5. ВХОДНЫЕ И ВЫХОДНЫЕ ДАННЫЕ
5.1. СМЭВ3-адаптер
5.1.1. Pebble-шаблон
Обработка SOAP-запроса от СМЭВ 3 и формирование ответа производится на основании pebble-шаблона, указанного для данного ВС.
Для использования атрибутов запроса СМЭВ 3 при построении SQL-запросов, выполняемых к экземпляру Витрины, и результатов SQL-запросов при построении отправляемых ответов в дополнение к стандартным тэгам pebble используйте расширения:
xPath– для извлечения атрибутов запроса;var– для присвоения значений переменным;sql– для построения и выполнения SQL-запросов к Витрине.
Описание расширений приведено в разделе 4.3.2 Pebble-шаблон конечной точки.
Примечание: в СМЭВ3-адаптер расширение SQL не поддерживает
использование параметров запроса. Если необходимо динамически
подставлять значения в тело запроса, то рекомендуется формировать
запрос, используя расширение var. Например так:
{% var myQuery %} SELECT * FROM myDmrt.Tbl1 WHERE Number BETWEEN {{ minNum }} AND {{ maxNum }} {% endvar %} {{ sql(«result», myQuery) }} |
5.1.1.1. Информация о дельтах
Для определения наличия обновления данных и формирования выборки
обновленных данных в sql-запросе pebble-шаблона поддерживается
специальный параметр **@delta_param (<column_name>, <default_value>)**.
Атрибут <column_name> – имя колонки таблицы, максимальное значение
которой запоминается в журнале дельт, <default_value> – значение по
умолчанию, используемое если в журнале дельт еще нет значения из
предыдущей выборки.
Пример фрагмента pebble-шаблона:
{{ sql("myResult", "select \* from myTable where sinid > integer
@delta_param(sinid, ‘0’)") }}
Если в журнале дельт нет значения из предыдущей выборки, то будет выполнен запрос:
select * from myTable where sinid > 0
а если в журнале дельт ранее было сохранено значение 9, то будет выполнен запрос:
select * from myTable where sinid > 9
Если SQL-запрос вернул пустой результат, то результат рендеринга
pebble-шаблона не передается в СМЭВ. В одном шаблоне можно использовать
несколько SQL-запрос и в одном SQL запросе несколько параметров
@delta_param, для передачи результата в СМЭВ хотябы один запрос с
выборкой дельты должен вернуть не пустой результат.
5.2. ПОДД-адаптер
Взаимодействие ПОДД-адаптер с Агент ПОДД производится через список топиков брокера сообщений Kafka. Назначение и формат сообщений, последовательность обмена ими соответствуют документу «Методические рекомендации по работе с подсистемой обеспечения доступа к данным федеральной государственной информационной системы «Единая система межведомственного электронного взаимодействия»» (версия 1.0.0.0).
5.3. REST-адаптер
REST-адаптер представляет сервис предоставления данных, хранящихся в витрине в ответ на REST -запросы. Настройка конечных точек REST-адаптер производится через конфигурационные файлы.
5.3.1. Описание REST API (OpenAPI)
Имя этого файла должно быть указано в параметре swagger.file-path файла
application.yml. Этот файл описывает конечные точки подключения REST-адаптер согласно спецификации OpenAPI v3.0.
Пример:
+---------------------------------------------+
| **openapi**: 3.0.0 |
| |
| **info**: |
| |
| **title**: Sample API |
| |
| **version**: 0.1.9 |
| |
| **servers**: |
| |
| **- url**: / |
| |
| **paths**: |
| |
| **/report/query**: |
| |
| **get**: |
| |
| **summary**: Returns some value |
| |
| **operationId**: execquery |
| |
| **responses**: |
| |
| **'200'**: # status code |
| |
| **description**: A JSON array of user names |
| |
| **content**: |
| |
| **application/json**: |
| |
| **schema**: |
| |
| **type**: string |
+---------------------------------------------+
5.3.2. Pebble-шаблон конечной точки
Имя этого файла должно быть указано в файле application.yml в параметре
swagger.templates.<operationId> (где <operationId> – уникальный
идентификатор отдельной конечной точки). Этот файл содержит
pebble-шаблон, позволяющий на основании REST-запроса сформировать тело
REST-ответа.
5.3.2.1. Параметры строки запроса
Для использования параметров из строки REST-запроса в pebble-шаблоне достаточно обратиться к переменной с именем, равным нужному параметру.
Пример: REST-запрос
http://localhost:8080/report/query?param1=Dima¶m2=27
Pebble-шаблон:
{% if param1 != «Sasha» %} User’s age is {{ param2 }} {% endif %} |
5.3.2.2. Изменение кода ответа
Для указания нужного значения кода ответа в HTTP-ответе используйте конструкцию Pebble-шаблона:
{{ external_var(«http_code»,»404») }} |
5.3.2.3. xPath выражение
Для удобного получения данных из тела REST-запроса, имеющего формат xml, в pebble-шаблоне используйте расширение xpath, возвращающее вычисленное выражение.
{{ xpath(expression) }} |
Expression – строка, содержащая xPath-выражение.
Пример. Если тело REST-запроса содержало xml:
<User> <Name>Vasya</Name> </User> |
и Pebble-шаблон содержал:
User = _{{ xpath («/User/Name») }}_ |
, то тело REST-ответа будет содержать текст:
User = _Vasya_ |
5.3.2.4. SQL запрос к витрине
Для получения данных из витрины в pebble-шаблоне используйте расширение
sql.
{{ sql(result, query, param1, param2, …) }} |
result – переменная, в которую будет записан результат выполнения sql
запроса.
query – строка, содержащая sql запрос.
param1, param2, … – параметры, значение которых подставляются в строку
sql запроса вместо символа «?».
Пример подстановки параметров. Если в pebble-шаблоне указано:
{{ sql(«res», «select id, name from test where id = ?::integer and name like ?», Par1, Par2) }} |
и переменные Par1 =123, Par2 = «abc%», то к витрине будет вызван sql запрос:
select id, name from test where id = 123 and name like «abc%» |
Пример использования результатов sql запроса:
{{ sql(«result», «select id from test») }} {% for entity in rows.result %} {{ entity.id }} {% endfor %} |
5.3.2.5. Присвоение значения переменной
В дополнение к тэгу set, присваивающему значение переменной, можно
использовать расширение, позволяющего в присваиваемом тексте так же
использовать pebble-шаблон.
{% var name %} expression {% endvar %} |
name – переменная, в которую будет записан результат выражения
expression.
expression – любой текст (в т.ч. с pebble-шаблонами), который будет
записан в переменную.
Пример присвоения значения переменной MyQuery текста запроса, в который
условие отбора строк подставляется из ранее заполненной переменной
QueryCondition:
{% var MyQuery %} select VIN, BodyNum, EngineNum from vehicleTable {{ QueryCondition | raw }} {% endvar %} |
5.4. Сервис извлечения данных
5.4.1. JDBC-extractor
JDBC-extractor копирует данные из таблицы БД-источника (БД ведомства) в собственную БД-хранилища сервиса (Tarantool). Каждая импортированная
колонка в хранилище получает имя, равное имени в БД-источнике. Тип колонки в хранилище соответствует типу исходной колонки БД-источника. Список параметров и их назначение приведены в таблице ниже (см. tab_options_JDBC-extractor).
Параметр |
Описание |
|---|---|
source.url |
Connection string jdbc-источника данных (для подключения к БД-источнику). |
source.user |
Имя пользователя учетной записи БД-источника, от имени которой extractor будет обращаться. Пример: Admin |
source.password |
Пароль пользователя учетной записи БД-источника, от имени которой extractor будет обращаться. Пример: 12345 |
source.dbtable |
Имя таблицы из БД-источника, из которой будут извлекаться данные. Имя схемы указывается в source.url. Пример: SrcTable1 |
source.partitionColumn |
Имя колонки таблицы-источника, по которой записи будут различаться. Рекомендуется указывать имя колонки, являющейся первичным ключом. Пример: id |
source.lowerBound |
Минимальное значение в колонке source.partitionColumn, которое будет загружено. Пример: 2533422 |
source.upperBound |
Максимальное значение в колонке source.partitionColumn, которое будет загружено. Пример: 194180615 |
source.numPartitions |
Количество блоков, на которое будет разбито множество загружаемых строк. Рекомендуется указывать кратно количеству worker’ов Spark’а. Пример: 3 |
destination.format |
Имя класса используемой СУБД хранилища сервиса. Пример: ru.itone.etl.common.tarantool.TarantoolDataSource |
destination.url |
Connection string для подключения к СУБД хранилища сервиса. |
destination.user |
Имя пользователя учетной записи БД хранилища сервиса, от имени которой extractor будет обращаться. Пример: Admin |
destination.password |
Пароль пользователя учетной записи БД хранилища сервиса, от имени которой extractor будет обращаться. Пример: 12345 |
destination.dbtable |
Имя таблицы БД хранилища сервиса, в которую будут записываться данные. Имя схемы/пространства указывается в destination.url. Пример: ExtTable1 |
5.4.2. CSV-extractor
CSV-extractor копирует данные из csv-файла в собственную БД-хранилища сервиса (Tarantool). 1-я строка файла должна содержать данные. Имена и тип данных импортируемых в хранилище колонок задается в параметре source.schema. Список параметров и их назначение приведены в таблице ниже (см. tab_options_csv-extractor).
Параметр |
Описание |
|---|---|
source.delimiter |
Символ – разделитель полей csv файла. Пример: «,» (указывать без кавычек) |
source.quote |
Символ – ограничитель строковых значений csv файла. Пример: « |
source.charset |
Тип кодирования символов в csv файле. Пример: UTF-8 |
source.path |
Путь и имя csv файла. Пример: hdfs://192.168.0.103:54321/sample/MyFile.csv |
source.mode |
Режим чтения csv файла. Возможные варианты: PERMISSIVE – заменяет невалидные ячейки на null; DROPMALFORMED – пропускает невалидные строки; FAILFAST – прервет считывание всего файла, если встречается невалидная запись. |
source.schema |
Название и тип каждой импортируемой колонки в формате: Название1 Тип1, Название2 Тип2, … Поддерживаемые типы данных: integer, timestamp, date, boolean, double, float, long, short, byte, string Пример: id long, docType integer, docCode string |
loader.type |
Тип используемой СУБД хранилища сервиса. Пример: tarantool |
loader.propertyMap.url |
Connection string для подключения к СУБД хранилища сервиса. |
loader.propertyMap.user |
Имя пользователя учетной записи БД хранилища сервиса, от имени которой extractor будет обращаться. Пример: Admin |
loader.propertyMap.password |
Пароль пользователя учетной записи БД хранилища сервиса, от имени которой extractor будет обращаться. Пример: 12345 |
loader.propertyMap.dbtable |
Имя таблицы БД хранилища сервиса, в которую будут записываться данные. Имя схемы/пространства указывается в loader.propertyMap.url. Пример: ExtTable1 |
loader.propertyMap.mode |
Режим записи в БД хранилища сервиса. Возможны варианты: Append – дописывать к существующим; Overwrite – переписывать поверх существующих; ErrorIfExists – прерывать запись, если существует; Ignore – пропускать, сохраняя существующее. |
5.4.3. XML-extractor
XML-extractor копирует данные из xml-файла в собственную БД-хранилища
сервиса (Tarantool) без преобразований, добавляя новую строку в таблицу:
- в ID новой записи присваивается уникальный идентификатор записи;
- в VALUE записывается содержимое всего xml-файла.
Список параметров и их назначение приведены в таблице ниже (Таблица 9).
Таблица 9. Параметры xml-extractor
Параметр |
Описание |
|---|---|
source.file |
Путь и имя xml файла. Пример: hdf s://192.168.0.103:54321/sample/MyFile.xml |
destination.format |
Имя класса используемой СУБД хранилища сервиса. Пример: ru.itone .etl.common.tarantool.TarantoolDataSource |
destination.url |
Connection string для подключения к СУБД хранилища сервиса. Пример: jdb c:tarantool://192.168.0102:12345/ExtSpace |
destination.user |
Имя пользователя учетной записи БД хранилища сервиса, от имени которой extractor будет обращаться. Пример: Admin |
destination.password |
Пароль пользователя учетной записи БД хранилища сервиса, от имени которой extractor будет обращаться. Пример: 12345 |
destination.dbtable |
Имя таблицы БД хранилища сервиса, в которую будут записываться данные. Имя схемы/пространства указывается в destination.url. Пример: ExtTable1 |
loader.propertyMap.mode |
Режим записи в БД хранилища сервиса. Возможны варианты: Append – дописывать к существующим; Overwrite – переписывать поверх существующих; ErrorIfExists – прерывать запись, если существует; Ignore – пропускать, сохраняя существующее. |
5.4.4. JDBC-CSV-transformer
JDBC-CSV-transformer - cпециализированное программное обеспечение, которое предназначено для подключения к БД по JDBC, с последующим сохранением в csv-файлы. Список параметров и их назначение приведен в таблице ниже (Таблица 10).
Таблица 10. Параметры jdbc_csv transformer
Параметр |
Описание |
|---|---|
source.url |
Connection string для подключения к СУБД хранилища сервиса, содержащего преобразуемые данные. Пример: jdbc:taranto ol://192.168.0102:12345/ExtSpace |
source.user |
Имя пользователя учетной записи БД хранилища , содержащего преобразуемые данные, от имени которой extractor будет обращаться. Пример: Admin |
source.password |
Пароль пользователя учетной записи БД хранилища сервиса, содержащего преобразуемые данные, от имени которой extractor будет обращаться. Пример: 12345 |
source.dbtable |
Имя таблицы в БД хранилища сервиса, содержащего преобразуемые данные. Имя схемы/пространства указывается в source.url. Пример: ExtTable1 |
source.partitionColumn |
Имя колонки в таблице БД хранилища сервиса, содержащего преобразуемые данные, по которой записи будут различаться. Рекомендуется указывать имя колонки, являющейся первичным ключом. Пример: id |
source.lowerBound |
Минимальное значение в колонке source.partitionColumn, которое будет преобразовано. Пример: 2533422 |
source.upperBound |
Максимальное значение в колонке source.partitionColumn, которое будет преобразовано. Пример: 194180615 |
source.numPartitions |
Количество блоков, на которое будет разбито множество преобразуемых записей. Рекомендуется указывать кратно количеству worker’ов Spark’а. Пример: 3 |
destination.format |
Имя класса используемой СУБД хранилища сервиса. Пример: ru.itone.etl.comm on.tarantool.TarantoolDataSource |
destination.url |
Connection string для подключения к СУБД хранилища сервиса, содержащего преобразованные данные. Пример: jdbc:taranto ol://192.168.0102:12345/ExtSpace |
destination.user |
Имя пользователя учетной записи БД хранилища , содержащего преобразованные данные, от имени которой extractor будет обращаться. Пример: Admin |
destination.password |
Пароль пользователя учетной записи БД хранилища сервиса, содержащего преобразованные данные, от имени которой extractor будет обращаться. Пример: 12345 |
destination.dbtable |
Имя таблицы в БД хранилища сервиса, содержащего преобразованные данные. Имя схемы/пространства указывается в destination.url. Пример: TransTable1 |
desti nation.tarantool.partitionColumn |
Имя колонки в таблице БД хранилища сервиса, содержащей преобразованные данные, по которой записи будут различаться. Рекомендуется указывать имя колонки, являющейся первичным ключом. Пример: Identitydocumentid |
5.4.5. XML-transformer
Из загруженного xml extractor’ом файла данные можно извлекать сразу в несколько таблиц одним трансформером. Список параметров и их назначение приведены в таблице ниже (Таблица 11).
Пример (фрагмент) описания полей двух таблиц, выгружаемых из одного xml:
Таблица 11. Параметры xml transformer
Параметр |
Описание |
|---|---|
source.db.url |
Connection string для подключения к СУБД хранилища сервиса, содержащего преобразуемые данные. Пример: jdbc:tara ntool://192.168.0102:12345/ExtSpace |
source.db.user |
Имя пользователя учетной записи БД хранилища , содержащего преобразуемые данные, от имени которой extractor будет обращаться. Пример: Admin |
source.db.password |
Пароль пользователя учетной записи БД хранилища сервиса, содержащего преобразуемые данные, от имени которой extractor будет обращаться. Пример: 12345 |
source.db.dbtable |
Имя таблицы в БД хранилища сервиса, содержащего преобразуемые данные. Имя схемы/пространства указывается в source.url. Пример: ExtTable1 |
source.xmlcolumn |
Имя колонки в таблице, содержащей трансформируемые xml файлы. Пример: VALUE |
destination.format |
Имя класса используемой СУБД хранилища сервиса. Пример: ru.itone.etl.c ommon.tarantool.TarantoolDataSource |
destination.url |
Connection string для подключения к СУБД хранилища сервиса, содержащего преобразованные данные. Пример: jdbc:tara ntool://192.168.0102:12345/ExtSpace |
destination.user |
Имя пользователя учетной записи БД хранилища , содержащего преобразованные данные, от имени которой extractor будет обращаться. Пример: Admin |
destination.password |
Пароль пользователя учетной записи БД хранилища сервиса, содержащего преобразованные данные, от имени которой extractor будет обращаться. Пример: 12345 |
source.get.{nick}.name |
Имя таблицы в БД хранилища сервиса, содержащего преобразованные данные. Имя схемы/пространства указывается в destination.url. Вместо {nick} указывать уникальное (в рамках этого файла) имя для объединения остальных параметров трансформации для этой же таблицы. Пример: source.get.emp.name=TransTable1 |
source.get.{nick}.root |
xPath-выражение, указывающее имя элементов, содержащих данные записей для таблицы nick. Пример: source.get.e mp.root=/office/department/employee |
source.get.{nick}.col.{Field} |
Указывает как заполнить поле с именем Field записи таблицы nick данными из подэлемента или атрибута элемента, указанного в source.get.{nick}.root. Так же указывается тип данных, к которому следует преобразовать значение элемента/атрибута. Считать из элемента: Путь/Имя~>Тип Считать из атрибута: Путь/@Имя~>Тип Путь – выражение типа [ext:/]/Имя/Имя… , указывающее путь от элемента source.get.{nick}.root (если ext:/ отсутствует) или от корня xml (если ext:/ присутствует) до нужного элемента. Путь может быть пустым. Для элемента в пути м.б. указано условие. Например: /equipment/item[@type=“1“]/device Тип может быть: integer, timestamp, date, boolean, double, float, long, short, byte, string. Для типов date и timestamp требуется указать формат преобразования. Пример: /birthdate~>date(yyyy.MM.dd) |
5.4.6. Kafka loader
Конфигурационный файл Loader’а для REST-адаптер. Список параметров, которые необходимо настроить, и их назначения приведены в таблице ниже (Таблица 12). Остальные параметры следует оставить без изменения.
Таблица 12. Параметры kafka loader
Параметр |
Значение |
|---|---|
dtm.schema |
Схема, описывающая структуру выгружаемых данных. Формат – json. |
dtm.location |
Список серверов (с портами) zookeeper, на которых работают серверы kafka. Формат: k afka://host1:port1,host2:port2,… Пример: kafka://zkhost 1:3888,zkhost2:3888,zkhost3:3888 |
dtm.datasource.url |
Connection string для подключения jdbc драйвера к Витрине. Пример: jdbc:adtm://localhost:8080 |
dtm. kafka.producer.bootstrap-servers |
Список серверов (с портами), на которых работают серверы kafka. Формат: k afka://host1:port1,host2:port2,… Пример: kafka://zkhost 1:9092,zkhost2:9092,zkhost3:9092 |
vinyl.datasource.url |
Connection string для подключения к СУБД хранилища сервиса, содержащего записываемые данные. Пример: jdbc:tarantool://192.168.01 02:12345?user=admin&password=123 |
vinyl.read-sql |
SQL запрос, извлекающий записываемые данные из СУБД хранилища сервиса. Пример: SELECT * FROM ResSpace.tbl1; |
5.4.6.1. Схема описания структуры выгружаемых данных
Схема выгружаемых таблиц описывается в json-формате. Названия значений, тип их значений и назначение приведены в таблицах ниже (Таблица 13, Таблица 14, Таблица 15).
Таблица 13. Схема описания структуры выгружаемых таблиц
Имя |
Тип |
Описание |
|---|---|---|
db |
Строка |
Название datamart. |
tables |
Массив |
Список объектов, каждый из них описывает 1 таблицу (Таблица 14). |
Таблица 14. Объект, описывающий 1 таблицу datamart
Имя |
Тип |
Описание |
|---|---|---|
name |
Строка |
Имя таблицы. |
primaryKey |
Строка |
Имя поля, являющегося первичным ключом этой таблицы. |
columns |
Массив |
Список объектов, каждый из них описывает 1 поле таблицы (Таблица 15). |
Таблица 15. Объект, описывающий 1 поле таблицы
Имя |
Тип |
Описание |
|---|---|---|
name |
Строка |
Имя поля таблицы. |
type |
Строка |
Имя типа поля (Таблица 16). |
notNull |
Логическое |
Обязательность поля таблицы. Необязательное значение, если отсутствует, принимается равным false. |
Пример описания структуры выгружаемых данных:
{ «db»: «myTest», «tables»: [ { «name»: «myTable1», «primaryKey»: «Id», «columns»: [ { «name»: «Id», «type»: «INT», «notNull»: true }, { «name»: «DocId», «type»: «UUID» }, { «name»: «Remark», «type»: «VARCHAR(255)» }, { «name»: «Total», «type»: «DOUBLE» }, { «name»: «DocDateTime», «type»: «TIMESTAMP» }, { «name»: «IsEmpty», «type»: «BOOLEAN» } ] } ] } |
5.5. JDBC-драйвер
В состав логической модели данных витрины входят сущности следующего вида:
Датамарт - именованная совокупность множества логических таблиц и логических представлений. В рамках одной инсталляции Программы «Витрина данных НСУД» возможно существование множества датамартов.
Логическая таблица (таблица) – структура, объединяющая множество записей, поддерживающая типизацию атрибутов, определение первичного ключа и ключа шардирования.
Логическое представление (представление) – сохраненный SQL запрос к логическим таблицам.
Хранение мета-данных логической модели обеспечиваться Сервисной БД.
Для каждой создаваемой логической таблицы выполняется автоматическое создание соответствующих таблиц физического Хранилища данных.
Удаление логических таблиц приводит к автоматическому удалению соответствующих таблиц физического Хранилища данных.
5.5.1. Типы данных
Программа «Витрина данных НСУД» поддерживает использование типов данных, приведенных в таблице ниже (Таблица 16).
Типы данных TIME и TIMESTAMP записываются и считываются без часового пояса и интерпретируются как Local Time Zone.
Таблица 16. Поддерживаемые типы данных
Логический тип |
Описание |
|---|---|
BOOLEAN |
Логический тип |
VARCHAR (n) |
Строка ограниченной длины (n символов) |
CHAR (n) |
Строка ограниченной длины (n символов) |
UUID |
Строка ограниченной длины (36 символов) |
BIGINT |
Целые числа фиксированной длины, со знаком в диапазоне от -9223372036854775808 до 9223372036854775807 |
INT |
Целые числа фиксированной длины, со знаком в диапазоне от -9223372036854775808 до 9223372036854775807 |
DOUBLE |
Число с плавающей запятой с двойной точностью |
FLOAT |
Число с плавающей запятой |
DATE |
Дата (без времени суток) |
TIME, TIME (точность) По умолчанию точность = 6 |
Время (без даты). Заданная точность от 0 (секунды) до 6 (микросекунды) влияет только на отображение. |
TIMESTAMP, TIMESTAMP (точность) По умолчанию точность = 6 |
Дата и время. Заданная точность от 0 (секунды) до 6 (микросекунды) влияет только на отображение. |
5.5.1.1. Формат AVRO
При передаче записываемых/считываемых данных через брокер сообщений
Kafka (SQL``+ ``EDML) передается бинарный Avro-файл, содержащий Avro-схему и
Avro-данные. Соответствие типов данных, используемых при загрузке и
выгрузке данных Витрины через Avro, приведено в таблице ниже (Таблица
17).
Таблица 17. Соответствие типов данных AVRO и Витрины
Витрина |
AVRO (загрузка) |
ADB AVRO (выгрузка) |
ADG AVRO (выгрузка) |
ADQM AVRO (выгрузка) |
|---|---|---|---|---|
BOOLEAN |
boolean |
boolean |
boolean |
int |
VARCHAR (n) |
string |
string |
string |
string |
CHAR (n) |
string |
string |
string |
string |
UUID |
string |
string |
string |
string |
BIGINT |
long |
long |
long |
long |
INT |
long |
long |
long |
long |
DOUBLE |
double |
double |
double |
double |
FLOAT |
float |
float |
float |
float |
DATE |
(int) date |
(int) date |
int |
int |
TIME (точность) |
(long) time-micros |
(long) time-micros |
long |
long |
TIMESTAMP (точность) |
(long) times tamp-micros |
(long) times tamp-micros |
long |
(long) times tamp-micros |
Для описания формата данных используется Avro-схема, использующая язык, основанный на JSON. Более подробно Avro формат описан в Apache Avro 1.10.0 Specification.
Данные передаются в бинарном виде как последовательность записей, соответствующих структуре схемы.
5.5.2. Массивно-параллельная запись
Этот механизм используется для обеспечения массивно-параллельного консистентного обновления (вставка, обновление, удаление) записей логических таблиц в Витрину.
5.5.2.1. Назначение
создание внешних
UPLOADтаблиц загрузки;определение начала и окончания загрузки дельты;
загрузка данных дельты через внешние
UPLOADтаблицы загрузки в физические таблицы хранилища данных, включая перенос старых записей из таблицы данных в таблицу истории;обеспечить консистентное обновление записей логических таблиц в Витрине в рамках дельты;
обеспечить атомарность операций загрузки данных.
5.5.2.2. Ограничения и допущения
входящие сообщения Kafka, для каждой удаляемой записи логической таблицы содержат признак sys_op (int) = 1;
поиск существующих записей логической таблицы (для добавления/обновления и удаления) производится по первичному ключу;
начало следующей дельты возможно только после завершения (commit / rollback) предыдущей дельты;
операция записи атомарна;
в пределах одной дельты может произойти одно изменение одной записи логической таблицы;
допускаются повторяющиеся изменения одной записи логической таблицы в пределах одной дельты – дубликаты будут сохранены как однозначное изменение записи в пределах дельты;
не предполагается нумерация входящих сообщений Kafka;
гарантируется, что данные из прочитанных (комит чтения) сообщений Kafka загружены в Витрину;
окончание потока сообщений Kafka определяется по заданному в конфигурации таймауту ожидания сообщений kafka (максимально допустимый интервал времени ожидания сообщений kafka в рамкахпотока);
5.5.2.3. Входные данные
JDBC подключение к Витрине;
топик Kafka, содержащий загружаемые данные;
номер дельты [необязательно];
дата-время дельты [необязательно].
5.5.2.4. Выходные данные (SUCCESS)
загружены данные в физические таблицы хранилища данных, включая перенос старых записей из таблицы данных в таблицу истории;
выполнен комит чтения для входящих сообщения Kafka;
увеличен номер последней загруженной дельты в Витрине.
5.5.2.5. Выходные данные (FAIL)
частично загружены данные в физические таблицы хранилища данных, включая перенос старых записей из таблицы данных в таблицу истории;
выполнен комит чтения для части входящих сообщения Kafka, которые были загружены в СУБД хранилища данных;
не изменился номер последней загруженной дельты в Витрине;
сформировано сообщение об ошибке в ответ на входящий JDBC запрос;
зафиксирована ошибка загрузки дельты.
5.5.2.6. Последовательность
Создать топик Kafka, из которого будут загружаться данные в Витрину.
Загрузить передаваемые в Витрину данные в топик Kafka (1).
Создать внешнюю таблицу, связанную с топиком Kafka (1).
Пример: CREATE UPLOAD EXTERNAL TABLE tblExt (column1 datatype1, column2 datatype2, …) LOCATION „kafka://$kafka/topicY“
Открыть новую дельту.
Пример: BEGIN DELTA
Вставить данные из внешней таблицы (3) в таблицу Витрины.
Пример: INSERT INTO tbl1 SELECT column1, column2 FROM tblExt
Завершить открытую дельту для фиксации изменений в витрину. Пример: COMMIT DELTA
Удалить внешнюю таблицу (3).
Пример: DROP UPLOAD EXTERNAL TABLE tblExt
Удалить топик Kafka (1).
5.5.2.7. Данные в топике Kafka
Содержит загружаемые в Витрину данные.
Формат сообщения AVRO.
Ключ сообщения – требования не предъявляются.
Тело сообщения содержит бинарный файл AVRO, состоящий из схемы AVRO и записываемых объектов (рекордов) AVRO, соответствующих схеме.
Таблица 18. Пример тела сообщения
Схема |
|---|
{ «name»: «doc», «type»: «record», «fields»: [ { «name»: «id», «type»: «int» }, { «name»: «title», «type»: «string» }, { «name»: «exp», «type»: «int», «logicalType»: «date» }, { «name»: «dsc», «type»: [ «string», «null» ] }, { «name»: «sys_op», «type»: «int» } ] } |
Объекты (рекорды) |
{ «id» : 1111, «title»: «test1», «exp»: «2022-03-31T00:00:00», «dsc»: «comment», «sys_op»: 0 } { «id» : 22222, «title»: «test2», «exp»: «2022-03-31T00:00:00», «dsc»: null, «sys_op»: 1 } |
5.5.3. Массивно-параллельное чтение
Этот механизм используется для обеспечения высокопроизводительной выгрузки данных из Витрины.
5.5.3.1. Назначение
создание внешних таблиц выгрузки по SQL-запросу JDBC;
заполнение внешних таблиц выгрузки данными по SQL-запросу JDBC;
удаление внешних таблиц выгрузки по SQL-запросу JDBC.
5.5.3.2. Ограничения и допущения
нет автоматического создания/удаления топиков Kafka;
нет автоматического удаления внешних таблиц выгрузки;
внешние таблицы выгрузки не являются Writable External Table СУБД хранилища данных;
количество строк в одном сообщении регулируется базовыми настройками Витрины;
запрос на выборку данных может выполняться произвольное количество раз после создания внешней таблицы выгрузки;
определение целевой СУБД выгрузки данных производится на основании конфигурации Витрины.
5.5.3.3. Входные данные
внешнее JDBC подключение к Витрине;
топик kafka, в который будут выгружены данные;
SQL+ EDMLзапрос данных.
5.5.3.4. Выходные данные
запрошенные данные, разделенные на потоки и части, в виде сообщений указанного топика Kafka.
5.5.3.5. Последовательность
Создать топик в Kafka, в который должны быть выгружены данные.
Создать внешнюю таблицу, связанную с топиком Kafka (1).
Пример:
CREATE DOWNLOAD EXTERNAL TABLE tblExt (column1 datatype1,
column2 datatype2, ...) LOCATION 'kafka://$kafka/topicX'...
Выгрузить строки результата запроса во внешнюю таблицу (2).
Пример: INSERT INTO tblExt SELECT [columns] FROM tbl1 WHERE [condition]…
Удалить внешнюю таблицу (2).
Пример: DROP DOWNLOAD EXTERNAL TABLE tblExt
Считать итоговые строки из топика Kafka (1).
Удалить топик Kafka (1).
5.5.3.6. Данные в топике Kafka
Содержит считываемые из Витрины данные.
Формат сообщения AVRO.
Ключ сообщения содержит управляющую информацию, состоящую из Avro-схемы и Avro-данных. Структура ключа сообщения приведена в таблице ниже (Таблица 19).
Таблица 19. Ключ сообщения
Схема |
|---|
{ «name»: «key», «type»: «record», «fields»: [ {«name»: «tableName», «type»: «string»}, {«name»: «streamNumber», «type»: «int»}, {«name»: «streamTotal», «type»: «int»}, {«name»: «chunkNumber», «type»: «int»}, {«name»: «isLastChunk», «type»: «boolean»} ] } |
Объект |
{ «tableName»: «tbl1», «streamNumber»: 1, «streamTotal»: 2, «chunkNumber»: 3, «isLastChunk»: false } |
Назначение параметров данных ключа приведено в таблице ниже (Таблица 20)
Таблица 20. Назначение параметров ключа сообщения
Параметр |
Назначение |
|---|---|
tableName |
имя таблицы |
streamNumber |
номер потока выгрузки (начиная с 0) |
streamTotal |
общее количество потоков выгрузки |
chunkNumber |
порядковый номер пакета в рамках потока (начиная с 0) |
isLastChunk |
признак последнего пакета в рамках потока |
Тело сообщения содержит бинарный файл AVRO, состоящий из схемы AVRO и считываемых объектов (рекордов) AVRO, соответствующих схеме.
Таблица 21. Пример тела сообщения
Схема |
|---|
{ «name»: «doc», «type»: «record», «fields»: [ { «name»: «id», «type»: «int» }, { «name»: «title», «type»: «string» }, { «name»: «exp», «type»: «int», «logicalType»: «date» }, { «name»: «dsc», «type»: [ «string», «null» ] }, { «name»: «sys_op», «type»: «int» } ] } |
Объекты (рекорды) |
{ «id» : 1111, «title»: «test1», «exp»: «2022-03-31T00:00:00», «dsc»: «comment», «sys_op»: 0 } { «id» : 22222, «title»: «test2», «exp»: «2022-03-31T00:00:00», «dsc»: null, «sys_op»: 1 } |
5.5.4. Чтение с минимальной задержкой
Этот механизм используется для оперативного (с минимальной задержкой) считывания из Витрины данных малых объемов строк (по умолчанию – до 1000).
5.5.4.1. Назначение
выборка строк Витрины по заданной метке времени с минимальной задержкой;
возвращает запрошенные строки в соответствии с
SQL+ DMLвыражением.
5.5.4.2. Входные данные
внешнее JDBC подключение к Витрине;
SQL+ DMLзапрос данных.
5.5.4.3. Выходные данные
запрошенные данные в ответе на запрос в самом JDBC драйвере.
5.5.4.4. Последовательность
Составить и выполните запрос
SQL+ DMLс использованием подключения JDBC.Дождаться выполнения запроса.
Получить результат запроса (строки) из подключения JDBC.
5.5.5. SQL+
Программа «Витрина данных НСУД» поддерживает использование SQL как базовый способ доступа к данным, хранимым в экземпляре Программы.
5.5.5.1. CREATE DATABASE
Инструкция создает новый datamart.
CREATE DATABASE datamart |
datamart – имя создаваемого datamart
Если datamart с таким именем уже существует, то инструкция завершится с ошибкой «Database <datamart> already exists.».
5.5.5.2. DROP DATABASE
Инструкция удаляет существующий datamart.
DROP DATABASE datamart |
datamart– имя удаляемого datamart.
Если datamart с таким именем не существует, то инструкция завершится с ошибкой «Database <datamart> does not exist.».
При попытке удалить служебный datamart инструкция завершится с ошибкой «System database INFORMATION_SCHEMA is non-deletable».
5.5.5.3. CREATE TABLE
Инструкция создает новую логическую таблицу в datamart.
CREATE TABLE [datamart].table_name ( col1 datatype1 [ NULL | NOT NULL ], col2 datatype2 [ NULL | NOT NULL ], …, PRIMARY KEY (col1, col2, …) ) DISTRIBUTED BY (col1, col2, …) [DATASOURCE_TYPE (storage_db_expr)] |
datamart – имя datamart, которому принадлежит логическая таблица.
table_name – имя создаваемой логической таблицы.
В разделе PRIMARY KEY указывается список столбцов, входящих в первичный
ключ.
В разделе DISTRIBUTED BY указывается список столбцов ключа шардирования.
В разделе DATASOURCE_TYPE указывается сочетание физических СУБД
хранилища Витрины, в которых будет физически размещаться таблица. Если
выражение отсутствует, то во всех СУБД хранилища, соответствующих
конфигурации ADTM на момент исполнения запроса.
storage_db_expr – не пустой, разделенный запятыми список плагинов.
Возможные значения: „adb“, „adqm“, „adg“.
Ограничения:
в логических таблицах нельзя создавать поля с именами:
sys_op,sys_close_date,sys_from,sys_to. Эти служебные поля добавляются автоматически;PRIMARY KEYиDISTRIBUTED BYобязательны к указанию;DISTRIBUTED KEYдолжен входить в составPRIMARY KEY. Другими словами,PRIMARY KEYдолжен содержатьDISTRIBUTED KEY;DISTRIBUTED KEYможет содержать только целочисленные поля.
Если datamart с таким именем не существует, то инструкция завершится с ошибкой «Database <datamart> does not exist».
Если таблица с таким именем уже существует, то инструкция завершится с ошибкой «Entity <entity_name> already exists.».
Пример с ключом шардирования
CREATE TABLE RUS.instructor ( identification_number INT NOT NULL, city_name VARCHAR(256) NOT NULL, call_sign VARCHAR(256), sports_association VARCHAR(256), RIMARY KEY (identification_number) ) DISTRIBUTED BY (identification_number) |
Пример с составным первичным ключом
CREATE TABLE MOS.address ( postal_code INT NOT NULL, city_area INT NOT NULL, street_name VARCHAR(256) NOT NULL, metro_station VARCHAR(256), PRIMARY KEY (postal_code, street_name) ) DISTRIBUTED BY (city_area) |
5.5.5.4. DROP TABLE
Инструкция удаляет существующую логическую таблицу из datamart.
DROP TABLE [IF EXISTS] [datamart].table_name [DATASOURCE_TYPE = „adb“|“adqm“|“adg“] |
datamart – имя datamart, которому принадлежит логическая таблица.
table_name – имя логической таблицы, которую требуется удалить.
Раздел DATASOURCE_TYPE содержит указание на СУБД хранилища Витрины, в
которой будет физически удалена таблица. Если не заполнено, то таблица
будет удалена во всех СУБД хранилища.
Если datamart или логическая таблица с таким именем не существует и не
используется директива IF EXISTS, то инструкция завершится с ошибкой
«Entity <entity_name> does not exist.».
5.5.5.5. CREATE VIEW
Инструкция создает новое логическое представление в datamart.
CREATE [OR REPLACE] VIEW [datamart].view_name AS sql_dml_select_expression |
datamart – имя datamart, которому принадлежит логическое представление.
view_name – имя создаваемого логического представления
sql_dml_select_expression – выражение SELECT.
Ограничения:
в запросе
sql_dml_select_expressionне допускается:использование логических представлений;
использование системных представлений
INFORMATION_SCHEMA;упоминание директивы
FOR SYSTEM_TIME.
Если логическое представление с именем view_name уже существует и не
указана директива OR REPLACE, то инструкция завершится с ошибкой «Entity
<view_name> already exists.».
5.5.5.6. ALTER VIEW
Инструкция заменяет существующее в datamart логическое представление
новым.
CREATE [OR REPLACE] VIEW [datamart].view_name AS sql_dml_select_expression |
datamart – имя datamart, которому принадлежит логическое представление.
view_name – имя логического представления.
sql_dml_select_expression – выражение SELECT.
Ограничения:
в запросе
sql_dml_select_expressionне допускается:использование логических представлений;
использование системных представлений
INFORMATION_SCHEMA;упоминание директивы
FOR SYSTEM_TIME.
Если логическое представление с указанным именем не существует, то инструкция завершится с ошибкой «View <view_name> does not exist.».
Если выражение sql_dml_select_expression содержит недопустимые элементы, то инструкция завершится с ошибкой «Disallowed view or directive in a subquery <sql_dml_select_expression>.».
5.5.5.7. DROP VIEW
Инструкция удаляет существующее в datamart логическое представление.
DROP VIEW [datamart].view_name |
datamart – имя datamart, которому принадлежит логическое представление.
view_name - имя удаляемого логического представления
Если логического представления с таким именем не существует, то инструкция завершится с ошибкой «View <view_name> does not exist.».
5.5.5.8. TRUNCATE HISTORY
Инструкция обрезает историю логической таблицы согласно переданной отметке даты и времени.
TRUNCATE HISTORY [datamart].table_name FOR SYSTEM_TIME AS OF „<datetime_expression>“ [WHERE filter_expression] |
datamart – имя datamart, которому принадлежит логическая таблица.
table_name – имя логической таблицы.
datetime_expression – дата и время в формате YYYY-MM-DD hh:mm:ss с
которого начинаются актуальные данные. Если datetime_expression содержит
ключевое слово infinite, то все данные рассматриваются как
исторические и будут усечены.
filter_expression – логическое выражение, принимающее значение true
или false.
Ограничение:
Эта инструкция выполняется вне рамок открытой дельты.
Если datamart или логическая таблица с таким именем не существует, то
инструкция завершится с ошибкой «Entity <entity_name> does not exist.».
5.5.5.9. BEGIN DELTA
Инструкция открывает новую дельту для массивно-параллельной загрузки.
BEGIN DELTA [SET num] |
num – целое число. Номер дельты.
Повторный вызов BEGIN DELTA до вызова COMMIT DELTA вызовет ошибку.
Если дельта уже открыта, то инструкция завершится с ошибкой «The delta <num> is not committed.».
BEGIN DELTA SET num вызовет ошибку «The delta number <num> is not
next to an actual delta.», если num не равен последней загруженной
дельте + 1.
Пример:
BEGIN DELTA SET 100 |
COMMIT DELTA
Закрывает дельту, открытую инструкцией BEGIN DELTA при выполнении массивно-параллельной загрузки.
COMMIT DELTA [SET „date-time“] |
date-time – строка. Дата и время закрытия дельты в формате YYYY-MM-DD
HH:MM:SS.
Если дата и время предыдущей закрытой (актуальной) дельты больше или равно заданному значению date-time, то инструкция завершится ошибкой «Unable to set the date-time <date-time> preceding the actual delta.».
Вызов COMMIT DELTA до вызова BEGIN DELTA вызовет ошибку «Delta is
already commited.».
Пример
COMMIT DELTA SET „2020-08-02 09:09:09“ |
5.5.5.10. ROLLBACK DELTA
Отменяет (откатывает) ранее начатую дельту.
ROLLBACK DELTA |
Повторный вызов ROLLBACK DELTA до вызова BEGIN DELTA вызовет ошибку
«Can’t rollback delta by datamart <datamart>».
5.5.5.11. GET_DELTA_HOT
Возвращает атрибуты текущей не завершенной дельты.
GET_DELTA_HOT() |
Атрибуты дельты:
delta_num – 64-битный номер дельты.
delta_date – дата и время закрытия дельты (см. COMMIT DELTA).
cn_from – 64-битный номер первой операции записи (sys_cn), произведенной
в этой дельте.
cn_to – 64-битный номер последней операции записи (sys_cn) в непрерывной
последовательности завершенных операций, произведенных в этой дельте.
cn_max – 64-битный max номер завершенной операции записи (sys_cn), среди
завершенных в этой дельте.
is_rolling_back– логический флаг «начата операция отмены дельты».
Пример: Если уже завершенны операции sys_cn = 1,2,3,7 и все еще
выполняются операции sys_cn = 4,5,6,8,9,10, то для этой горячей дельты
cn_to = 3, cn_max = 7.
Отличие последней закрытой (актуальной) дельты (delta_ok) от текущей
незавершенной (горячей) дельты (delta_hot) изображено на Рисунок 3
– Отличие закрытой, актуальной и горячей дельт.
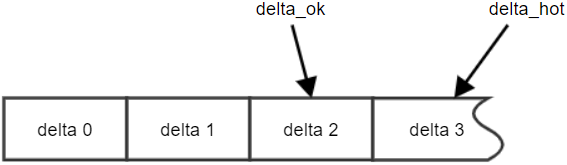
Отличие закрытой, актуальной и горячей дельт.
Распределение операций записи (write operation) по дельтам поясняет
Рисунок 4 –Распределение операций записи по дельтам.
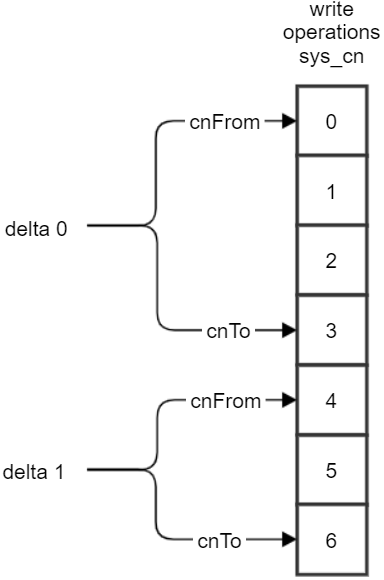
Распределение операций записи по дельтам.
5.5.5.12. GET_DELTA_OK
Возвращает атрибуты последней завершенной (актуальной) дельты.
GET_DELTA_OK() |
Возвращает атрибуты: delta_num, delta_date, cn_from, cn_to. Более
подробно об атрибутах см. 4.5.5.12 GET_DELTA_HOT.
5.5.5.13. GET_DELTA_BY_DATETIME
Возвращает атрибуты последней завершенной (актуальной) дельты на момент указанной даты-времени (или перед ним).
GET_DELTA_BY_DATETIME(„datetime_expr“) |
datetime_expr – дата и время в формате «YYYY-MM-DD HH:MM:SS».
Возвращает атрибуты: delta_num, delta_date, cn_from, cn_to. Более подробно об атрибутах см. 4.5.5.12 GET_DELTA_HOT.
Если дата и время первой закрытой дельты больше заданного значения date-time, то инструкция завершится ошибкой «Delta not exist».
5.5.5.14. GET_DELTA_BY_NUM
Возвращает атрибуты завершенной дельты, имеющей указанный номер.
GET_DELTA_BY_NUM (int_expr) |
int_expr – неотрицательный номер закрытой дельты.
Возвращает атрибуты: delta_num, delta_date, cn_from, cn_to. Более подробно об атрибутах см. 4.5.5.12 GET_DELTA_HOT.
Если указан отрицательный номер дельты, то инструкция завершится ошибкой «Negative delta number is unexpected.».
Если номер последней закрытой (актуальной) дельты меньше заданному значению int_expr, то инструкция завершится ошибкой «Delta not exist».
5.5.5.15. USE
Инструкция изменяет контекст на указанный datamart.
USE datamart |
Если datamart с таким именем не существует, то инструкция завершится с ошибкой «Database <datamart> does not exist.».
5.5.5.16. SELECT
Инструкция позволяет запросить данные из витрины.
SELECT columns_list FROM [datamart].table_name_1 [AS alias_name_1] [FOR SYSTEM_TIME for_system_time] [[join_prefix] JOIN [datamart].table_name_2 [AS alias_name_2] [FOR SYSTEM_TIME for_system_time] ON join_condition] [WHERE filter_expression] [GROUP BY expr_list] [ORDER BY sort_expression_list] [LIMIT n] [DATASOURCE_TYPE = database] |
columns_list – список столбцов.
table_name_1, table_name_2 – имена логических таблиц.
alias_name_1, alias_name_2 – псевдонимы для [datamart].table_name_1 и [datamart].table_name_2 соответственно.
filter_expression – определяет условие, которое должно быть выполнено для всех возвращаемых строк оператором SELECT. Обычно, это выражение с логическими операторами.
expr_list – содержит список выражений (или одно выражение, которое считается списком длины один) для секции (раздела) GROUP BY. Этот список действует как «ключ группировки». В результате агрегирования SELECT запрос будет содержать столько строк, сколько было уникальных значений ключа группировки в исходной таблице.
database – строка, указывающая целевую СУБД Витрины.
join_prefix – одно из выражений:
INNER;
LEFT [OUTER];
RIGHT [OUTER];
FULL [OUTER];
CROSS.
join_condition – условие объединения (равенство или неравенство). Например, table_source_1.Col1 = table_source_2.Col2, где table_source_1, table_source_2 – выражения вида [datamart].table_name_1, [datamart].table_name_2 или alias_name_1, alias_name_2.
for_system_time – выражение вида (возможен один из вариантов):
AS OF 'YYYY-MM-DD HH:MM:SS'– выборка данных, актуальных на указанную дату и время;AS OF DELTA_NUM <int>– тоже самое, но указывается не дата и время, а номер дельты;AS OF LATEST_UNCOMMITED_DELTA– выборка данных незакомиченной дельты.STARTED IN (<int1>, <int2>)– выбирает записи, которые появились или изменились начиная с дельты №1 до дельты №2 (границы включаются);FINISHED IN (<int1>, <int2>)– выбирает записи, которые были удалены начиная с дельты №1 до дельты №2 (границы включаются).
Запросы к логической схеме (INFORMATION_SCHEMA) поддерживают варианты:
INFORMATION_SCHEMA.SCHEMATA– список и описание всехdatamart;INFORMATION_SCHEMA.TABLES– список и описание всех логических таблиц всехdatamart;INFORMATION_SCHEMA.COLUMNS– список и описание мета-данных каждой логической таблицы всехdatamart;INFORMATION_SCHEMA.KEY_COLUMN_USAGE– список и описание ограничений ключевых столбцов всех логических таблиц всехdatamart;INFORMATION_SCHEMA.TABLE_CONSTRAINTS– список и описание ограничений всех логических таблиц всехdatamart.
Если FOR SYSTEM_TIME не указан, то данные выбираются актуальные на
текущий момент времени (это тоже самое что написать FOR SYSTEM_TIME AS
OF „текущая дата и время“).
Запросы к INFORMATION_SCHEMA логической схемы нельзя смешивать с
запросами к другим витринам (в одном запросе).
Если datamart или логическая таблица с таким именем не существует, то инструкция завершится с ошибкой «Entity <entity_name> does not exist.».
Если одна или несколько колонок, указанных в columns_list, не существует, то инструкция завершится с ошибкой «Column <column_name> does not exist.».
Если выражение where ссылается на нераспознанное имя колонки, то инструкция завершится с ошибкой «Column <column name> not found in any table».
Примеры использования
Пример запроса к данным:
SELECT Col1, Col2 FROM [datamart1].tbl1 FOR SYSTEM_TIME AS OF „2019-12-23 15:15:14“ JOIN [datamart2].tbl2 FOR SYSTEM_TIME AS OF „2018-07-29 23:59:59“ ON tbl1.Col3 = tbl2.Col4 WHERE tbl1.Col5 = 1 DATASOURCE_TYPE = „adb“ |
Пример запроса к мета-данным логической схемы данных:
SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = „datamart1“ |
Пример запроса к данным горячей дельты:
SELECT * FROM [datamart1].table1 FOR SYSTEM_TIME AS OF LATEST_UNCOMMITED_DELTA |
5.5.5.17. CREATE DOWNLOAD EXTERNAL TABLE
Инструкция создает внешнюю таблицу для Массивно-параллельного чтения данных из Витрины в Kafka.
CREATE DOWNLOAD EXTERNAL TABLE [datamart].table_name_ext (column1 datatype1, column2 datatype2, …) LOCATION „kafk a://zkhost1:port1,zkhost2:port2,zkhost3:port3/chroot/path/topicname“ | „kafka://$kafka/<topic>“ | „file://file_host:port/path/file“ | „hdfs://hdfs_host:port/path/file“ FORMAT „AVRO“ | „СSV“ | „TEXT“ [CHUNK_SIZE recordsPerMessage] |
table_name_ext – имя внешней таблицы.
В разделе LOCATION указывается строка URI внешнего приемника данных.
В разделе FORMAT указывается строка, указывающая формат выгрузки.
recordsPerMessage – целое число, указывающее предельное количество выгружаемых записей в одном блоке.
Если datamart с таким именем не существует, то инструкция завершится с ошибкой «Database <datamart> does not exist.».
Если внешняя таблица с таким именем уже существует, то инструкция завершится с ошибкой «Entity <entity_name> already exists.».
Проверка доступности URI, указанного в разделе LOCATION, при выполнении этой инструкции не производится, но в процессе выполнении чтения, если URI недоступен, возникает ошибка «Location <URI> is unreachable.».
5.5.5.18. DROP DOWNLOAD EXTERNAL TABLE
Инструкция удаляет внешнюю таблицу для Массивно-параллельного чтения данных из Витрины в Kafka.
DROP DOWNLOAD EXTERNAL TABLE [datamart].table_name_ext |
table_name_ext – имя внешней таблицы.
Если datamart или логическая таблица с таким именем не существует, то инструкция завершится с ошибкой «Entity <entity_name> does not exist.».
5.5.5.19. CREATE UPLOAD EXTERNAL TABLE
Инструкция создает внешнюю таблицу для Массивно-параллельной записи данных в Витрину из Kafka.
CREATE UPLOAD EXTERNAL TABLE [datamart].table_name_ext (column1 datatype1, column2 datatype2, …) LOCATION „kafk a://zkhost1:port1,zkhost2:port2,zkhost3:port3/chroot/path/topicname“ | „kafka://$kafka/<topic>“ | „file://<file_host>:<port>/<path>/<file>“ | „file://$file/<path>/<file>“ | „hdfs://<hdfs_host>:<port>/<path>/<file>“ | „hdfs://$hdfs/<path>/<file>“ FORMAT „AVRO“ | „СSV“ | „TEXT“ [MESSAGE_LIMIT messagesPerSegment] |
table_name_ext – имя внешней таблицы.
В разделе LOCATION указывается строка URI внешнего источника данных.
В разделе FORMAT указывается строка, указывающая формат данных внешнего источника.
messagesPerSegment – целое число, указывающее предельное количество загружаемых записей в одном блоке.
Если datamart с таким именем не существует, то инструкция завершится с ошибкой «Database <datamart> does not exist.».
Если внешняя таблица с таким именем уже существует, то инструкция завершится с ошибкой «Entity <entity_name> already exists.».
Проверка доступности URI, указанного в разделе LOCATION, при выполнении этой инструкции не производится, но в процессе выполнении записи, если URI недоступен, возникает ошибка «Location <URI> is unreachable.».
5.5.5.20. DROP UPLOAD EXTERNAL TABLE
DROP UPLOAD EXTERNAL TABLE [datamart].table_name_ext |
table_name_ext – имя внешней таблицы.
Если datamart или логическая таблица с таким именем не существует, то инструкция завершится с ошибкой «Entity <entity_name> does not exist.».
5.5.5.21. UPLOAD
Инструкция записывает данные (Массивно-параллельная запись) в логическую таблицу Витрины из источника, связанного со внешней таблицей.
INSERT INTO [datamart].table_name SELECT columns_list FROM [datamart].table_name_ext |
table_name_ext – имя внешней таблицы загрузки.
table_name – имя логической таблицы Витрины.
columns_list – список столбцов (имена разделены символом «запятая» или используйте символ «*»). Список столбцов должен быть равен и упорядочен так же, как имена столбцов внешней таблицы загрузки и соответствующего топика Kafka.
Если datamart или логическая таблица с таким именем не существует, то инструкция завершится с ошибкой «Entity <entity_name> does not exist.».
Если отсутствует хоть один столбец, указанный в списке столбцов columns_list, то инструкция завершится с ошибкой «Column <column_name> does not exist.».
5.5.5.22. DOWNLOAD
Инструкция записывает данные (Массивно-параллельная чтение), отобранные инструкцией SELECT, в приемник, связанный со внешней таблицей.
INSERT INTO [datamart].table_name_ext sql_dml_select_expression |
table_name_ext – имя внешней таблицы чтения.
sql_dml_select_expression – подзапрос (инструкция SELECT).
Если указанные в подзапросе SELECT datamart или логическая таблица с таким именем не существует, то инструкция завершится с ошибкой «Entity <entity_name> does not exist.».
Если отсутствует хоть один столбец, указанный в списке столбцов columns_list подзапроса SELECT, то инструкция завершится с ошибкой «Column <column_name> does not exist.».
5.5.5.23. CHECK_DATABASE
Инструкция проверяет целостность логической схемы и физических схем всех логических таблиц в указанной Витрине, выполняя для каждой логической таблицы инструкцию CHECK_TABLE.
CHECK_DATABASE(<datamart>) CHECK_DATABASE() CHECK_DATABASE |
datamart – имя datamart, которому принадлежат логические таблица. Если datamart не указан, то проверяется текущий datamart.
Если datamart с таким именем не существует, то инструкция завершится с ошибкой «Database <datamart> does not exist.».
5.5.5.24. CHECK_TABLE
Инструкция проверяет целостность логической таблицы и связанных с ней физических таблиц.
CHECK_TABLE(<table_name>) |
table_name_ext – имя логической таблицы.
Если логическая таблица с таким именем не существует, то инструкция завершится с ошибкой «Entity <entity_name> does not exist.».
5.5.5.25. CHECK_DATA
Инструкция проверяет консистентность записей в физических таблицах хранилища Витрины.
CHECK_DATA(<logicTableName>, <deltaNum>, [<columns_list>]) |
logicTableName – имя логической таблицы.
deltaNum – минимальный номер дельты, которая будет проверяться: [ delta .. delta_ok ].
columns_list – опциональный параметр. Список проверяемых колонок, разделенный запятыми и заключенный в квадратные скобки. Пример: [col1, col2, col3]. Если не указан, то выполняется 1-й тип проверки.
Инструкция поддерживает типы проверки:
На основании сравнения количества записей, относящихся к каждой из операций записи отдельно (каждой операции обновления данных в datamart присваивается уникальный 64-битный номер, который сохраняется в каждой записи, обновляемой в рамках этой операции).
На основании расчета хеш-функции для указанных полей.
Ограничения:
В одной операции проверки не может быть проверено более 4’294’967’298 записей.
5.5.5.26. CONFIG_STORAGE_ADD
Инструкция добавляет новую СУБД в хранилище Витрины.
CONFIG_STORAGE_ADD(„<db>“) |
db – одна из аббревиатур (adb, adg, adqm).