для развертывания |
||||
5010 |
Deployer |
Сервис запущен |
||||
5011 |
Deployer |
Сервис остановлен |
||||
5012 |
Comparator |
Потеря компаратора, исполняющего сеанс сверки |
||||
5013 |
Comparator |
Попытка подключения к Буферу |
номер попытки |
|||
5020 |
Manager |
Расширение пачки сеансов, отправляемых на загрузку |
||||
События ошибок загрузки (таблица БД: event) |
||||||
6001 |
Любой источник |
Произвольная ошибка |
301 Ошибка обработки |
Стектрейс ошибки |
||
6002 |
Manager |
Ошибка открытия дельты |
user, инициировавший операцию |
|||
6003 |
Manager |
Ошибка закрытия дельты |
user, инициировавший операцию |
|||
6004 |
Manager |
Ошибка отката дельты |
user, инициировавший операцию |
|||
6005 |
Reader |
Недостаточно места на диске reader, рекомендуется отключение опции reader->save-read-data-> enabled |
301 Ошибка обработки |
стектрейс ошибки |
||
События сверок (таблица БД: compare_event) |
||||||
7001 |
Comparator |
Сеанс сверки создан по расписанию |
200 Новый |
|||
7002 |
Comparator |
Сеансы загрузки хэшей созданы |
200 новый |
201 Ожидание исполнения сеансов загрузки хешей |
||
7003 |
Comparator |
Сеансы загрузки хэшей успешно обработаны |
201 Ожидание исполнения сеансов загрузки хешей |
202 Сравнение хешей |
||
7100 |
Comparator |
Сравнение хешей завершено, расхождений не обнаружено |
202 Сравнение хешей |
350 Сверка завершена |
||
7010 |
Comparator |
Сравнение хешей завершено, обнаружены расхождения |
202 Сравнение хешей |
210 Выявление устойчивых расхождений |
||
7110 |
Comparator |
Недостаточно данных для выявления устойчивых расхождений |
210 Выявление устойчивых расхождений |
350 Сверка завершена |
||
7120 |
Comparator |
Устойчивые расхождения не выявлены |
210 Выявление устойчивых расхождений |
350 Сверка завершена |
||
7020 |
Comparator |
Выявлены устойчивые расхождения |
210 Выявление устойчивых расхождений |
350 Сверка завершена или 220 Формирование справочника невыравниваемых записей |
||
7130 |
Comparator |
Справочник невыравниваемых записей сформирован, нет записей для выравнивания |
220 Формирование справочника невыравниваемых записей |
350 Сверка завершена |
||
7030 |
Comparator |
Справочник невыравниваемых записей сформирован, есть записи для выравнивания |
220 Формирование справочника невыравниваемых записей |
230 Выравнивающая загрузка |
||
7031 |
Comparator |
Сеансы выравнивающей загрузки созданы |
||||
7140 |
Comparator |
Сеансы выравнивающей загрузки успешно обработаны |
230 Выравнивающая загрузка |
350 Сверка завершена |
||
7005 |
Comparator |
Пропуск создания Сеанса сверки |
||||
События ошибок сверки (таблица БД: compare_event) |
||||||
8001 |
Comparator |
Произвольная ошибка |
351 Ошибка выполнения сверки |
|||
2.3.6.5. Спецификация стандартного загрузчика
2.3.6.5.1. Управление медатанными
2.3.6.5.2. Загрузка данных
2.3.6.5.3. Форматно-логический контроль
2.3.7. BLOB-адаптер
Примечание
Модуль входит в состав конфигурации Стандарт
2.3.7.1. Общее описание
BLOB-адаптер - программный модуль Витрины данных, предназначен для получения доступа из Витрины данных к BLOB-объектам ведомства.
BLOB-адаптер предоставляет возможность настроить доступ к BLOB-объектам расположенным в Хранилище BLOB-объектов.
BLOB-объект - это специальный тип двоичных данных, предназначенный для хранения бинарных файлов: изображений, скан-копий документов, текстовых файлов и т.д.
Примечание
Хранилище BLOB-объектов располагается на стороне ведомства и не является частью Витрины данных.
BLOB-адаптер предназначен для следующих задач:
настройка доступа в Хранилище BLOB-объектов;
предоставление регламентированного доступа к BLOB-объектам;
получение и отправка запросов на получение BLOB-объектов;
чтение BLOB-объектов;
сохранение BLOB-объектов на S3 (предпочтителен с точки зрения надежности) или FTP-сервере (через СМЭВ3-адаптер).
Взаимодействие с BLOB-объектами возможно через запросы из СМЭВ3 (через СМЭВ3-адаптер) или Агента СМЭВ4.
Доступ к считыванию BLOB-объектов производится методом GET по протоколу HTTP/ HTTPS (указывается в конфигурации,
параметр host) .
2.3.7.2. Общая схема взаимодействия через BLOB-адаптер
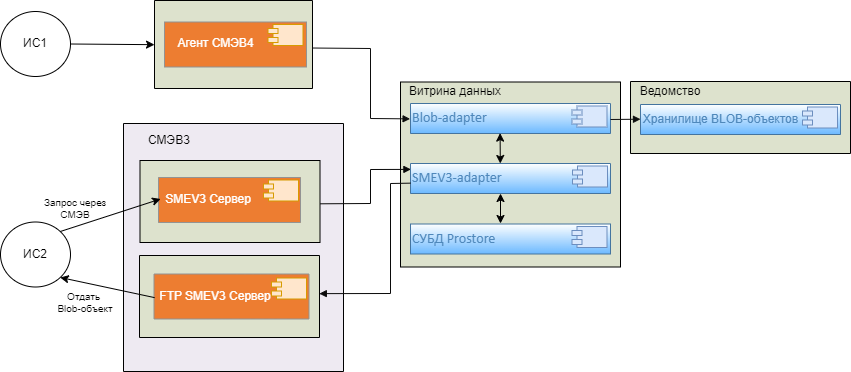
Рисунок - 2.33 Общая схема взаимодействия через BLOB-адаптер
2.3.7.3. Взаимодействие через СМЭВ-адаптер
2.3.7.3.1. Схема взаимодействия через СМЭВ-адаптер
Общая схема получения BLOB-объектов через СМЭВ-адаптер выглядит следующим образом:
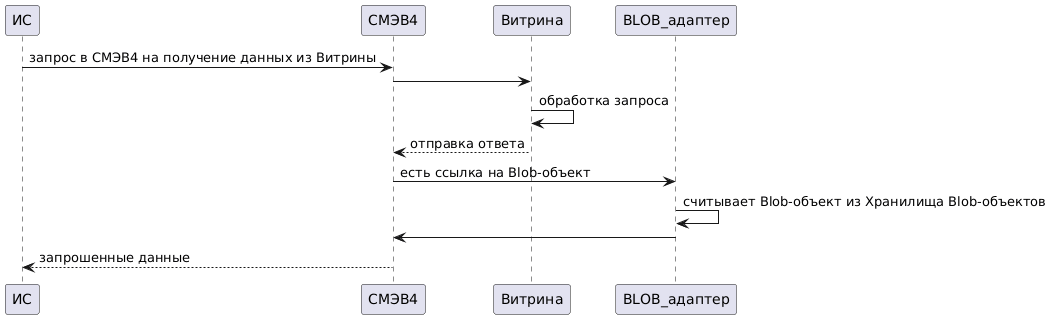
Рисунок - 2.34 Взаимодействие BLOB-адаптера через СМЭВ4-адаптер
2.3.7.3.2. Процесс обработки запроса на получение BLOB-объекта (СМЭВ4-адаптер)
В СМЭВ4 поступает запрос на получение данных из Витрины.
СМЭВ4 отправляет запрос в Витрину.
Витрина данных обрабатывает запрос и отправляет ответ.
СМЭВ4 считывает данные полученные от Витрины. В случае, если в теле запроса содержится ссылка на BLOB-объект (например, изображение).
Агент потребителя отправляет запрос в BLOB-адаптер на получение этого BLOB-объекта.
BLOB-адаптер, считывает ссылку на BLOB-объект и обращается в Хранилище BLOB-объектов на стороне ведомства. После получения BLOB-объекта, возвращает его в СМЭВ4.
2.3.7.4. Взаимодействие через СМЭВ3-адаптер
2.3.7.4.1. Схема взаимодействия через СМЭВ3-адаптер
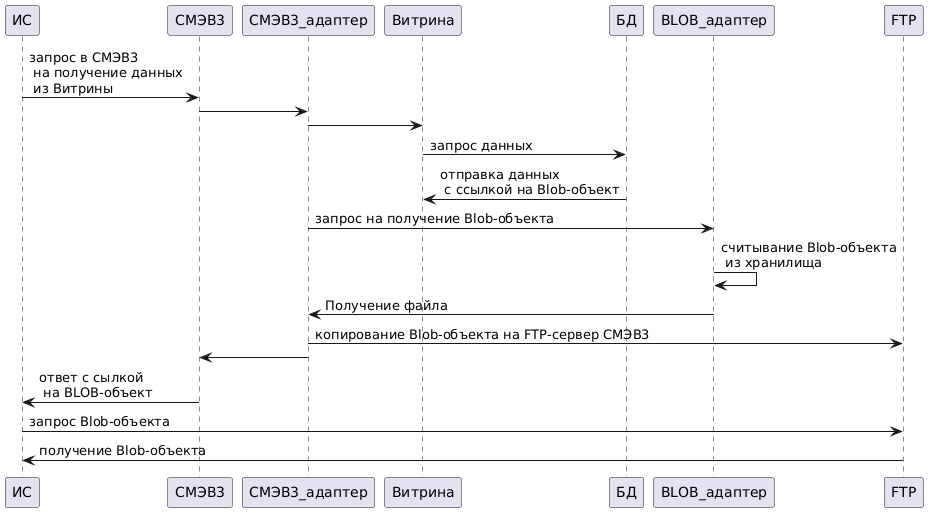
Рисунок - 2.35 Взаимодействие BLOB-адаптера через СМЭВ4
2.3.7.4.2. Процесс обработки запроса на получение BLOB-объекта (через СМЭВ3-адаптер)
Из внешней ИС в СМЭВ4 поступает запрос на получение данных из Витрины.
СМЭВ3-адаптер получает запрос и отправляет его в Витрину.
Витрина обращается к БД, подготавливает ответ на запрос. Если в запросе есть ссылка на BLOB-объект, BLOB-адаптер обращается к Хранилищу BLOB-объектов, копирует BLOB-объект, выкладывает его на FTP-сервер СМЭВ4 и отправляет ссылку на BLOB-объект в Витрину.
После того как BLOB-объект загружен на FTP-сервер СМЭВ4, Витрина отправляет ответ на запрос в СМЭВ4, в котором содержится ссылка на BLOB-объект (сохраненный на FTP-сервере).
После получения ответа внешняя ИС может обратиться по ссылке и скачать BLOB-объект с FTP-сервера СМЭВ4.
2.3.7.5. Требования к серверу BLOB-адаптера
Cледующие файлы не должны контролироваться системой управления конфигурации (при ее наличии), поскольку они должны быть доступны процессу установки для создания и модификации:
/etc/hosts/etc/selinux/config/etc/sysctl.confфайлы директории
/usr/lib/systemd/system//etc/sysconfig/iptables\*/etc/firewalld/\*/etc/docker/\*
Снаружи сервер должен быть доступен по следующим портам:
22 (SSH).
2.3.7.6. Требования к Хранилищу BLOB-объектов
Хранилище BLOB-объектов должно поддерживать регламентированный витриной интерфейс доступа к BLOB-объектам по запросу.
Для корректной работы с Хранилищем BLOB-объектов, необходимо выполнить следующие условия:
Предоставить доступ:
к таблицам с метаданными по документам, хранилища ведомства;
к ссылкам на BLOB-объекты (изображения, архивы, pdf-файлы и т.д.) в хранилище ведомства, соответствующие метаданным.
Предоставить связь между ссылками и метаданными, если они разнесены по разным хранилищам.
Примечание
Все обновления ссылок на документы происходят только через ETL, т.е. от Поставщика данных (ведомства) к Витрине. Обновление самих BLOB через витрину, с последующей проливкой в ведомства, не предусмотрено.
2.3.7.7. Требования к предоставляемому интерфейсу Хранилища BLOB-объектов (API-интерфейс)
API-интерфейс реализованный соответственно данной спецификации должен предоставляться Хранилищем BLOB-объектов для возможности успешного взаимодействия с Витриной.
API-интерфейс Хранилища BLOB-объектов должен использовать метод GET, который поддерживается Витриной для получения
тела BLOB-объекта из Хранилища BLOB-объектов.
С помощью API-интерфейса отправляется запрос на получение BLOB-объектов.
Считывание BLOB-объекта производится по протоколу HTTP (допустимо HTTPS, указывается в конфигурации файла application.yml,
параметр host (см. раздел Раздел 2.2.8.1 в документе «Руководство администратора Компонента «Витрина данных»)).
2.3.8. CSV-Uploader
Примечание
Модуль входит в состав конфигурации Стандарт и Лайт
2.3.8.1. Общее описание
CSV-Uploader - программный модуль Витрины данных, который предназначен для загрузки CSV-файлов в Витрину данных.
CSV-Uploader предназначен для следующих задач:
формирование структуры витрины;
выгрузка шаблона CSV-файла для загрузки данных;
загрузка данных в виде CSV-файлов в витрину:
с ручным или автоматическим выбором таблицы;
опциональным ФЛК данных перед загрузкой;
автоматическая загрузка данных в витрину по расписанию;
автоматическая загрузка данных в витрину по веб-интерфейсу;
просмотр журнала загрузки.
Внимание
Загружаемые файлы обязательно должны быть в кодировке UTF-8
2.3.8.1.1. Взаимодействие компонентов
Схема взаимодействия при загрузке в локальную Витрину данных
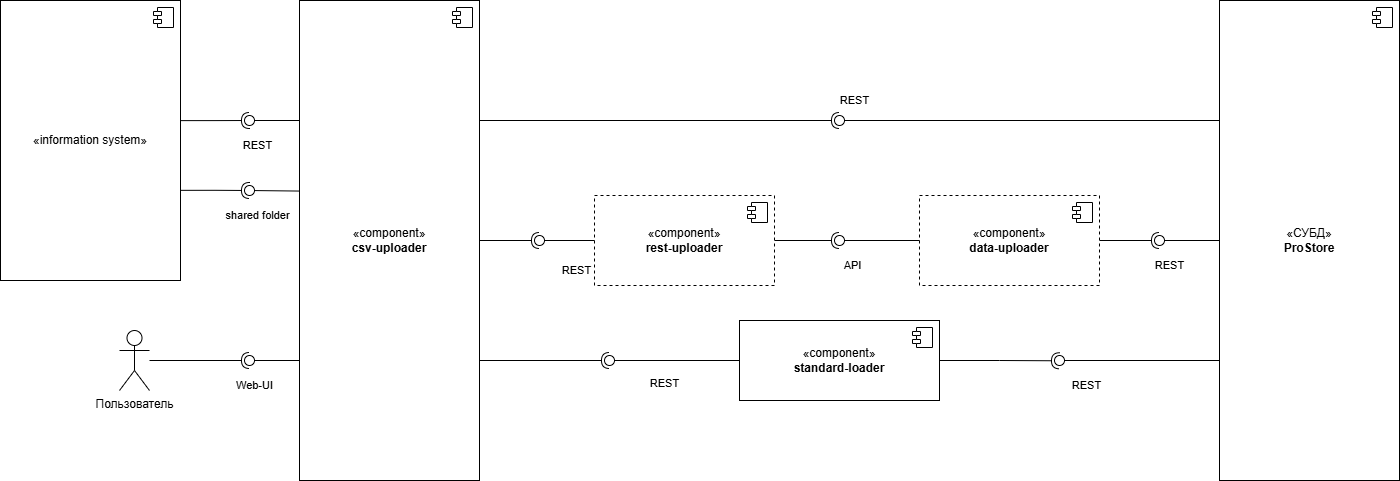
Рисунок - 2.36 Схема взаимодействия при загрузке в локальную Витрину данных
Схема взаимодействия при загрузке в удаленную Витрину данных
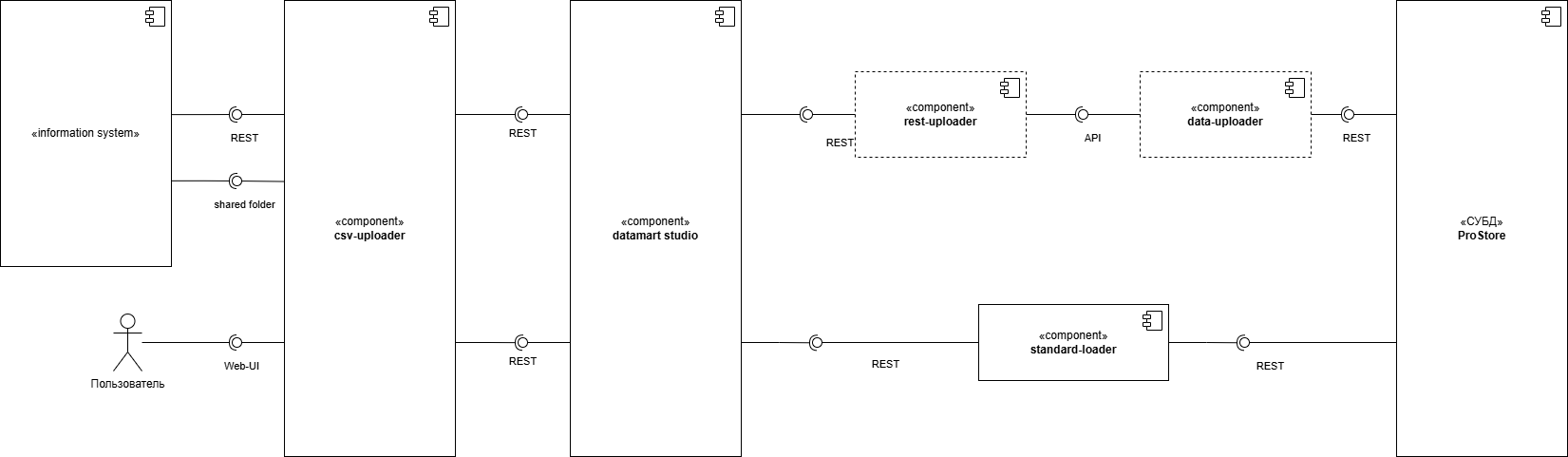
Рисунок - 2.37 Схема взаимодействия при загрузке в удаленную Витрину данных
Примечание
При переключении между загрузчиками рекомендуется удалять локальную БД CSV-Uploader для исключения недостижимых идентификаторов.
2.3.9. DATA-Uploader - Модуль исполнения асинхронных заданий
Примечание
Модуль входит в состав конфигурации Стандарт и Лайт
2.3.9.1. Общее описание
DATA-Uploader - Модуль исполнения асинхронных заданий обеспечивает обработку очереди файлов, используя следующие функциональные особенности:
обработка очереди файлов производится циклами;
очередь файлов работает в режиме упорядочения процесса по принципу «первым пришел – первым обслужен»;
каждый элемент в очереди файлов содержит UUID задания, имя витрины и таблицы, содержимое CSV-файла;
файлы в очереди могут относится к разным витринам и/или разным таблицам одной витрины;
поддерживает удаление исторических данных.
Во избежание конфликтов на уровне ПО Prostore в каждый конкретный момент времени только один DATA-Uploader обеспечивает загрузку данных.
При перезапуске DATA-Uploader может возникать задержка в обработке запросов продолжительностью до TTL флага активности экземпляра (параметр конфигурации ACTIVE_TTL, 3 минуты по умолчаниию), плюс интервал между попытками захватить активность (параметр конфигурации ACTIVE_TIMEOUT, 1 минута по умолчанию).
Примечание
Заливка данных через модуль DATA-Uploader не предусматривают параллельную заливку в датамарты вместе с другими инструментами. Параллельная заливка данных в те же датамарты вручную или средствами ETL приведет к конфликту в работе с дельтами и к ошибкам соответственно.
2.3.10. ETL - Модуль загрузки/ удаления данных
Примечание
Модуль входит в состав конфигурации Стандарт
Базовый сервис загрузки данных предоставляет возможность асинхронного приема данных из сторонних источников с целью последующей загрузки их на Витрину данных. Загрузка/обновление данных осуществляется в соответствии с заранее подготовленными Avro-схемами.
Сервис загрузки данных реализуется компонентом ETL, предоставляющей REST API. Доступ к REST API должен осуществляться через Proxy API Datamart Studio. Перед загрузкой необходимо получить токен Proxy API, который в дальнейшем используется для авторизации при операциях, описанных в разделах ниже. При получении ошибки авторизации необходимо повторить авторизацию, получить новый токен и использовать его для дальнейшей загрузки.
Для взаимодействия с REST API (через Proxy API) в продуктивной среде на стороне источника данных требуется использовать сертифицированную версию ОС, а также механизмы, соответствующие требованиям безопасности, установленным для эксплуатации системы (например, через программный продукт Postman).
На стороне источника данных должны соблюдаться следующие требования к механизму взаимодействия:
Запрещается хранение логина и пароля в открытом виде на диске. Логин и пароль должны выгружаться из безопасного хранилища в память ВМ (или контейнера) при старте взаимодействия с Proxy API для дальнейшего использования, сама ВМ должна находиться в закрытом контуре ИС или ведомства.
Рекомендуется реализовать механизм стирания логина и пароля из памяти после успешной аутентификации через Proxy API.
В целях тестирования взаимодействия на тестовой среде может использоваться утилита curl.
2.3.11. REST-Uploader - Модуль асинхронной загрузки данных из сторонних источников
Примечание
Модуль входит в состав конфигурации Стандарт и Лайт
2.3.11.1. Общее описание
REST-Uploader - Модуль асинхронной загрузки данных из сторонних источников реализован для обеспечения параллельного обновления данных в Компоненте «Витрина данных» с независимым масштабированием REST-интерфейса.
Операции с данными:
загрузка: отправка запроса на
.../upload;Модификация данных из внешних источников: отправка запроса на
.../modify;логическое удаление: отправка запроса на
.../delete(при этом для логических таблиц данные только помечаются как удаленные);удаление исторических данных: отправка запроса на
.../truncate.
См. Спецификация модуля асинхронной загрузки данных из сторонних источников
Внимание
Не рекомендуется использовать персональные данные в качестве первичного ключа, т.к. первичный ключ может отображаться в логах Системы при удалении истории.
Обеспечена буферизация поступающих на загрузку данных. Буферизированные данные направляются в базу менеджером дельт с группировкой по датамартам.
Обеспечены следующие функциональные особенности:
идентификатор генерируется по стандарту UUID;
метаданные от сервера витрины кешируются механизмом, и проверяются на соответствие по количеству и по типам полей (при несоответствии загружаемых данных метаданным целевой таблицы сервис для передачи / загрузки данных возвращает статус запроса с ошибкой, без размещения данных в очереди на загрузку);
загруженные данные размещаются вместе с UUID в очереди с именем «queue»;
формируется запись с ключом «status.[UUID запроса]» и статусом 0 в очереди;
клиенту, отправившему запрос, возвращается успешный статус запроса вместе с UUID;
в логе приложения формироваться запись события получения запроса на загрузку с указанием идентификатора запроса, идентификатора ВУЗа, времени обработки и размера загруженных данных.
Внимание
Загружаемые файлы обязательно должны быть в кодировке UTF-8
Примечание
Заливка данных через через модуль REST-Uploader не предусматривают параллельную заливку в датамарты вместе с другими инструментами. Параллельная заливка данных в те же датамарты вручную или средствами ETL приведет к конфликту в работе с дельтами и к ошибкам соответственно.
Общие правила формата загружаемых CSV-файлов приведены в таблице Таблица 2.43.
Параметр |
Значение |
|---|---|
Разделитель строк |
Любой вариант из: CR/LF (0x0D0A), CR (0x0D), LF (0x0A) |
Разделитель полей |
по настройке csv-parser/separator (Раздел 2.2.9.2) |
Строка заголовка |
да (обязательно) |
Порядок полей в строке |
определяется строкой заголовка |
Ограничитель текстового поля |
по настройке csv-parser/quote-char (Раздел 2.2.9.2) |
Символ маскировки в текстовом поле |
по настройке csv-parser/escape-char (Раздел 2.2.9.2) |
Обнаружение значения null |
До релиза 1.5.0 (включительно): по настройке csv-parser/field-as-null (Раздел 2.2.9.2) начиная с релиза 1.10.0: в текущей реализации парсера данная настройка не поддерживается |
Кодирование символов |
UTF-8 |
Десятичный разделитель |
символ |
Формат даты |
любой из: |
Формат времени |
любой из: |
Формат даты-времени |
до релиза 1.5.0(включительно) любой из: начиная с релиза 1.10.0 любой из: |
2.3.11.2. Проверка форматно-логического контроля
Проверка форматно-логического контроля включает в себя:
обязательные проверки, выполняющиеся вне зависимости от настроек модуля в синхронном режиме;
необязательные проверки, индивидуальные для каждой таблицы, которыми управляет администратор Системы, выполняющиеся в асинхронном режиме.
Наименование проверки |
Код ошибки |
Кириллическое описание |
|---|---|---|
Проверка уникальности |
|
Дубликат файла/группы |
Проверка парсинга файла |
|
Ошибка парсинга: текст ошибки |
Проверка кодирования |
|
Кодировка файла не соответствует кодировке UTF-8 |
Проверка превышения предельного размера файла (больше 512 Мб) |
|
Слишком большой файл |
Проверка наличия данных в файле |
|
Пустой файл |
Проверка соответствия заголовков инфосхеме |
|
Структура файла не соответствует схеме |
Проверка соответствия числа столбцов в строке |
|
Некорректное число столбцов в строке |
Проверка соответствия типам полей |
|
Значение не соответствует типу требуемый тип |
Проверка уникальности полей |
|
Значение не отвечает требованиям уникальности |
Проверка регулярных выражений |
|
Значение не соответствует регулярному выражению регулярное выражение |
Проверка соответствия условию |
|
Значение не соответствует условию условие |
Таймаут валидации |
|
Истек таймаут валидации файла |
2.3.11.2.1. Синхронная проверка ФЛК
Примечание
синхронные проверки выполняются вне зависимости от настроек модуля REST-Uploader;
синхронные проверки являются блокирующими;
ошибки синхронных проверок возвращаются в теле ответа по REST-API.
К синхронным проверкам относятся:
проверка соответствия инфосхеме:
проверка соответствия имен и количества полей в заголовках;
проверка типа данных;
проверка экранирования данных: проверка соответствия числа столбцов по каждой строке;
проверка соответствия файла кодировке UTF-8 , отсутствие BOM (при наличии BOM при загрузке удаляются начальные байты
efbbbf);проверка размера файла и наличия данных:
проверка предельного размера загружаемого файла 512Мб;
проверка наличия данных в файле.
2.3.11.2.2. Асинхронная проверка
Примечание
асинхронные проверки выполняются в зависимости от настроек модуля;
проверки не являются блокирующими (поведение при их наличии определяется конфигурацией модуля);
список проверок уникален для каждой таблицы и хранится в Zookeeper в виде отдельного YAML файла.
К асинхронным проверкам относятся:
проверка уникальности полей:
по сочетанию атрибутов (для комплексных ключей);
по заданному атрибуту;
сравнение значения с константой;
соответствие регулярному выражению.
Для одного поля возможно создать не более одной проверки одного типа, при этом у каждого поля может быть несколько проверок разных типов.
2.3.11.2.2.1. Проверка уникальности по одному или по сочетанию полей
Проверка уникальности проводится:
в рамках группы файлов, если заданы headers - для проверки в рамках группы обязательно заполнения всех полей:
group_id;group_file_num;group_file_count.
Пример запроса для проверки уникальности по группе файлов:
--проверка по сочетанию полей
fields:
id:
uniq: true
uniq-with: [type,region]
--проверка уникальности по одному полю
snils:
match: "/^[-\s\d]{11}$/"
uniq: true
2.3.11.2.2.2. Проверка соответствия заданному значению
проверка соответствия заданному значению проводится для каждого файла вне зависимости от наличия group_id;
проверка осуществляется для значений каждого поля в соответствии с заданным правилом;
проверка соответствия заданному значению включает в себя:
проверку сравнения с константой (
>,<,>=,<=,=,!=);проверку соответствия регулярному выражению (должна выполняться на основе Java Util Regexp https://docs.oracle.com/javase/7/docs/api/java/util/regex/package-summary.html )
2.3.11.2.2.3. Поведение в случае таймаута валидации
Период выполнения асинхронных проверок определяется конфигурационным параметром validation-timeout и по умолчанию
составляет 60 минут.
В случае если за указанное в настройках время асинхронные проверки не были выполнены, файл удаляется из очереди с
обогащением отчета о найденных ошибках ошибкой validationTimeout.
В случае возникновения подобной ошибки рекомендуется:
проверить регулярные выражения, по которым происходит проверка, так как неверно заданное регулярное выражение кратно увеличивает скорость проверки;
увеличить значение
validation-timeoutи повторить загрузку данных.
2.3.11.3. Статусная модель
Статус запроса к модулю REST-Uploder можно получить, выполнив запрос с передачей идентификатора запроса GET '/v2/requests/:requestId/status'.
В ответ возвращается три поля:
code - код статуса;
errorMessage - сообщение об ошибке, заполняется лишь в случае ошибочного статуса;
description - описание ошибки, заполняется лишь в случае ошибочного статуса.
Пример ответа на запрос статуса:
{"code":2,"description":null,"errorMessage":null}
{"code":3,"description":"Успешно обработан","errorMessage":null}
{"code":4,"description":"Ошибка обработки запроса","errorMessage":"ru.itone.dtm.data.uploader.upload.UploadException: ru.itone.dtm.prostore.rest.api.ProstoreRestException: Error executing query [insert into univer.slots select resource_id,slot_id,tag_type,tag_age,available_date,duration,slot_create_ts,slot_update_ts,slot_status,sys_op from univer.slots_upload_ext]: All of the connectors are failed\n\tat"}
{"code":5,"description":"Идентификатор запроса не обнаружен","errorMessage":null}
{"code":7,"description":"Ошибки ФЛК","errorMessage":null}
Идентификатор запроса можно получить в ответ от REST-Uploader:
POST'/v2/datamarts/{datamart_name}/tables/{table_name}/upload;POST'/v2/datamarts/{datamart_name}/tables/{table_name}/delete.
Код статуса |
Описание статуса |
Действия при получении данного статуса |
|---|---|---|
-1 |
Загрузка данных в буфер |
Данный статус клиентскому приложению не возвращается, ответ вернется после того как загружаемые данные будут сохранены приложением REST-Uploader для дальнейшей загрузки |
0 |
Запрос буферизирован |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30 сек. |
1 |
Ожидает открытия дельты |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30 сек. |
2 |
В обработке (модулем DATA-Uploader) |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30 сек. |
3 |
Успешно обработан |
Дополнительных действий не требуется |
4 |
Ошибка обработки запроса |
Необходимо:
|
5 |
Идентификатор запроса не обнаружен |
Использовать действующий идентификатор запроса |
6 |
Форматно-логический контроль |
Выполнить повторный запрос статуса с некоторой задержкой. Рекомендуемая задержка 30 сек. |
7 |
Ошибки ФЛК |
В процессе ФЛК выявлены ошибки, необходимо запросить отчет ФЛК, обратившись к
REST-Uploader c запросом Далее проанализировать и устранить выявленные недочеты в загружаемых данных или скорректировать проверки ФЛК |
[1] Указанные коннекторы используются для обратной совместимости по ETL: для перехода Компонета с версии 1.х на версию 2.х без изменений ETL. По умолчанию настроено без использования Kafka и коннекторов к нему.
2.4. Cвязи между модулями
Cвязи между модулями конфигурации Стандарт приведены в Таблица 2.46.
Клиент |
Сервер |
Способ взаимодействия |
Описание |
|---|---|---|---|
Prostore |
Сервисная база данных Prostore (PostgreSQL) |
JDBC |
Хранение/получение метаданных |
СУБД хранилища |
JDBC |
||
Apache Kafka |
REST API |
||
СМЭВ4 Адаптер |
REST API |
||
ETL |
REST API |
||
Prostore |
Хранилище СУБД |
JDBC |
Перенаправление запросов в конкретную СУБД |
CSV-Uploader |
Standart-Loader REST-Uploader Prostore |
REST API |
Исполнение запросов |
Standart-Loader |
Prostore |
Загрузка данных |
|
DATA-Uploader |
Prostore |
Загрузка данных |
|
DTM-Uploader |
Prostore |
Загрузка данных |
|
Сервис формирования документов |
Prostore |
REST API |
Запрашивает данные для формирования ПФ |
СМЭВ3-адаптер |
Prostore |
REST API |
Исполнение запросов |
BLOB-адаптер |
REST API |
Запрашивает бинарное содержимое BLOB. |
Cвязи между модулями конфигурации Лайт приведены в Таблица 2.47.
Клиент |
Сервер |
Способ взаимодействия |
Описание |
|---|---|---|---|
Prostore |
СУБД PostgreSQL |
REST API |
Управление логической структурой таблиц. Исполнение запросов. Управление загрузкой публикуемых данных в Витрину. |
CSV-Uploader |
Standart-Loader REST-Uploader Prostore |
REST API |
Исполнение запросов |
Standart-Loader |
Prostore |
Загрузка данных |
|
DATA-Uploader |
Prostore |
Загрузка данных |
2.5. Связи с другими программами
Взаимодействие с другими программами происходит путем вызова соответствующих модулей Компонента.
Связи Компонента с другими программами приведены в Таблица 2.48 .
Клиент |
Сервер |
Способ взаимодействия |
Описание |
|---|---|---|---|
Сервис формирования документов |
Агент СМЭВ4 |
REST |
|
BLOB-адаптер |
Агент СМЭВ4 |
REST |
|
Хранилище BLOB |
REST |
|
|
СМЭВ3-адаптер |
СМЭВ3 |
SOAP |
|
FTP-сервер СМЭВ3 |
FTP |
|
|
VipNet |
REST |
|
|
ETL |
Файловое хранилище ведомства |
S3, FTP и т.п. |
|
БД ведомства |
JDBC Driver |
|
|
Внутренняя ИС Ведомств |
Сервер конечных точек |
REST API |
|
Внутренняя ИС Ведомств |
Ядро витрины |
JDBC Driver |
|
Взаимодействие с другими программами происходит путем вызова соответствующих модулей Компонента:
Внутренняя ИС Ведомства взаимодействует с Prostore через JDBC-driver;
СМЭВ4-адаптер - Модуль исполнения запросов для взаимодействия с ИС участников взаимодействия через Агента СМЭВ4;
CSV-uploader для взаимодействия с ИС участников взаимодействия для передачи файлов в формате XML и CSV.
Связи Компонента со сторонними программами приведены в см. Таблица 2.49.
Клиент |
Сервер |
Способ взаимодействия |
Описание |
|---|---|---|---|
Внутренняя ИС Ведомств |
CSV-uploader |
Файловый обмен (CSV) REST |
|
Prostore |
JDBC |
|
2.6. Карта портов
Карта портов модулей Компонента представлена в Таблица 2.50.
Модуль |
Описание |
|---|---|
query-execution |
Порт: 8080 Протокол: HTTP Описание: номер порта сервиса метрик Порт: 9090 Протокол: TCP Описание: номер порта сервиса исполнения запросов |
prometheus |
Порт: 9090 Протокол: HTTP Описание: Подключение к Prometheus WEB UI |
grafana |
Порт: 3000 Протокол: HTTP Описание: WEB-интерфейс для работы c Grafana |
node_exporter |
Порт: 9100 Протокол: HTTP Описание: Порт для загрузки метрик |
filebeat |
Порт: нет открытых портов Протокол: - Описание: - |
mongodb |
Порт: 27017 Протокол:TCP Описание: Подключение к MongoDB. Порт по умолчанию для экземпляров mongod и mongos. Вы можете изменить этот порт с помощью port
или Порт: 27018 Протокол: TCP Описание: Подключение к MongoDB. Порт по умолчанию для mongod при запуске с параметром командной строки |
elasticsearch |
Порт: 9200 Протокол: HTTP Описание: Подключение к Elasticsearch. |
postgres |
Порт: 5432 Протокол: TCP PostgresSQL Protocol Описание: Источник данных SQL |
portainer |
Порт: 9000 Протокол: HTTP Описание: Web-интерфейс для работы c Portainer |